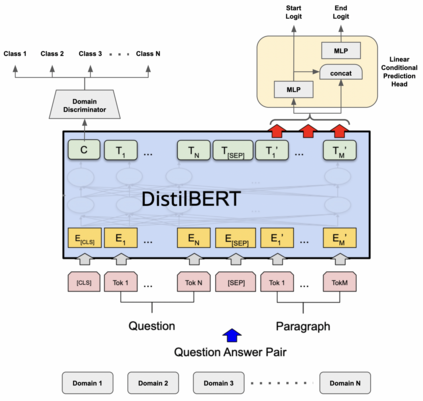
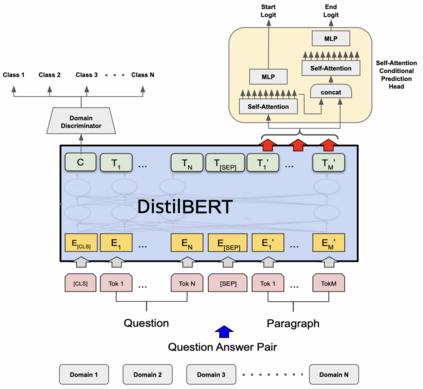
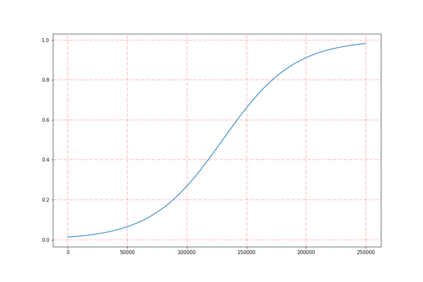
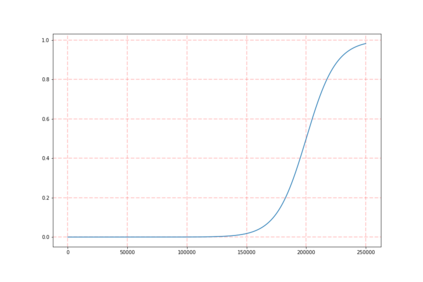
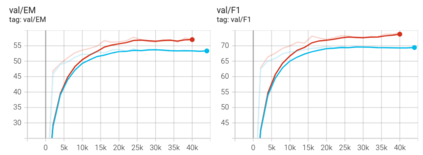
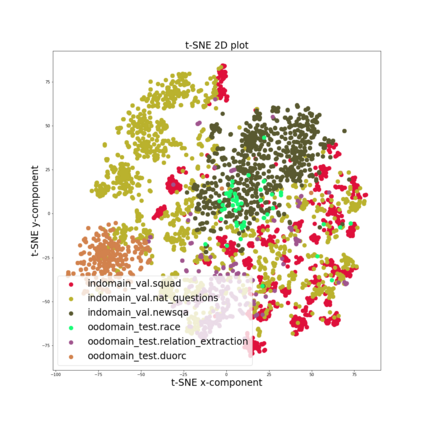
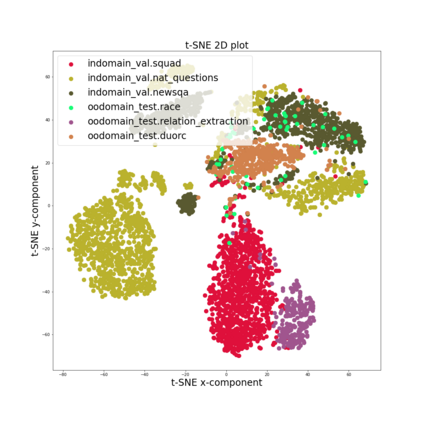
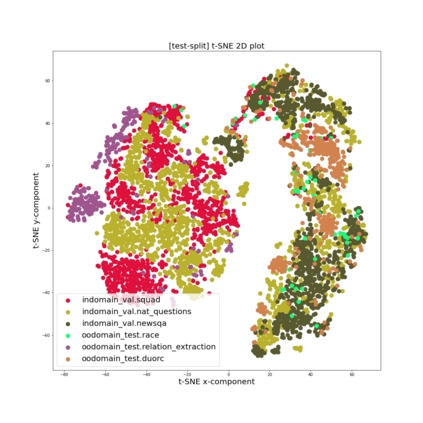
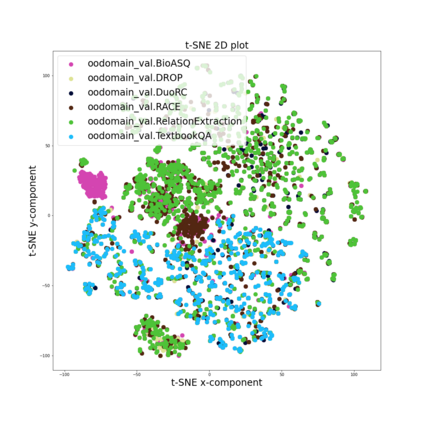
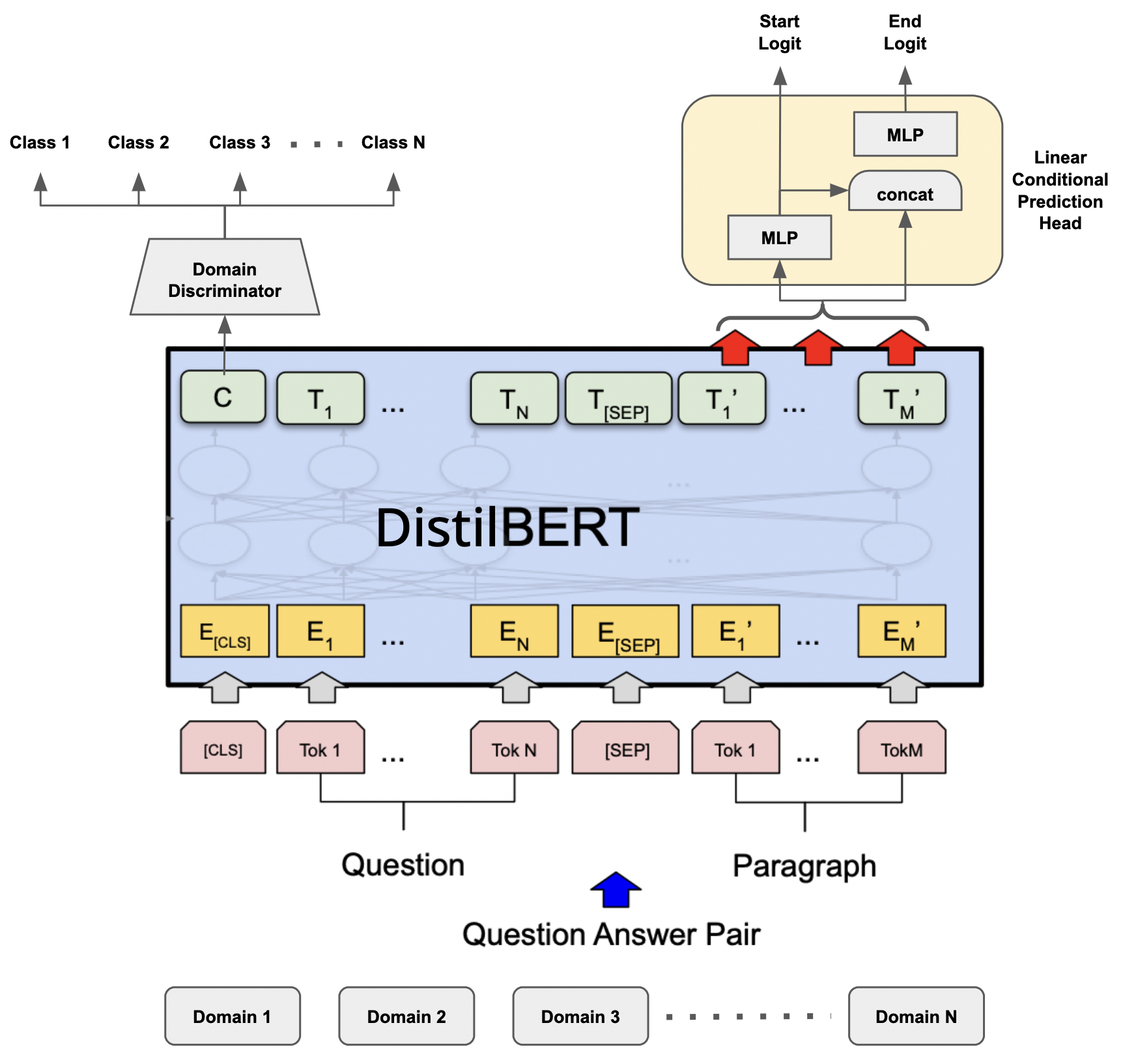
Training models that are robust to data domain shift has gained an increasing interest both in academia and industry. Question-Answering language models, being one of the typical problem in Natural Language Processing (NLP) research, has received much success with the advent of large transformer models. However, existing approaches mostly work under the assumption that data is drawn from same distribution during training and testing which is unrealistic and non-scalable in the wild. In this paper, we explore adversarial training approach towards learning domain-invariant features so that language models can generalize well to out-of-domain datasets. We also inspect various other ways to boost our model performance including data augmentation by paraphrasing sentences, conditioning end of answer span prediction on the start word, and carefully designed annealing function. Our initial results show that in combination with these methods, we are able to achieve $15.2\%$ improvement in EM score and $5.6\%$ boost in F1 score on out-of-domain validation dataset over the baseline. We also dissect our model outputs and visualize the model hidden-states by projecting them onto a lower-dimensional space, and discover that our specific adversarial training approach indeed encourages the model to learn domain invariant embedding and bring them closer in the multi-dimensional space.
翻译:对数据领域转移十分有力的培训模式在学术界和行业中都日益引起兴趣。问题解答语言模式是自然语言处理(NLP)研究的典型问题之一,随着大型变压器模型的出现,这些模式取得了很大成功。然而,现有方法大多基于以下假设而发挥作用:数据在培训和测试期间的分布相同,在培训和测试期间不切实际且在野外是无法伸缩的。在本文件中,我们探索了学习域差异性特征的对称培训方法,以便语言模式能够将外置数据集广泛归纳为外置数据集。我们还考察了其他各种提高模型性能的方法,包括:通过参数句子扩增数据、在起始字词上调整回答范围的预测并仔细设计了反射功能。我们的初步结果显示,与这些方法相结合,我们可以在EM评分方面实现1.52美元的改善,在外部验证数据集方面实现5.6美元的提升。我们还分解了我们的模型产出,并将隐藏的模型状态可视化为模型,方法是将数据投影射到更接近空间空间空间空间空间的深度学习方法。