行人检测、跟踪与检索领域年度进展报告
点击上方“深度学习大讲堂”可订阅哦!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!

编者按:在过去一年里,行人检测、行人跟踪和行人检索三项技术,在工业界已全面落地开花,其被广泛应用于人工智能、车辆辅助驾驶系统、智能机器人、智能视频监控、人体行为分析、智能交通等领域。然而,由于行人兼具刚性和柔性物体的特性,外观易受穿着、尺度、遮挡、姿态和视角等影响,行人检测仍然是计算机视觉领域中一个既具有研究价值、同时又极具挑战性的热门课题。南京理工大学的张姗姗教授将带着大家回顾在过去的一年中,这三个领域在学术界的研究进展。文末提供张教授报告中提到的所有论文的下载链接。

行人检测,就是将一张图片中的行人检测出来,并输出bounding box级别的结果。而如果将各个行人之间的轨迹关联起来,就变成了行人跟踪。而行人检索则是把一段视频中的某个感兴趣的人检索出来。
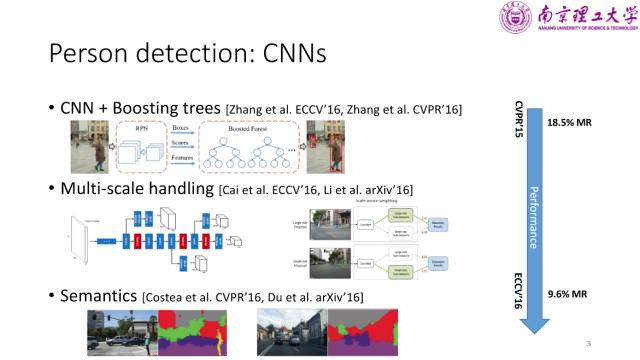
行人检测
卷积神经网络为通用物体检测任务带来了全面的性能提升。而行人检测技术也使用了Faster R-CNN 这样的通用检测框架,因而性能也得到了很大的提升。在 CVPR 2015中,当时在竞赛中的最好方法使用的还是传统的ACF 检测器,其漏检率是18.5%;而在 ECCV 2016中,在使用了 CNN 后,行人检测漏检率降低到了9.6%。
在过去的一年中,行人检测领域的工作大致可被归为以下三类:
第一类是将传统的检测方法Boosting trees 和 CNN 结合起来。张姗姗等人在CVPR 2016的工作是使用 ICF 提取proposal,然后使用 CNN 进行重新打分来提高检测的性能;在 ECCV 2016上,中山大学林倞教授课题组使用RPN 提取 proposal,同时提取卷积特征,然后使用 Boosting trees进行二次分类,性能得到了很大的提升。
第二类是解决多尺度问题,例如在视频数据中人的尺度变化问题。颜水成教授课题组提供了一种解决方法:训练两个网络,一个网络关注大尺度的人,另一个网络关注小尺度的人,在检测时将两个网络进行加权融合得到最终的结果,这样能使性能得到很大的提升;UCSD 在 ECCV 2016上有一个类似的工作,提出在高层提取大尺度人的特征,在低层提取小尺度人的特征,这样能保留尽量多的信息量,使得对小尺度的行人也有较好的检测效果。
第三类是使用语义分割信息来辅助行人检测。首先对整个图像进行语义分割,然后将分割的结果作为先验信息输入到检测网络中(包括传统的 ICF 网络,以及现在常用的CNN),这样可以通过对整体环境的感知来提高检测的效果。
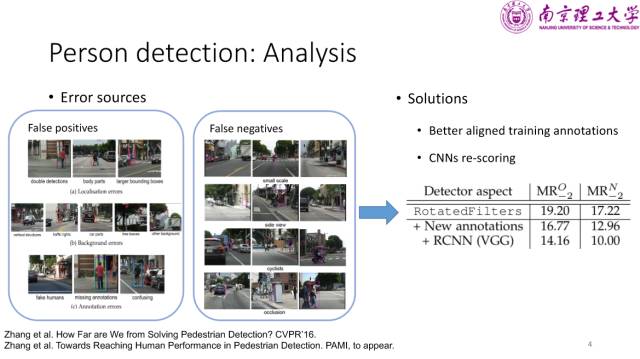
区别于通过提出一些新方法来提高检测率的科研方式,2016年张姗姗等人从分析的角度对各个工作进行总结和归纳。通过分析错误案例来找到错误来源,并提出相应的解决方案以进一步提高检测率。研究发现,在高层级中主要有两类错误,分别是定位错误和背景分类错误。可以尝试两个解决方案,其一是针对检测框对齐性比较差这一现象,可以通过使用对齐性更好的训练样本标签来解决;而针对模型判别能力比较差的问题,可以通过在传统的 ICF 模型上使用 CNN 进行重新打分来提升检测的性能。

行人检测任务存在一个领域迁移能力差的问题,例如在 Caltech dataset 上训练的模型在其上的性能很好,但是其在 KITTI dataset上的性能却比较差。之所以出现这样的问题是因为现有的数据集的多样性不够,CVPR 2017上将会公布一个新的行人检测数据集:CityPersons。CityPersons数据集是脱胎于语义分割任务的Cityscapes数据集,对这个数据集中的所有行人提供 bounding box 级别的对齐性好的标签。由于CityPersons数据集中的数据是在3个不同国家中的18个不同城市以及3个季节中采集的,其中单独行人的数量明显高于Caltech 和 KITTI 两个数据集。实验结果也表明,CityPersons 数据集上训练的模型在 Caltech 和 KITTI 数据集上的测试漏检率更低。也就是说,CityPersons数据集的多样性更强,因而提高了模型的泛化能力。
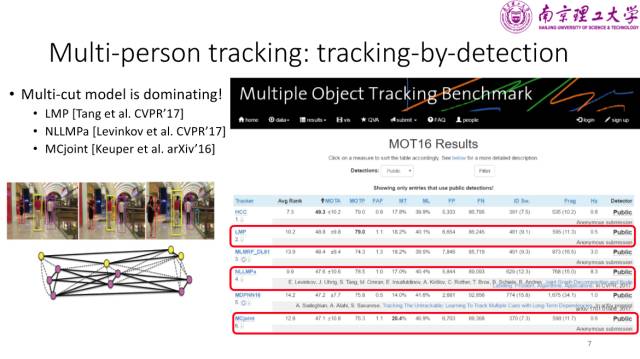
多人跟踪
在行人跟踪任务中的一个非常重要的子任务是多人跟踪,其中比较常见的是基于检测的跟踪,也就是将每一帧的检测结果关联成轨迹,每个行人目标都有各自的轨迹。在MOT排行榜上前六名的方法中,有三个使用了将跟踪问题转化为聚类问题的multi-cut 模型,并使用组合优化方法进行求解。multi-cut模型是一个非常简洁的模型,没有使用一些特定技巧,超参数也较少,其缺点是实时性比较差,速度不到1FPS。在 CVPR 2017上有个工作通过对求解器进行改进之后速度能达到8FPS,用multi-cut模型来求解跟踪问题,不失为一个很有前景的研究方向。

行人检索
关于行人检索,也称为行人再识别,从工程的角度来说,一个实用的行人再识别系统是包含行人检测,跟踪和检索三个子模块的,但是因为行人检测和行人跟踪一般是作为单独的课题进行研究,所以行人再识别主要关注的是检索方面的问题。 行人再识别早年的工作主要是基于图像的,即给定一个待检索行人(probe),在原型图像集上找到同一个人(gallery)。近几年开始出现一些基于视频的工作,此时 probe 和 gallery 也相应地变为了视频序列。
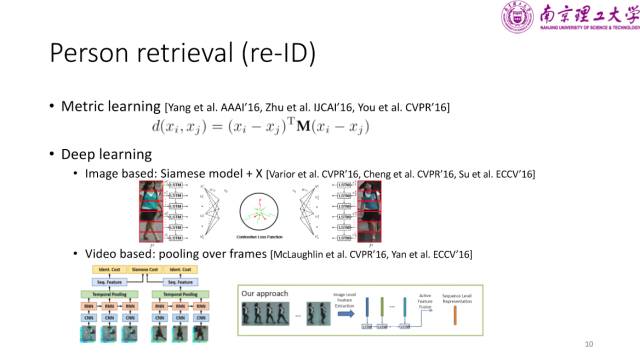
在行人检索这个领域,既有传统的方法也有深度学习的方法。传统方法主要基于度量学习,而深度学习方法最经典的模型是孪生网络,过去一年中提出了一些新的方法,就是为孪生模型上增加一些新的模块,包括使用新的损失函数、基于身体部位表示以及属性学习等方法。如果输入是视频的话,对序列提取特征时就需要对多帧进行池化操作。池化方法可采如传统的最大值池、均值池化、以及 ECCV 2016中提出的自学习的池化方法来学习更好的池化方式。
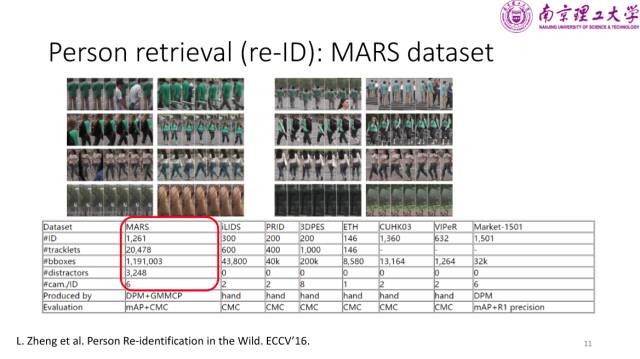
悉尼科技大学在 ECCV 2016上发布了一个基于视频的行人再识别的数据集 MARS dataset,与先前的数据集相比,其规模更大,轨迹和框的数目都更多。

总结
由于人在图像和视频数据中始终是重点关注的对象,所以吸引了很多研究者从事这方面的工作。而深度学习以及大规模的数据库更是推动了这个领域的发展。行人检测、行人跟踪、以及行人检索技术是紧密相连不可分割的,如果有更好的行人检测方法,也会推动行人跟踪和行人检索技术的发展,同时最新研究表明,行人检索可以辅助行人跟踪任务。所以,行人检测、行人跟踪、以及行人检索技术三者结合将是一个很好的研究方向。
文中提到所有论文的下载链接为:
http://pan.baidu.com/s/1eRO9xoY
致谢:
本文主编袁基睿,诚挚感谢志愿者范琦、贺娇瑜、李珊如对本文进行了细致的整理工作。

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者简介:

张姗姗教授,于2015年博士毕业于德国波恩大学计算机系,后在德国马普计算机研究所任博士后研究员。2016年29岁的张姗姗回国任南京理工大学计算机科学与工程学院教授,研究领域涉及目标检测、及无人驾驶中的视觉感知技术,发表各类国际会议及期刊数十篇,是一位美貌与智慧并重的青年学者。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站




