NeurIPS'21 | 面向开放世界特征的图学习
推荐一波EverGlow老哥的Towards Open-World Feature Extrapolation: An Inductive Graph Learning Approach,其探索了神经网络如何处理测试阶段出现的新特征(值)?——面向开放世界特征外推的图学习解决方案
链接:https://www.zhihu.com/question/490938685/answer/2272624746
动机:特征外推问题的定义与重要性
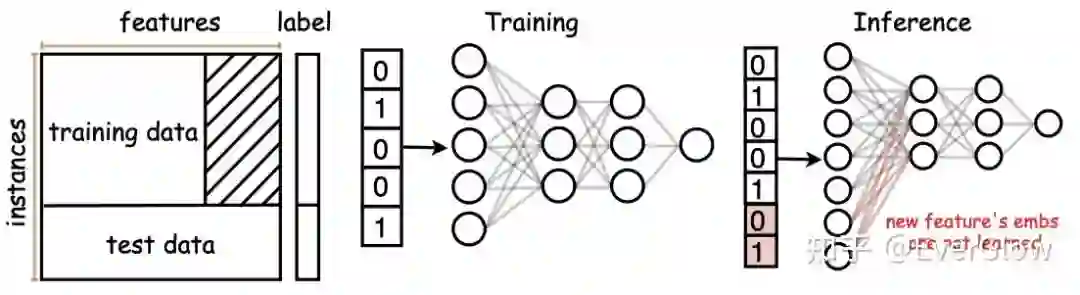
目前的大多数机器学习任务,通常假设训练数据与测试数据共享一个特征空间。然而在实际场景中,训练好的模型通常需要与一个开放环境进行交互,测试集中就会出现新的特征。例如推荐系统中利用用户的年龄、职业等特征训练好了一个推荐模型,后来公司新发布了某个应用,收集到了新的用户数据,这就需要用新的用户特征进行决策。下图给出了一个直观的说明,我们考虑训练数据与测试数据的特征维度不一致(后者是前者的扩张),在这种情况下如果我们把训练好的神经网络直接迁移到测试集,由于对应新特征维度的神经元未经过训练,网络的测试性能就会大大下降,而重新在包含新特征的数据集上训练一个神经网络又需要耗费大量的计算资源。
本篇论文中,我们提出了一种新的学习方法,基于特征与样本之间的关系所形成的图结构,利用已知的特征表示(embedding)来外推新特征的表示,模型无需重新训练就能泛化到包含新特征的数据上。
我们把第 个数据样本表示为 ,其中 表示第 个特征的 one-hot表示向量 (离散特征的常见表示形式,连续特征可先做离散化再表示成one-hot向量), 这里共有 个特征。下面为开放世界特征外推问题 (open-world feature extrapolation) 给出 数学定义:
给定训练数据 其中 ,我们需要训练一 个分类器a 使得它能够泛化到测试数据 其中 。注意到,这里我们暇设 1 训练集特征空间包含于测试 集特征空间,即 。
重要观察
直接解决上述问题是很困难的,因为训练阶段对测试数据中额外增加的特征信息一无所知(包括特征的数目和分布都不可见)。不过我们有两点重要观察,可以引导我们给出一个合理的解决方案。

其次,如果我们把所有输入的数据(比如训练样本)堆叠起来,形成一个矩阵(维度为样本数 特征数),它定义了一个样本-特征的二分图。图中每个样本与每个特征都是节点,连边是样本对特征的隶属关系(即该样本是否包含该特征)。
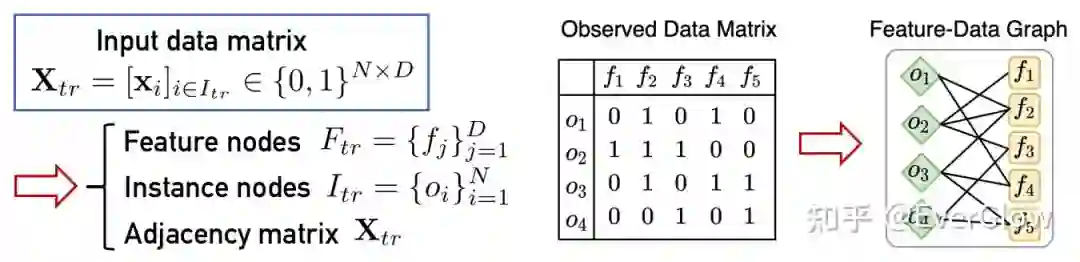
联合以上两点我们可以发现,如果我们把所有输入数据(或一个batch的数据)视为一张图,再输入神经网络,由于网络embedding层的置换不变性,不论输入的图包含多少特征节点,网络都能灵活处理。这就说明我们能够适当改造神经网络,使它能够处理特征空间的扩张。
方法
下面介绍本文提出的用于特征外推的模型框架(下图显示了模型的前馈过程)。整个模型框架包含输入的数据表示,一个high-level的GNN模型,和一个low-level的backbone模型。GNN模型用于在样本-特征二分图上进行消息传递,通过抽象的信息聚合来推断新特征的embedding。这一过程模拟了人脑的思考过程,即从熟悉的知识概念外推出对新概念的理解。backbone模型就是一个普通的分类器,不过embedding层的参数将由GNN模型的输出替代。

下图是针对上述模型提出的两种训练策略。图(a)中我们采用self-supervised训练,每次将部分特征mask,然后利用其他特征来推断mask的特征。图(b)中我们采用inductive训练方式,每次采样一部分训练集的特征,只利用这部分特征来给出预测结果。此外,GNN和backbone采用异步更新,即每k轮更新backbone后再更新一次GNN。

理论分析
我们对提出的训练方法做了一番理论分析,主要考虑经验风险损失(即部分观测集上的模型预测误差)与期望风险损失(即整体数据分布上的模型预测误差)关于算法随机性的期望差值。这一差值能upper bound由以下定理给出, 结论就是泛化误差上界主要与输入特征维度 以及采样算法可 能产生的特征组合数目 有关。

实验结果
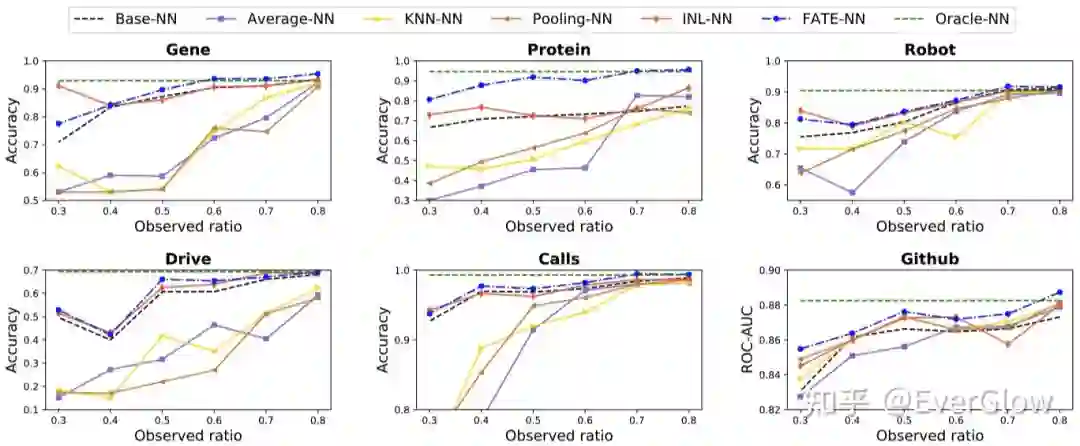
在多/二分类数据集上,我们考虑如下评测准则:随机将数据样本划分为 的train/val/test集,再随机从所有特征中选出部分观测特征;模型在只有观测特征的训练数据上训练,在具有所有特征的测试数据上计算accuracy(多分类)或ROC-AUC(二分类)。对比以下方法:1)Base-NN只用观测特征训练和测试;2)Oracle-NN:使用全部特征训练和测试;3)Average-NN/KNN-NN/Pooling-NN:使用average pooling聚合所有特征embedding/KNN聚合相近特征embedding/不含参数的mean pooling GCN聚合相邻特征embedding来推断新特征的embedding;4)INL-NN先在仅有观测特征的训练数据上训练到饱和再在新特征上局部更新。在6个小数据集上,考虑不同的观测特征比例(从30%到80%),对比结果如下。
未来展望与总结
我们工作的最大贡献在于定义了一个全新的问题框架,即特征空间的扩张问题,并且说明了神经网络模型可以胜任此类任务,解决测试阶段新出现的特征。这一问题和解决思路可以拓展到诸多其他领域和场景,包括但不限于:
-
1)连续学习(Continual Learning)中不断到来的新特征; -
2)多模态学习(Multi-Modal Learning)或多视角学习(Multi-View Learning)中融合多方数据的表示; -
3)联邦学习(Federated Learning)中中心服务器需要处理分布式节点的新特征。
欢迎进一步讨论,发邮件至echo740@sjtu.edu.cn


