ECCV 2018 | 迈向完全可学习的物体检测器:可学习区域特征提取方法

物体检测是计算机视觉领域的重要问题之一,现今大部分计算机视觉应用都依赖于物体检测模块,例如无人车应用中对于周围环境的感知,安防支付等应用中的人脸识别,新零售应用中的商品识别等等的第一步都是提取图像或视频中的感兴趣物体,也就是物体检测。
这一次人工智能的浪潮很大程度上来自于数据驱动方法的进展,也就是将人工智能系统中的各个模块和步骤从手工设计转变为可以从数据中学习。数据驱动方法不仅提高了系统的准确率,也增强了系统对于不同场景的适应性。在物体检测领域,图像特征提取、候选框生成、后处理方法等等同样经历了从手工设计到可学习的转变,但是对于区域特征提取,至今仍旧主要采用手工设计的方法,例如RoI Pooling方法。
近日,来自微软亚洲研究院和北京大学的研究者们针对物体检测中的区域特征提取步骤提出了一种统一现有区域特征提取方法的视角,并据此设计了一种新的可端到端学习的区域特征提取方法。新的方法在COCO检测任务上的表现普遍超过RoI Pooling及其变种,并且有望启发研究者们进一步探索完全可学习的物体检测系统。该论文已被ECCV 2018接收。
先进的基于区域的物体检测方法由五个步骤组成,分别是图像特征生成、候选区域(proposal)生成、区域特征提取、区域识别和重复检测去除。图像特征生成会输出空间大小为H×W和通道数为C_f的特征图x。候选区域生成会输出一定数量的关注区域(Rol),每个RoI用四个坐标的边界框b表示。通常,区域特征提取会从图像特征x和关注区域b生成区域特征y(b),如
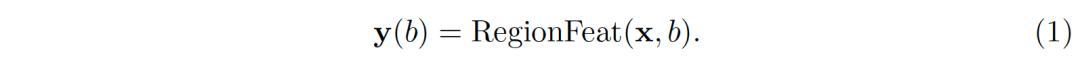
一般地,y(b)的维度为K×C_f,通道数保持和图像特征x一样为C_f,而K表示区域中空间子区域(spatial part)的个数。上述概念可以被泛化。一个子区域(part)未必有规则的形状,子区域的特征y_k (b)无需从图像特征x上固定的空间位置得来。甚至,子区域的并集未必是关注区域本身。在一般化的表达式中,子区域的特征被视为图像特征x在采样区域Ω_b(support region)上的加权和,如
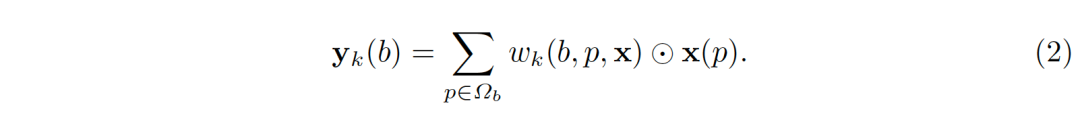
其中,Ω_b是采样区域,它可以是RoI本身,也可以包含更多语境(context)信息,甚至是全图;p枚举了Ω_b内的所有空间位置;w_k (b,p,x)是对应于位置p处的图像特征x(p)的加权权重;⊙表示逐元素乘法(element-wise multiplication),这里的权重假定是归一化的,即∑_(p∈Ω_b) w_k (b,p,x)=1。
研究证明各种关注区域池化方法都是上述观点的特例。在这些方法中,采样区域Ω_b和权重w_k (⋅)的具体形式各异,并且大多是人为定义的。
1. 普通的区域池化
普通的区域池化(Regular RoI Pooling)的采样区域Ω_b是RoI本身。它被规则地划分为网格(比如7×7)。每个子区域的特征y_k (b)是所有图像特征x(p)的最大或平均值,其中p位于第k个统计区内部。
以 averaging pooling 为例,公式(2)中的权重是
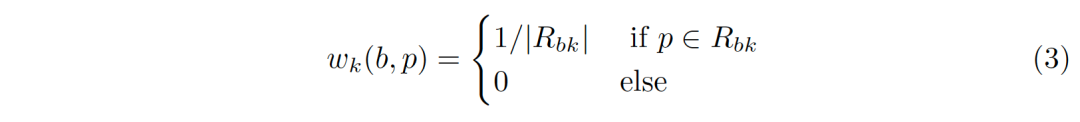
其中,R_bk是第k个统计区内部所有位置的集合。
Regular RoI Pooling 存在一个缺陷:由于神经网络的空间下采样,它无法区分非常近的若干关注区域。
2. 对齐的区域池化
对齐的区域池化(Aligned RoI Pooling)通过对每个R_bk中的采样点进行双线性插值,弥补了普通的区域池化中的量化缺陷。简单地说,假定每个统计区只采样一个点,比如统计区的中心(u_bk,v_bk)。设位置p=(u_p,v_p),公式(2)中的权重可以表示为
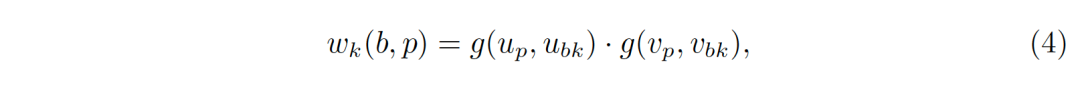
其中,g(a,b)=max(0,1-|a-b|)表示一个维度上线性插值的权重。注意公式(4)中的权重只有在采样点(u_bk,v_bk)周围最近的四个坐标才非零。
3. 可形变的区域池化
可形变的区域池化(Deformable RoI Pooling)通过对每一个统计区学习一个偏移(δu_bk,δv_bk),并作用于统计区中心,泛化了对齐的区域池化。公式(4)中的权重可以扩展为
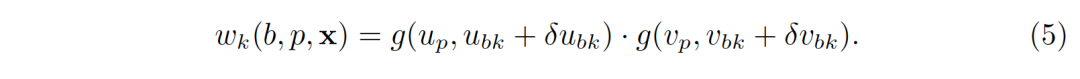
偏移是通过一个作用于图像特征x的可学习的子模块产生的。特别地,这个子模块从对齐的区域池化提取的特征出发,通过额外的全连接层(fully connected layer)回归偏移。
权重和偏移依赖于图像特征,而且可以端到端学习,物体的形变可以被更好地根据图像内容进行建模。另外,由于位移原则上可以任意大,所以采样区域Ω_b不再局限于关注区域内部,而是能够覆盖全图。
普通的和对齐的区域池化是完全由人工设计的,可形变的区域池化引入了可学习的模块,但它的形式仍然限制在规则的网格。在本文中,我们尝试用最少的人工设计学习公式(2)中的权重w_k (b,p,x)。
影响权重的因素有两个:第一是位置p和关注区域框b的几何关系。例如,在关注区域框b中的位置应该比离得较远的位置贡献更大;第二,图像特征x是否被适应性地使用。
所以,权重被建模成与两个因素的和的幂指数相关
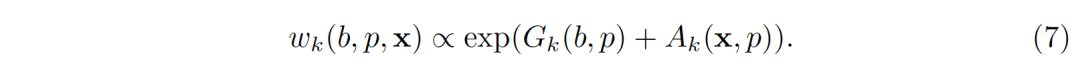
公式(8)中的第一项G_k (b,p)刻画了几何关系。
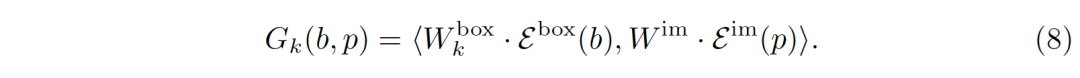
公式(8)本质上是一个注意力模型,注意力模型是建模远距离的或者性质各异的元素间依赖关系的利器,比如不同语言中的单词,位置/大小/比例不同的关注区域等。大量的实验表明,注意力模型可以很好地对区域和图像位置间的几何关系进行建模。
公式(7)中的第二项A_k (x,p)适应性地使用图像特征。它在图像特征上作用一层卷积,
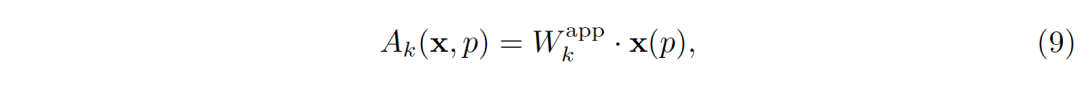
其中W_k^app代表可学习的卷积核的权值。
整个区域特征提取模块的结构如图1所示。在训练中,图像特征x和模块参数(W_k^box, W^im, 和W_k^app)都是同时更新的。
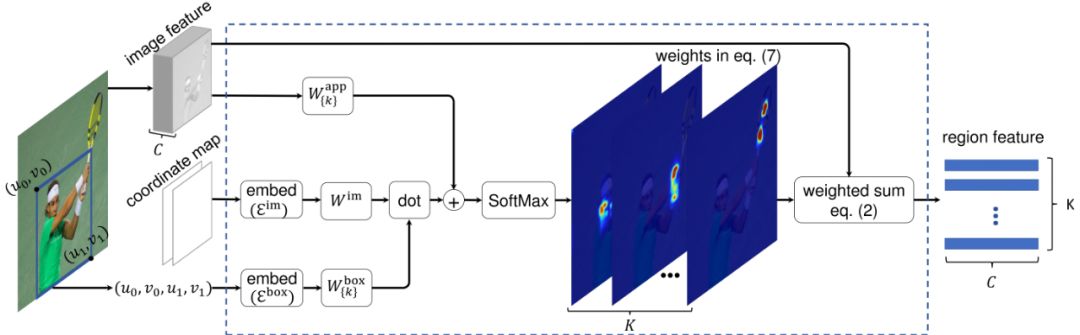
图1 所提出的区域特征提取模块中关于公式(2)和公式(7)的图示
为了降低计算量,我们提出了一种高效的实现方式——对Ω_b中的位置进行稀疏采样。直观上,关注区域内的采样点应该更密,而其外应该较稀疏。因此,Ω_b被划分为两个集合Ω_b=Ω_b^In∪Ω_b^Out,分别包含了关注区域内外的位置。Ω_b^Out代表了关注区域的语境(上下文)信息。它可以是空集,也可以覆盖全图。通过指定在Ω_b^In和Ω_b^Out中的最大采样数(通常,两者都设为196),复杂度可以被控制。给定关注区域b,Ω_b^In中的位置分别以stride_x^b和stride_y^b的步长,沿x和y两个方向采样。实验表明稀疏采样的准确度与朴素的密集采样相差无几。
我们在COCO检测数据集上对该方法进行实验。实验过程遵循COCO 2017的数据集划分:训练集的115k张图像用于训练;验证集中的5k张图片进行验证;并在测试集的20k张图像上进行测试。
我们使用最先进的R-CNN和FPN物体探测器,使用ResNet-50 和ResNet-101用作图像特征提取器的骨干(backbone)。默认情况下,使用基于ResNet-50的Faster R-CNN进行对比实验。交并比(IoU)阈值为0.5的标准非极大值抑制(NMS)被用于去除重复检测。
1. 采样区域的影响
实验发现,我们的方法胜过了其它两种池化方法。同时,随着采样区域的增大,新方法的表现也稳步提高,表明了利用语境信息是有帮助的。
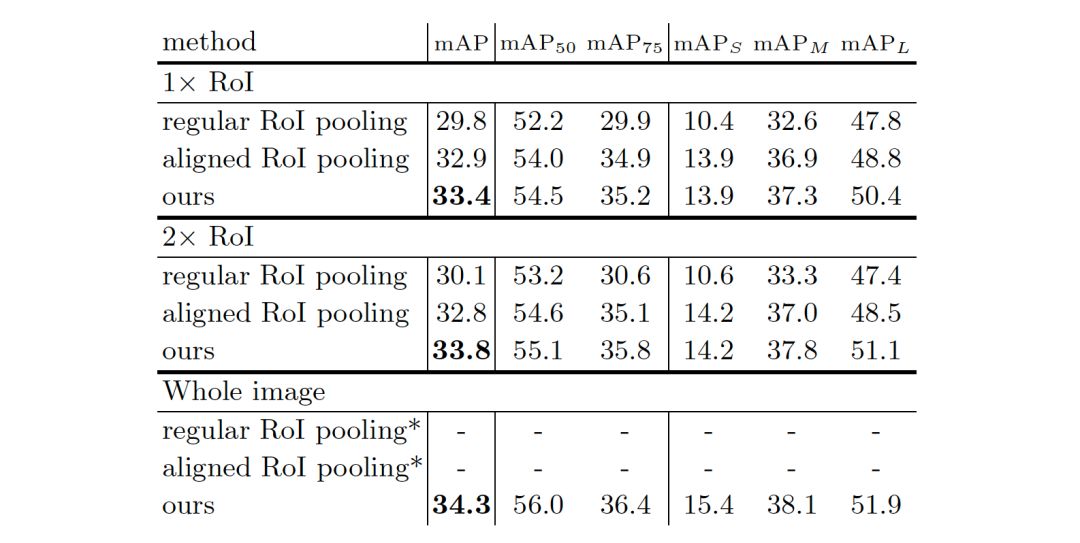
表2 不同采样区域的三种区域特征提取方法比较。在COCO验证集上报告准确性mAP。* 目前尚不清楚如何利用整个图像进行普通和对齐的目标区域池化方法,因此相应的准确数字被省略。
2. 稀疏采样的影响
由于稀疏采样实现,计算开销可以显著降低。默认情况下,对Ω_b^In和Ω_b^Out指定最多196个采样位置。实际中,面积较大的关注区域对于Ω_b^Out将具有较少的采样位置,而面积较小的关注区域对于Ω_b^In将具有比最大采样数更少的采样位置。对于Ω_b^In和Ω_b^Out,实际的平均采样位置数分别在114和86左右,如表3所示。相应的计算开销是4.16G FLOPS,粗略地等于两个全连接层的检测头的计算量(大约3.9G FLOP)。
对于之后的实验,稀疏采样实现对于Ω_b^In和Ω_b^Out都最多选取196个位置。
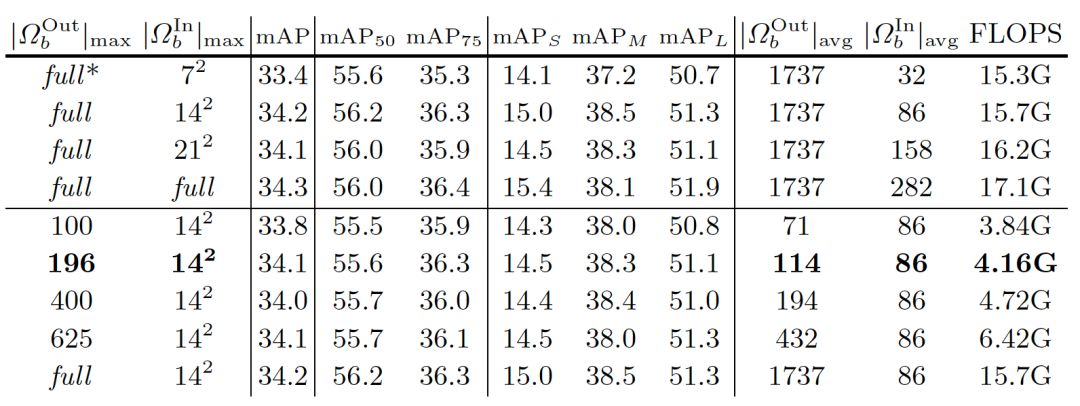
表3 不同采样位置数下的检测准确度和计算量。均采样个数|Ω_b^Out |_avg 和|Ω_b^In |_avg是在COCO的验证集上以ResNet-50 RPN生成的300个候选区域为样本计算而得的。
3. 几何关系和图像特征使用方法的影响
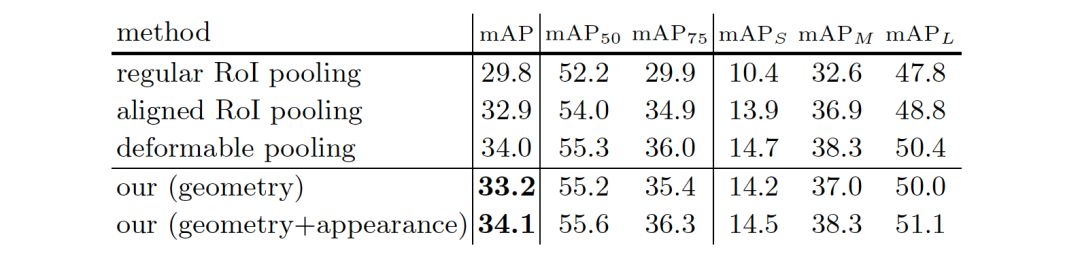
公式(7)中几何关系和图像特征使用对于所提出的区域特征提取模块的影响。在COCO的验证集上汇报结果。
4. 不同检测网络的比较
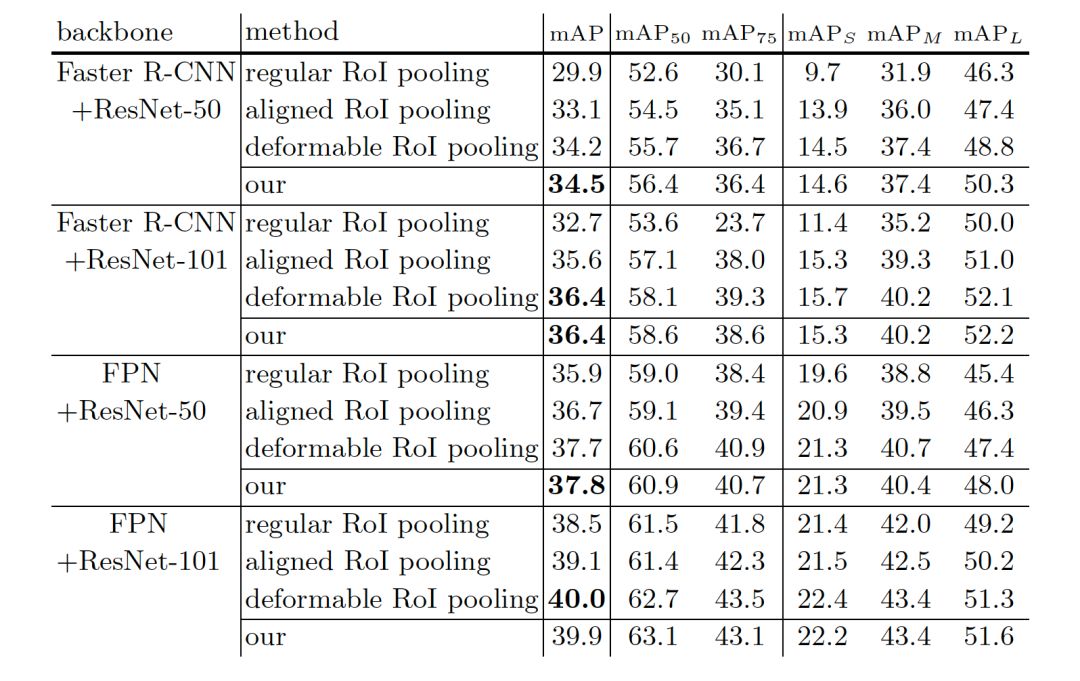
表5不同检测网络上不同方法的比较。在COCO的测试集上汇报结果。
5. 学到了什么?
下面具体看一下本文的区域特征提取算法到底学到了什么样的特征。公式(7)中的权重w_k (*)表示的是图像每个位置的特征对于最终区域特征的贡献。图2(a)显示了训练前后权重w_k (*)的变化,可以看出,训练伊始,权重w_k (*)很大程度上是随机的。在训练之后,不同部分的权重自动学习到区域的特征要关注区域上的不同位置,并主要集中在前景物体上。图2(b)分别显示了学习到的几何权重和表观权重,可以看出,几何权重主要集中在感兴趣区域,而表观权重则对应到所有前景物体上。
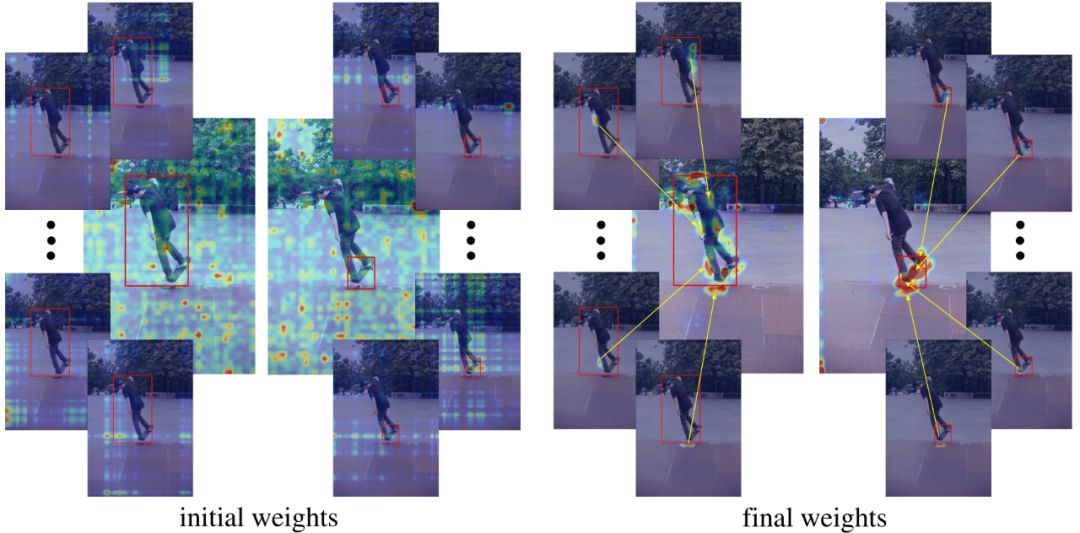
图2(a)给定两个RoI(红色框),初始(左)和最终(右)公式(7)中的权重w_k (*)。中心的图片展示了所有K=49个子区域对应的权重图的最大值。其周围4个小的图片显示了4个子区域分别对应的权重图。

图2(b)示例:几何关系对应的权重(第一行),图像特征对应的权重(第二行)和两者结合的权重(第三行)。
了解更多细节,请阅读我们的论文:
Learning Region Features for Object Detection
论文链接:https://arxiv.org/abs/1803.07066
本文共同作者还有胡瀚、代季峰、王立威、危夷晨
你也许还想看:
● CVPR 2018中国论文分享会 | 计算机视觉产业界和学术界的对话

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。



