由颜水成老师带领的 Sea AI Lab 提出了一种多粒度自监督学习框架 Mugs[1],用以学习不同粒度的非监督特征,从而满足不同下游任务对不同粒度甚至多粒度特征的需求。在相同的实验设置下(相同数据集和模型等),该方法大幅超越了目前最好的自监督学习方法。在没有使用额外数据的情况下,该方法在 ImageNet 数据集上取得了目前最高的线性评估准确率(linear probing accuracy)82.1% 以及最高的 KNN 分类准确率 80.3%。
详细结果请参看 paperswithcode 的Leaderboard:https://paperswithcode.com/sota/self-supervised-image-classification-on?p=mugs-a-multi-granular-self-supervised
通过精心设计上游任务(pretext task),自监督学习从这些上游任务上直接拿到无监督数据的伪标签,并且利用这些伪标签训练深度学习模型。实验结果表明通过自监督学习到的特征在很多下游任务上展现出比常规监督学习更强的迁移性能和泛化性能。目前大量的无标签数据可以在互联网上获得,自监督学习已经展示出比常规监督学习更大的潜能。
在自监督学习中,许多下游任务其实需要不同粒度的特征,例如粗粒的特征或者细粒度的特征。举例来说,常规的分类问题一般会用更多的粗粒度特征,而细粒度的分类问题则需要更多的细粒度特征。更重要的是,在实际应用中,许多下游任务需要多粒度的特征来处理数据中的复杂结构。一个典型的例子是 ImageNet 上的分类问题。首先,注意到 ImageNet 数据非常贴近实际数据,拥有类别上的层级结构,也就是很多小类拥有相似的属性从属于一个大类(例如犬科类里面包含很多不同品种的狗和狼)。这样一来,为了区分不同的大类别,例如犬科类和鸟类,我们就需要粗粒度的特征。为了进一步区分更细的类别,譬如狗和狼,我们则需要稍微细粒度一点的特征。最后为了细分不同品种的狗,我们需要更加细粒度的特征。许多其他应用,例如物体检测与识别,也面临着类似的多粒度特征需求。
然而,现在的自监督学习方法一般都只侧重于单粒度特征的学习。譬如,最经典的对比学习 MoCo[2] 构建实例识别任务来区分单个实例。这样一来,MoCo 侧重学习更多实例级的细粒度特征,但是它不考虑数据中粗粒度的类别结构(cluster structure)。另外一类具有代表性的自监督学习是基于聚类的自监督学习,包含 DINO[3],DeepCluster[4]等。这类方法将类似的实例聚到同一个虚拟类别中,从而学习聚类级别的粗粒度特性。然而,它不能很好地处理对细粒度特性有所需求的下游任务。因此,在下游任务的特征偏好未知的情况下,我们应该构建一个学习多粒度特征的自监督学习框架,以便尽可能多地处理不同下游任务。
为了解决上述问题,该研究提出了一种多粒度自监督学习 (Mugs) 框架来显示地学习视觉数据的多粒度特征。具体来说,Mugs 主要学习三种不同粒度特征:
第一是 instance-level(实例级别的)细粒度特征,用于将不同的实例区分开;
第二是稍微粗粒度的 local-group 数据特征。这类特征主要是为了保证非常相似的样本能够聚集成小簇,从而形成一个 local-group 上的整体语义(例如对应到非常相似的狗)。这样一来,local-group 特征则会将第一类过于分散的实例特征进行高阶语义的重新聚集,也就让相似的样本享有相似的特征;
第三类是数据中更加粗粒度的 group 特征(例如犬科特征)。这类特征是保证相似的 local-groups 能够靠的更近,从而保证数据整体语义的一致性。通过这样的层级数据语义学习,该方法能够学到更贴合实际应用的特征,从而更加满足于不同下游任务对不同粒度特征的需求。
![]()
如前面所述,该方法主要通过三种不同粒度的监督来学习三种不同粒度的特征, 包含 1) instance-level 细粒度特征,2)稍微粗粒度的 local-group 特征, 3)粗粒度的 group 特征。下面将介绍这三种特征的具体学习方法。
![]()
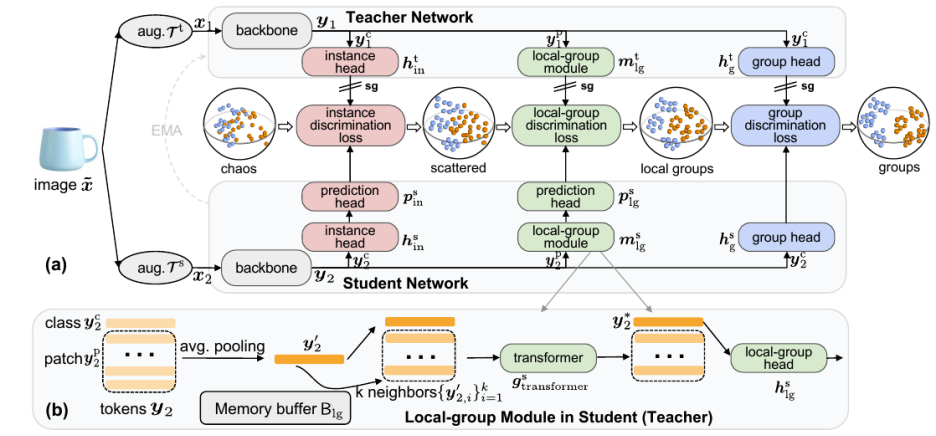
图一:Mugs 自监督学习整体框架。(a)展示了总体框架。对于每幅图像,Mugs 将两次随机增强的样本输入学生和教师骨干网络。然后, Mugs 采用三种不同粒度的监督 / 损失: 1)instance discrimination loss, 2)local-group discrimination loss,3) group discrimination loss。(b)展示了学生和老师中都有的 local-group discrimination 模块。这个模块首先平均所有 patch tokens 得到 average token,并从一个 buffer 里面找到当前 average token 的 top-k 邻居。然后,它使用一个小的 transformer 来聚合 average token 和它的 k 个邻居,从而获得一个 local group feature(即新的 class token)。
A). instance-level 细粒度特征学习
和对比学习 MoCo 一样,Mugs 通过 instance discrimination supervision(实例判别监督)来分散不同的实例特征,从而监督实例级别的细粒度特征学习。
具体来说,给定样本
![]() , Mugs 进行两次数据增强得到
, Mugs 进行两次数据增强得到
![]() , 然后分别送进老师和学生 backbone 得到
, 然后分别送进老师和学生 backbone 得到
![]() 。
接着 Mugs 把
。
接着 Mugs 把
![]() 里面的 class token
里面的 class token
![]() 分别送入对应的投影网络
分别送入对应的投影网络
![]() 。
最后,Mugs 将学生网络对应的输出进一步输入到一个预测网络
。
最后,Mugs 将学生网络对应的输出进一步输入到一个预测网络
![]() 用来预测老师的输出。
为了达到让老师和学生输出一致的目的,Mugs 使用 infoNCE 损失函数来实现:
用来预测老师的输出。
为了达到让老师和学生输出一致的目的,Mugs 使用 infoNCE 损失函数来实现:
![]()
其中,
![]() 分别对应老师和学生分支最后的输出。
分别对应老师和学生分支最后的输出。
![]() 代表的是一个缓存 buffer,用于存贮过往的
代表的是一个缓存 buffer,用于存贮过往的
![]() 。
这样一来,正如图一中的效果图所示,Mugs 把同一个图片对应的特征
。
这样一来,正如图一中的效果图所示,Mugs 把同一个图片对应的特征
![]() 拉进,把不同图片的特征推远,从而分散开 instance-level 的特
征。
B). 稍微粗粒度的 local-group 特征学习
如前所述,细粒度特征通常不足以满足不同的下游任务(例如分类),因为缺乏足够的高级数据语义。为了学习更高级别的细粒度(即稍微粗粒度)特征,这里也称为 local-group feature,Mugs 提出了一种新颖而有效的 local-group supervision。直观地讲,如图一中第三个球面所示,这种监督鼓励数据特征具有小但分散的 local-group 结构。目的是保证高度相似的样本能够在特征空间上聚集,避免前面所介绍的 instance discrimination supervision 将相似的样本推得过远,从而避免破坏一定的语义。这样一来,local-group supervision 有助于捕获数据中的更高级别语义。接下来将首先介绍其细节,然后更加详细地讨论它的好处。
给定两个数据增广后的样本
拉进,把不同图片的特征推远,从而分散开 instance-level 的特
征。
B). 稍微粗粒度的 local-group 特征学习
如前所述,细粒度特征通常不足以满足不同的下游任务(例如分类),因为缺乏足够的高级数据语义。为了学习更高级别的细粒度(即稍微粗粒度)特征,这里也称为 local-group feature,Mugs 提出了一种新颖而有效的 local-group supervision。直观地讲,如图一中第三个球面所示,这种监督鼓励数据特征具有小但分散的 local-group 结构。目的是保证高度相似的样本能够在特征空间上聚集,避免前面所介绍的 instance discrimination supervision 将相似的样本推得过远,从而避免破坏一定的语义。这样一来,local-group supervision 有助于捕获数据中的更高级别语义。接下来将首先介绍其细节,然后更加详细地讨论它的好处。
给定两个数据增广后的样本
![]() , 假设老师和学生骨干网络得到
, 假设老师和学生骨干网络得到
![]() 。
如图一中的子图(b)所示,Mugs 把
。
如图一中的子图(b)所示,Mugs 把
![]() 里面的 patch tokens
里面的 patch tokens
![]() 分别进行平均池化得到
分别进行平均池化得到
![]() 。
在另一方面,Mugs 使用一个 buffer
。
在另一方面,Mugs 使用一个 buffer
![]() 以先进先出的方式来保存过往的
以先进先出的方式来保存过往的
![]() 。
接着,Mugs 分别为当前的
。
接着,Mugs 分别为当前的
![]() 里面找到它们对应的 top-k 邻居
里面找到它们对应的 top-k 邻居
![]() 。
然后,Mugs 借助一个小的 transformer 将
。
然后,Mugs 借助一个小的 transformer 将
![]() 融合成一个 local-group feature:
融合成一个 local-group feature:
![]()
其中,
![]() 代表的是一个两层的 transformer:
它的 input class token 是
代表的是一个两层的 transformer:
它的 input class token 是
![]() ,input patch tokens 是
,input patch tokens 是
![]() ,输出 class token
,输出 class token
![]() 。
。
![]() 有着同样的功能。
因为
有着同样的功能。
因为
![]() 和它的 top-k 邻居
和它的 top-k 邻居
![]() 很相似,它们一起组成一个 local-group。
因此,它们的融合
很相似,它们一起组成一个 local-group。
因此,它们的融合
![]() 也被称为
也被称为
![]() 的 local-group feature。
最后 Mugs 拉进同一张图片的两个数据增强的 local-group feature
的 local-group feature。
最后 Mugs 拉进同一张图片的两个数据增强的 local-group feature
![]() ,并且推远不同图片的 local-group feature:
,并且推远不同图片的 local-group feature:
![]()
其中,
![]() 分别对应老师和学生的投影网络。
分别对应老师和学生的投影网络。
![]() 代表学生网络的预测网络,
代表学生网络的预测网络,
![]() 代表一个缓存 buffer,用于存贮过往的
代表一个缓存 buffer,用于存贮过往的
![]() 。
这样一来,正如图
一中的第三个球面特征效果图所示,Mugs 将分散的特征聚集为小的聚类中心,从而
学习到稍微粗粒度的 local-group 特征。
这种 local-group discrimination supervision 给 Mugs 带来两方面的好处。
。
这样一来,正如图
一中的第三个球面特征效果图所示,Mugs 将分散的特征聚集为小的聚类中心,从而
学习到稍微粗粒度的 local-group 特征。
这种 local-group discrimination supervision 给 Mugs 带来两方面的好处。
它是上述 instance discrimination supervision 的有效补充。针对同一张图片的两个数据增强后的样本,这种监督要求这两个样本的 local-group 相同。这意味着除了样本本身对齐之外,它们对应的邻居也应该很好地对齐。这种邻居对齐一个更具挑战性的对齐问题,也增强了更高级别的 local-group 语义对齐。
这种监督鼓励高度相似的样本形成 local-group,并将不同的 local-groups 分散开来,从而提高了特征的语义判别能力。这是因为 a)这种监督所寻求的邻居数目 k 非常小(大约 10),这样在同一 local-group 的样本高度相似,有助于形成非常紧凑的 local-group; b)这种监督进一步将不同的 local-groups 分开。通过这两个方面,这种 local-group 通过考虑数据中的 local-group 结构,促进了更高级别的细粒度特征学习,有效地补充了 instance discrimination supervision。
为了避免了上述相似的 local-group 分散的过于随机或较远,Mugs 中的 group discrimination supervision 将类似的样本聚集在一起,从而拉近类似的 local-group。这样一来,Mugs 可以在更高语义级别上捕获粗粒度特征。
具体来说,如图一所示,给定
![]() , 老师和学生 backbone 分别输出
, 老师和学生 backbone 分别输出
![]() 。
接着 Mugs 把
。
接着 Mugs 把
![]() 里面的 class token
里面的 class token
![]() 分别送进对应的投影网络
分别送进对应的投影网络
![]() 。
然后,Mugs 构建了一系列的可学习聚类中心
。
然后,Mugs 构建了一系列的可学习聚类中心
![]() 来在线计算伪聚类标签:
来在线计算伪聚类标签:
![]()
其中,
![]() 函数是对它的输入进行 sharpening 操作。
接下来,类似于监督分类任务,Mugs 使用交叉熵损失,但使用软标签作为训练损失:
函数是对它的输入进行 sharpening 操作。
接下来,类似于监督分类任务,Mugs 使用交叉熵损失,但使用软标签作为训练损失:
![]()
最后,该方法将上述三种互补的监督损失函数融合从而形成一个整体的训练损失函数:
![]()
其中,超参数
![]() 分别代表三种监督权重。
在实验中,为了方便,三个超参数都设置为 1/3。
现在讨论这三个监督对特征学习的共同影响。这也将它与现有的粒度特征学习方法,例如 MoCo 和 DINO ,区分开来。如前所述,instance discrimination supervision 就是拉近同一图像的不同增广的样本,从而将不同图像的特征近似地分散 在球面上(如图一第二个球面所示)。它帮助 Mugs 学习 instance-level 的细粒度特征。其次,local-group discrimination supervision 为 instance discrimination supervision 提供补充性监督。它考虑一张图片的 local-group,并鼓励同一张图片的不同增广样本拥有高度相似的邻居。这样一来,local-group supervision 则会将 instance discrimination supervision 中过于分散的实例特征进行高阶语义的重新聚集,也就让相似的样本享有相似的特征。最后,为了避免了上述相似的 local-group 分散的过于随机或较远,Mugs 中的 group discrimination supervision 将类似的样本聚集在一起,从而拉近类似的 local-group。这样一来,Mugs 可以在更高语义级别上捕获粗粒度特征。通过这样互补的多粒度监督学习,Mugs 能够学到更贴合实际应用的特征,从而更加满足于不同下游任务对不同粒度特征的需求。
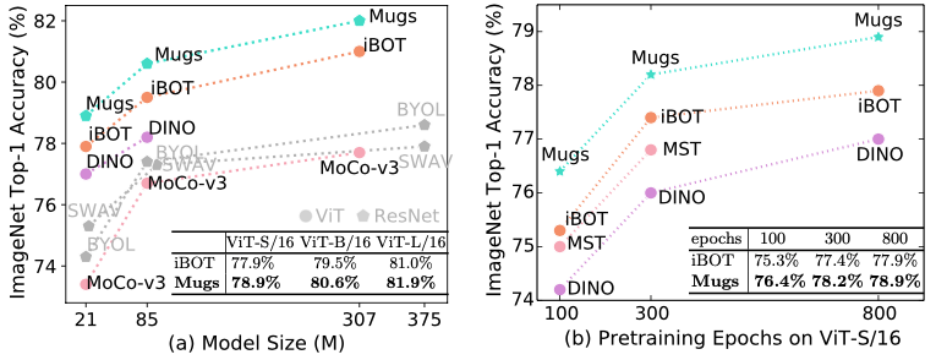
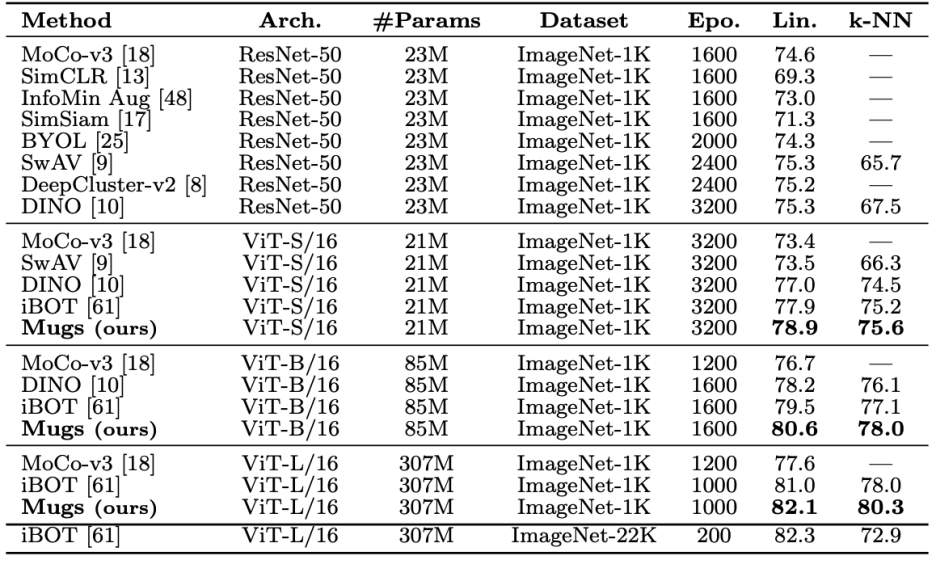
Mugs 使用和其他自监督方法同样的数据集和评测方法来验证它的效果。因为 transformer 展现出比 CNN 更强大的潜能(相同规模,transformer 效果会更优,并且它也拥有一统 CV 和 NLP 的潜能),Mugs 同样主要用 transformer 架构来验证。Mugs 仅在 ImageNet 1K 的训练集上预训练,然后在 ImageNet 1K 的训练集上进行 Linear Probing 和 KNN 训练。在这两种最常见的设置下,Mugs 大幅超越已有方法。在没有额外数据训练情况下,Mugs 超过了同样设置下的最好方法 iBoT,从而取得了最新的 SOTA linear probing 精度 82.1%。另外,在 KNN 设置下,Mugs 甚至超越了 ImageNet 1K 和 ImageNet22K 训练的最好方法 iBOT,从而刷新了 KNN 下的 SoTA。具体实验结果可以参看图二和图三。
分别代表三种监督权重。
在实验中,为了方便,三个超参数都设置为 1/3。
现在讨论这三个监督对特征学习的共同影响。这也将它与现有的粒度特征学习方法,例如 MoCo 和 DINO ,区分开来。如前所述,instance discrimination supervision 就是拉近同一图像的不同增广的样本,从而将不同图像的特征近似地分散 在球面上(如图一第二个球面所示)。它帮助 Mugs 学习 instance-level 的细粒度特征。其次,local-group discrimination supervision 为 instance discrimination supervision 提供补充性监督。它考虑一张图片的 local-group,并鼓励同一张图片的不同增广样本拥有高度相似的邻居。这样一来,local-group supervision 则会将 instance discrimination supervision 中过于分散的实例特征进行高阶语义的重新聚集,也就让相似的样本享有相似的特征。最后,为了避免了上述相似的 local-group 分散的过于随机或较远,Mugs 中的 group discrimination supervision 将类似的样本聚集在一起,从而拉近类似的 local-group。这样一来,Mugs 可以在更高语义级别上捕获粗粒度特征。通过这样互补的多粒度监督学习,Mugs 能够学到更贴合实际应用的特征,从而更加满足于不同下游任务对不同粒度特征的需求。
Mugs 使用和其他自监督方法同样的数据集和评测方法来验证它的效果。因为 transformer 展现出比 CNN 更强大的潜能(相同规模,transformer 效果会更优,并且它也拥有一统 CV 和 NLP 的潜能),Mugs 同样主要用 transformer 架构来验证。Mugs 仅在 ImageNet 1K 的训练集上预训练,然后在 ImageNet 1K 的训练集上进行 Linear Probing 和 KNN 训练。在这两种最常见的设置下,Mugs 大幅超越已有方法。在没有额外数据训练情况下,Mugs 超过了同样设置下的最好方法 iBoT,从而取得了最新的 SOTA linear probing 精度 82.1%。另外,在 KNN 设置下,Mugs 甚至超越了 ImageNet 1K 和 ImageNet22K 训练的最好方法 iBOT,从而刷新了 KNN 下的 SoTA。具体实验结果可以参看图二和图三。
![]()
图二:在 ImageNet-1K 预训练设置下,各种自监督方法的 Linear Probing 精度对比。通过在 ImageNet-1K 上进行预训练,在不同的模型尺寸 (见(a)) 和预训练时间 (见(b)) 下,Mugs 大幅的提高了之前的 SoTA (iBOT)。
![]()
图三:在 ImageNet-1K 上 Linear Probing 和 KNN 的精度对比。
另外,在其他的设置下,包括微调网络,半监督学习,迁移学习,物体检测,实例分割,语义分割,视频语义分割等 7 项任务上,Mugs 也超越了同样设置下的 SoTA 方法。具体可参看原文。
最后 Mugs 还展示了一些注意力可视化效果图。从图四可以看出,在没有标签的情况下,Mugs 仍然学到了语义信息。譬如 Mugs 能够很好地检测到物体的形状以及位置。
![]()
图四:Mugs 预训练的 ViT-Base/16 上的自注意力可视化
Mugs 还使用 T-SNE 揭示 MoCo-v3、DINO、iBOT 和 Mugs 所学习到的特征之间的差异。在图五中,每种颜色代表一个独特的类。通过对比,针对一个类,Mugs 经常在特征空间中将其划分为几个小簇,例如棕色的 6 个簇,紫色的 4 个簇,红色的 6 个簇,蓝色的 5 个簇,然后将这些小簇分散在一个大的类中。这些结果揭示了该特征中的多粒度结构: 分散的大类(即不同的颜色)对应于粗粒度特征,一个类中几个分散的小簇显示了更小的粗粒度(稍微高级的细粒度); 每一个小簇中的一些单独实例显示了实例级的细粒度。相比之下,MoCo-v3、DINO 和 iBOT 通常不显示这种多粒度特征结构。正如前文所述,不同下游任务通常需要不同粒度特征甚至多粒度特征。因此,这些可视化也能帮助解释为什么 Mugs 能够超越单粒度特征学习方法。
![]()
图五:各种自监督学习预训练的 ViT-Base/16 上的 T-SNE 可视化 T-SNE。
[1] Zhou, P., and Zhou, Y., and Si, C., and Yu, W., and Ng, T., and Yan, S., : Mugs: A Multi-Granular Self-Supervised Learning Framework. arXiv preprint arXiv: 2203.14415 (2022)
[2] Chen, X., Xie, S., He, K.: An empirical study of training self-supervised vision transformers. arXiv preprint arXiv:2104.02057 (2021)
[3] Caron, M., Touvron, H., Misra, I., J ́egou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294 (2021)
[4] Caron, M., Bojanowski, P., Joulin, A., Douze, M.: Deep clustering for unsupervised learning of visual features. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 132–149 (2018)
[5] Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: iBOT: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832 (2021)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

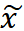 , Mugs 进行两次数据增强得到
, Mugs 进行两次数据增强得到
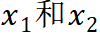 , 然后分别送进老师和学生 backbone 得到
, 然后分别送进老师和学生 backbone 得到
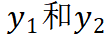 。
接着 Mugs 把
。
接着 Mugs 把
 分别送入对应的投影网络
分别送入对应的投影网络
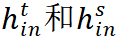 。
最后,Mugs 将学生网络对应的输出进一步输入到一个预测网络
。
最后,Mugs 将学生网络对应的输出进一步输入到一个预测网络
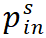 用来预测老师的输出。
为了达到让老师和学生输出一致的目的,Mugs 使用 infoNCE 损失函数来实现:
用来预测老师的输出。
为了达到让老师和学生输出一致的目的,Mugs 使用 infoNCE 损失函数来实现:
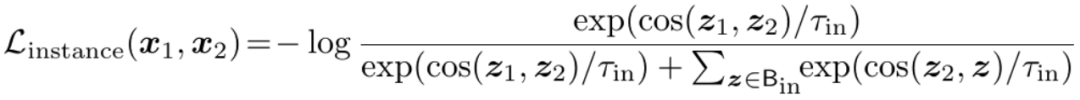
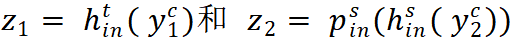 分别对应老师和学生分支最后的输出。
分别对应老师和学生分支最后的输出。
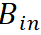 代表的是一个缓存 buffer,用于存贮过往的
代表的是一个缓存 buffer,用于存贮过往的
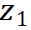 。
这样一来,正如图一中的效果图所示,Mugs 把同一个图片对应的特征
。
这样一来,正如图一中的效果图所示,Mugs 把同一个图片对应的特征
 拉进,把不同图片的特征推远,从而分散开 instance-level 的特
征。
拉进,把不同图片的特征推远,从而分散开 instance-level 的特
征。
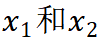 , 假设老师和学生骨干网络得到
, 假设老师和学生骨干网络得到
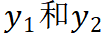 。
如图一中的子图(b)所示,Mugs 把
。
如图一中的子图(b)所示,Mugs 把
 分别进行平均池化得到
分别进行平均池化得到
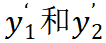 。
在另一方面,Mugs 使用一个 buffer
。
在另一方面,Mugs 使用一个 buffer
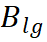 以先进先出的方式来保存过往的
以先进先出的方式来保存过往的
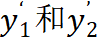 。
接着,Mugs 分别为当前的
。
接着,Mugs 分别为当前的
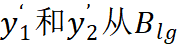 里面找到它们对应的 top-k 邻居
里面找到它们对应的 top-k 邻居
 。
然后,Mugs 借助一个小的 transformer 将
。
然后,Mugs 借助一个小的 transformer 将
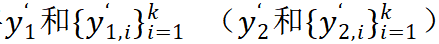 融合成一个 local-group feature:
融合成一个 local-group feature:
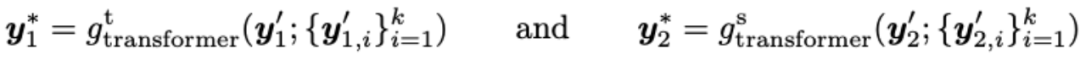
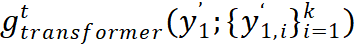 代表的是一个两层的 transformer:
它的 input class token 是
代表的是一个两层的 transformer:
它的 input class token 是
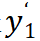 ,input patch tokens 是
,input patch tokens 是
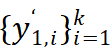 ,输出 class token
,输出 class token
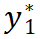 。
。
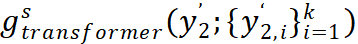 有着同样的功能。
因为
有着同样的功能。
因为
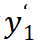 和它的 top-k 邻居
和它的 top-k 邻居
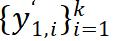 很相似,它们一起组成一个 local-group。
因此,它们的融合
很相似,它们一起组成一个 local-group。
因此,它们的融合
 也被称为
也被称为
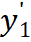 的 local-group feature。
最后 Mugs 拉进同一张图片的两个数据增强的 local-group feature
的 local-group feature。
最后 Mugs 拉进同一张图片的两个数据增强的 local-group feature
 ,并且推远不同图片的 local-group feature:
,并且推远不同图片的 local-group feature:
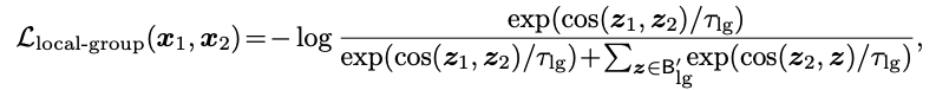
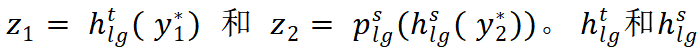 分别对应老师和学生的投影网络。
分别对应老师和学生的投影网络。
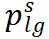 代表学生网络的预测网络,
代表学生网络的预测网络,
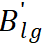 代表一个缓存 buffer,用于存贮过往的
代表一个缓存 buffer,用于存贮过往的
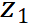 。
这样一来,正如图
一中的第三个球面特征效果图所示,Mugs 将分散的特征聚集为小的聚类中心,从而
学习到稍微粗粒度的 local-group 特征。
。
这样一来,正如图
一中的第三个球面特征效果图所示,Mugs 将分散的特征聚集为小的聚类中心,从而
学习到稍微粗粒度的 local-group 特征。
 , 老师和学生 backbone 分别输出
, 老师和学生 backbone 分别输出
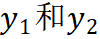 。
接着 Mugs 把
。
接着 Mugs 把
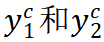 分别送进对应的投影网络
分别送进对应的投影网络
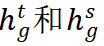 。
然后,Mugs 构建了一系列的可学习聚类中心
。
然后,Mugs 构建了一系列的可学习聚类中心
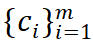 来在线计算伪聚类标签:
来在线计算伪聚类标签:
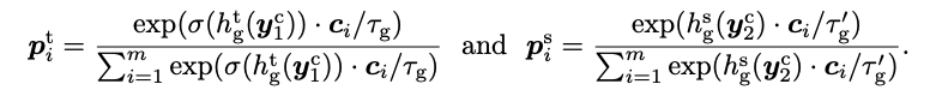
 函数是对它的输入进行 sharpening 操作。
接下来,类似于监督分类任务,Mugs 使用交叉熵损失,但使用软标签作为训练损失:
函数是对它的输入进行 sharpening 操作。
接下来,类似于监督分类任务,Mugs 使用交叉熵损失,但使用软标签作为训练损失:
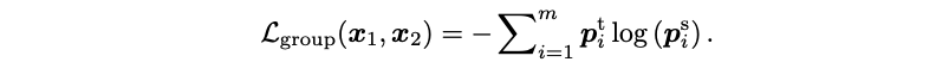
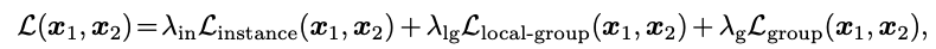
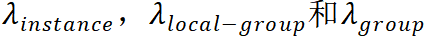 分别代表三种监督权重。
在实验中,为了方便,三个超参数都设置为 1/3。
分别代表三种监督权重。
在实验中,为了方便,三个超参数都设置为 1/3。