Cell子刊综述:药物研发进入智能生成时代


今天我们来重磅介绍一篇最近发表在 Cell Reports Medicine,作者为湖南大学曾湘祥教授,康奈尔大学 Fei Wang 教授,芝加哥西北大学大学 Yuan Luo 教授, MILA Jian Tang 教授,IBM 的 Seung-gu Kang 和 Wendy Cornel 教授,劳伦斯利弗莫尔国家实验室的 Felice C. Lightstone 教授,挪威奥斯陆大学的 Evandro F. Fang 教授,以色列特拉维夫大学 Ruth Nussinov 教授,美国克利夫兰医院的 Feixiong Cheng 教授的综述“Deep Generative Molecular Design Reshapes Drug Discovery”。文章为广大科研人员特别是非计算机领域专家提供 AI 分子生成模型工具指南,同时指出了目前该领域所面临的挑战以及未来的解决方向。
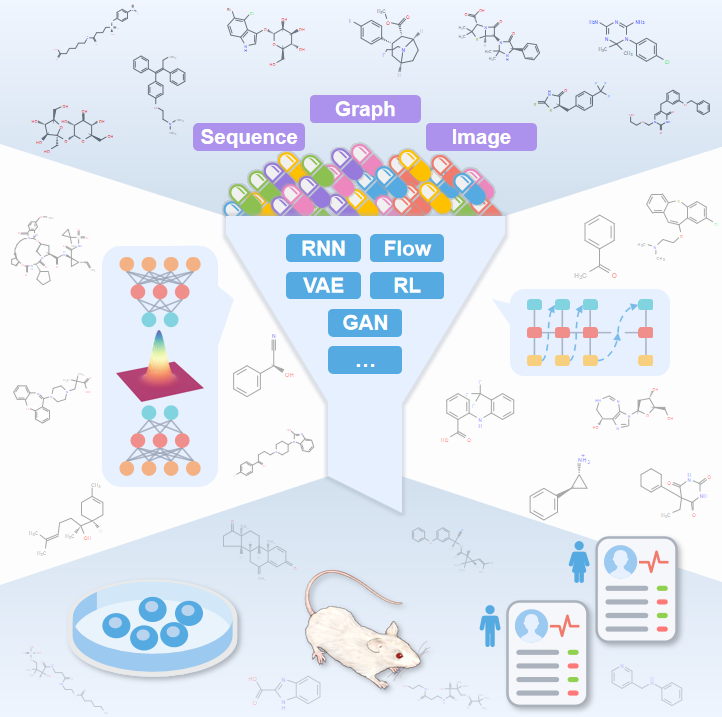
深度生成模型通过学习相应数据的分布和加入条件来生成具有所需特性的化合物,其创新可以显著促进算法的开发和在药物发现中的应用。在这个“大数据”时代,深度生成模型将彻底改变生物学、疾病和治疗学的信息观。在某些情况下,它比传统方法所需的时间更短。如果大规模应用,深度生成建模具有促进开发过程的潜力。因此,作者总结了现有的深度生成模型原理,分子生成涉及的相关常用数据库以及其应用,如下图所示。
▲ 图1 AI应用药物设计的多个过程

设计一种新药因需要满足一定的条件例如特定靶标、与靶外相关的物理化学特性以及其他生物学指标而极为复杂。深度生成模型之所以流行,是因为它们能够以一种既经济又高效的方式自动生成新的具有生物活性且可合成的分子。下面介绍深度生成模型中经常使用的工具。
1.1 分子表示和数据集
小分子通常用 SMILES 和 Graph 表示,现在越来越多的模型集中于研究分子的 3D 表示生成,对于蛋白质这种大分子,也有一维的氨基酸序列和二维的接触图,另外,传统的蛋白质图像或 3D 表示需要从冷冻电子显微镜和晶体学中获得准确的 3D 结构数据,但这种途径效率都比较低。最近的 AI 方法,例如 AlphaFold2,可以提供大量的蛋白质 3D 数据来应对这些挑战。
化学生物信息学数据库通常提供标记与未标记的数据来训练分子生成模型。其中,公开数据集有包含近 20 亿市售可获得的类药化合物库 ZINC,囊括许多特殊靶点的数据集 ChEMBL,大型有机分子数据库 GDB-17,超大化学数据库 Enamine 和 REALdb,以及一些蛋白质数据库例如 PDB 等。

▲ 图2(a)基于一维序列的表示;(b)基于图的表示;(c)小分子和大分子的三维表示。
1.2 常见生成模型
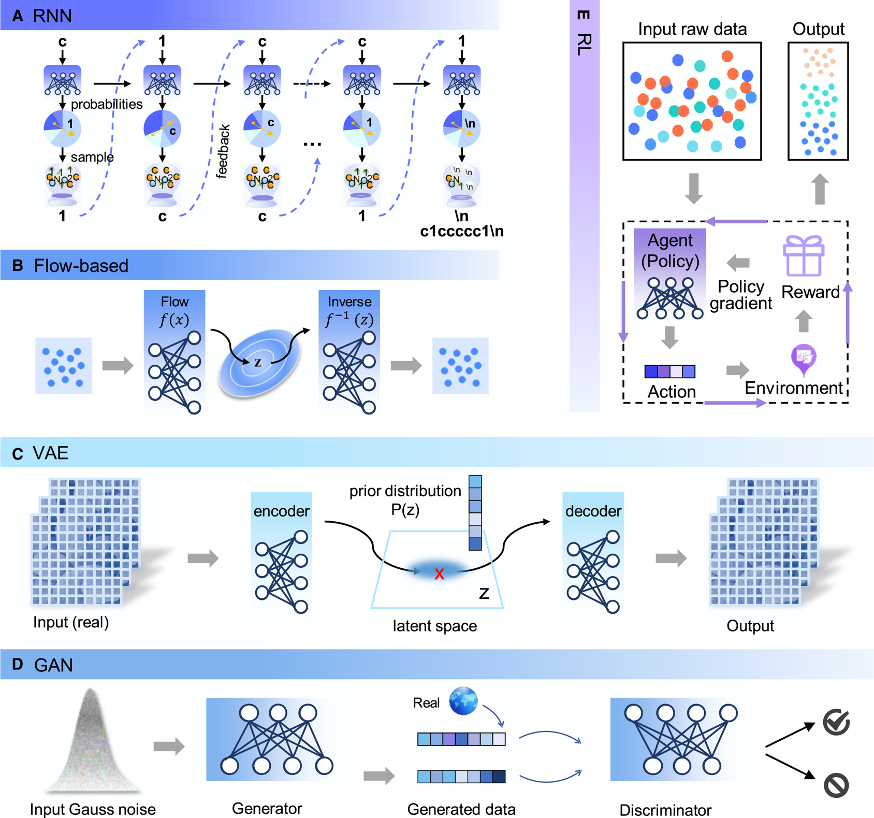
文章接下来分别介绍了四种常见的生成模型的基本原理和在分子生成领域常常使用的微调技术-强化学习模型。其中,RNNs 是自然语言处理领域常见的模型,也是其他生成模型的基本组件。它们非常适合用于具有序列生成(图3a)。而 VAE(图3c)通常编码器将分子映射至低维隐向量,再由解码器将潜在向量解码回分子,其中隐向量通常为标准高斯分布,VAE 是一种显式建模数据分布的模型,新分子通过在隐空间分布采样得到。
另外一种常见的生成模型即 GAN,常由一个生成器和一个判别器对抗学习(图 3d)。其中,判别器尽可能地去区分样本是来自生成器还是真实数据,而生成器负责生成无法让判别器分辨的假样本,最终直至判别器无法辨别真假,这时生成器生成的分子就达到了“以假乱真”的目的。
较为小众的是一种基于流的生成模型,我们知道,VAE 通过概率密度函数的变分下界,GAN 通过对抗训练隐式求解,而流模型则通过一系列可逆变换直接求解数据分布,通常用于基于 Graph 的分子生成(图3b)。
另外, RL 是一种通过动态决策过程探索化学空间的方法(上图e),在分子设计领域通常作为一种微调技术使得分子具有特定的属性,由 Agent、Reward 函数和 Environment 组成。其学习模型通常为首先将生成模型在一个较大的分子数据集上预训练以充分学习语法,之后 RL 在特定数据集上进行微调。

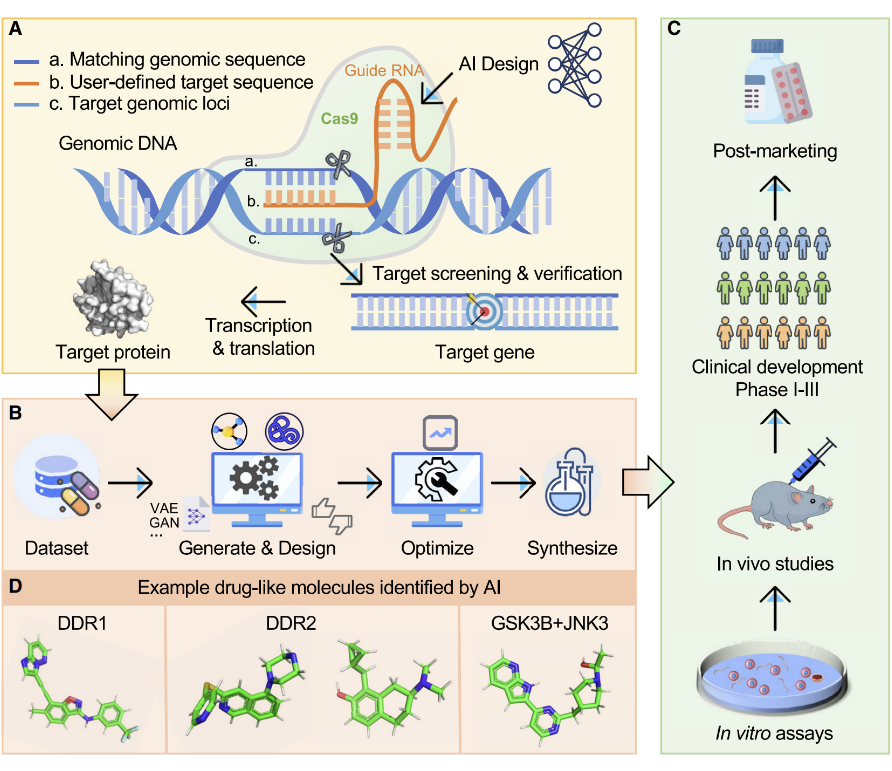
小分子药物设计中的应用
虚拟筛选这类传统方法面临着耗时和成本高昂的问题。深度生成模型的诞生加速了分子设计,通常称为——从头设计(De novo design),它是一种从头开始自动生成具有所需特性的分子技术。接下来我们将描述它在各类设计中的应用。
2.1 生成有效小分子
在小分子生成模型出现的初期,很多研究仅把重点偏向于如何生成高有效性分子。2016 年,Gómez Bombarelli 等人首次提出利用生成模型进行分子设计,它通过 VAE 将离散的高维分子化学空间映射到连续的潜在空间来生成分子。随后 Dai 等人提出的 SD-VAE 模型将语法导向翻译(SDT)加入 VAE 中以约束解码器,从而生成语法和语义有效的分子。
受传统药物设计基于片段的启发,Jin 等人提出了 JT-VAE,其将在化学上有效的分子子结构视为图结构中的一个节点,因此可在不显式加入化学规则的情况下实现分子有效性达到 100% 的效果。后来的 cWAE 将化合物重建误差减少了 80% 以上。MoFlow 通过基于流的模型生成键和原子,以 one-shot 方式生成分子图,MolGrow 则是递归地将每个节点拆分成两个来依次生成分子图,实验表明它们能够 100% 生成有效的分子。
2.2 生成类药分子
随着生成模型的逐渐成熟,分子生成模型致力于寻找具有特定性质的分子例如带有生物活性,合成可及性等,而不仅仅关注有效性,该目标对候选药物的成功至关重要。其中,GAN 模型融合基因表达特征进行分子条件生成被证明可以极高的概率自动设计出能够诱导产生所需转录组学特征的分子。
随后,GENTRL 通过设计奖励函数来产生抑制 DDR1 的新分子,通过体外和体内小鼠实验对生成的分子进行评估,以验证其与 DDR1 的结合亲和力以及临床前和药代动力学特性。但该模型不适用于缺乏目标活性数据集的情况,因此低资源生成更为可取。PGFS 旨在生成可合成的分子,其将分子生成问题视为选择反应物分子和反应转化的顺序决策过程,其中反应物的选择通过 Agent(神经网络)设计完成,将合成可及性融入奖励函数。
2.3 生成具有多目标类药物性质的分子
为更好满足药物研发的需求,分子生成模型需要设计具有多种约束的分子。RationaleRL 训练了一个基于图的强化学习模型,将预先选择的分子子图完成为一个整体分子,该分子具有多种属性,如针对多个靶点的生物活性(如 GSK3β 和 JNK3)、药物相似性的定量估计和合成可及性。
2.4 分子优化
分子优化的目的是为给定的分子获得所需的性能,这个过程类似于计算机视觉中的图像到图像的转换(例如,将马变成斑马)或自然语言处理中的文本风格转换。Jin 等人提出一种分子优化技术,其使用成对训练集将一个分子图转换为另一个具有更好特性的分子图,从而实现图到图的转换。基于 Graph 的分子图生成优化模型——Mol-CycleGAN,通过由两个 GAN 组成一个循环的训练框架上在两个数据集进行训练,以达到最小化第二网络原始分子和生成分子之间的距离。
2.5 获取配体与蛋白质相互作用的三维信息
分子生成通常融入 3D 蛋白信息补充结构信息,因此可以利用高质量的目标家族序列比对来识别整个激酶家族的结合位点残基,并训练 PaccMann 模型的 1D 字符串表示。用这个简化的数据集建立的定量构效关系(QSAR)模型比用传统的全序列方法建立的 QSAR 模型更好。

大分子药物设计中的应用
除了设计小分子外,人工智能的应用还扩展到大分子药物设计,例如设计抗菌肽、治疗蛋白和 CRISPR/Cas9 系统设计和优化,详情如下。
3.1 生成抗菌肽(AMP)
耐药细菌的出现导致每年全世界近 100 万人死于细菌感染,深度生成模型为抗菌肽的生成提供了一个方向。因此 Das 等人在 VAE 变体模型上加入分子动力学信息以生成具有广谱效力和低毒性的 AMPs。ClaSS 可在潜在空间上进行训练,并通过拒采样来筛选目标分子。目前已生成两种新的高效抗革兰氏阳性菌和革兰氏菌抗菌肽经实验表明该菌对大肠杆菌的耐药性低、毒性低。还有一种生成将信息传递方法和实验分析相结合的方法,其观测大肠杆菌的生长抑制现象,然后筛选已有数据库来识别目标结构分子,其中信息传递方法主要任务是通过交换信息方式。
3.2 生成治疗性蛋白
蛋白质从头设计在蛋白质治疗中发挥着重要作用。新冠肺炎的治疗中使用过一种蛋白质,它是由一种从头设计策略通过复制人类血管紧张素 I 转换酶 2(hACE2)的蛋白质界面快速准确生产的一类诱饵蛋白质。ProteinGAN 将自注意机制融入到 GAN 中,并学习蛋白质序列的进化关系,是生成具有特定功能的蛋白质序列的通用框架。
3.3 CRISPR/Cas9系统设计和优化
CRISPR/Cas9 系统由一种 Cas9 核酸酶和一种 guide RNA(gRNA)组成,是一种基因组编辑技术,也是一种确定药物发现靶点的工具(图 1a)。最近的研究证明了深度学习算法在设计和优化 CRISPR/Cas9 系统方面的有很大作用。
Chuai 等人提出了一种称为 DeepCRISPR 的设计工具,用于设计高灵敏度和特异性的 gRNA,该工具采用无监督和监督的 CNN 组合来学习 gRNAs 的表示。它可以自动检测并优化 gRNAs 的重要特征,这对 CRISPR 的设计具有很好的促进效果。SpCas9 基因组编辑工具可以解决目标偏差问题。但是目前这些数据驱动方法存在数据异构、稀疏性和不平衡等问题,CRISPR/Cas9系 统设计还有待进一步优化,比如用更高质量数据的高级算法等。

问题、观点和未来方向
尽管人们热衷于基于 AI 的药物发现,但该领域仍存在一定的挑战。例如,大多数机器学习模型需要大量数据用于训练和验证,尤其是深度学习模型。缺乏足够的质量和健壮的数据共享实践仍然是利用机器学习模型的阻碍。本文将简要讨论几个挑战和潜在的发展方向。
4.1 可解释生成模型
大多目前的深度生成模型缺乏可解释性,而且仅限于捕获数据的浅层统计相关性,无法解释其中的算法和生成的结果,这对生成可能存在一定影响。增强生成模型的可解释性十分重要。其中的一种方法是通过扰动模型中的输入或参数,观察结果如何变化。例如通过扰动解耦后的潜在空间每一维度来观测对应的每个属性的变化,这样就可以生成具有所需特性的分子。另一种解决方法是设计模型使其显示更多的语义信息,然后解释结果来得到因果关系。分子结构和药物性质之间关系的推理可以指导分子生成之后因果图的构建,模型也可以变得透明。
4.2 小样本生成模型
由于隐私、安全、伦理或少数患者患有罕见疾病等原因,一些数据可能较为稀少且难以获得。结合过去的知识,小样本学习可以缓解这类问题。例如改变 SMILES 序列的起始原子和分支顺序以增强数据,还有使用适当策略添加或删除边来改变基于图的数据等等。
过去常常利用迁移学习解决目标域的数据稀缺性,这种方法可以很好地解决肽或蛋白质设计中特定靶点训练数据不足的问题。针对孤儿靶点和罕见情况,可以利用零样本学习。另外,由目标视觉编码器和用于 SMILES 生成的语言模型组成的模型可基于蛋白质距离图来生成目标分子。
4.3 多模态生成模型
目前的研究通常侧重于分子结构数据,没有充分利用其他数据形式,而多模态深度生成模型可提供多个互补的视角,这种模型比单模态模型具有优势。因此,如何充分利用多样性和异质性的生物数据是一个值得探讨的问题。潜在的解决方案,一种是“模态对齐”,即将结构模态与其他模态连接起来,最后在中间空间对齐所有模态。另一种是“模态融合”,它在前一种的基础上去掉中间模态转换器,所有形态都直接映射到一个共同的潜在空间中,并用混合表示法表示(如图 4a)。
但上述方法条件现实往往无法满足,我们需要考虑其他方法,一种潜在的策略是通过涵盖生物活性的模式与分子的药代动力学和药效学特性的模式相结合来生成(如图 4b)。
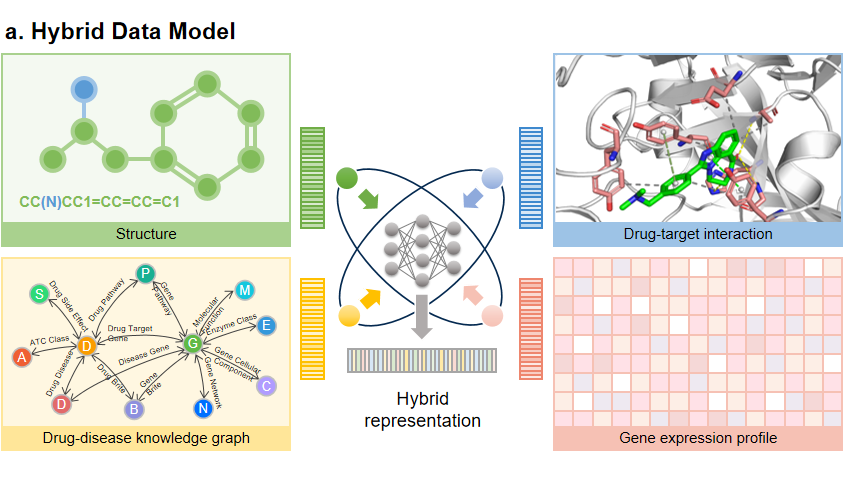
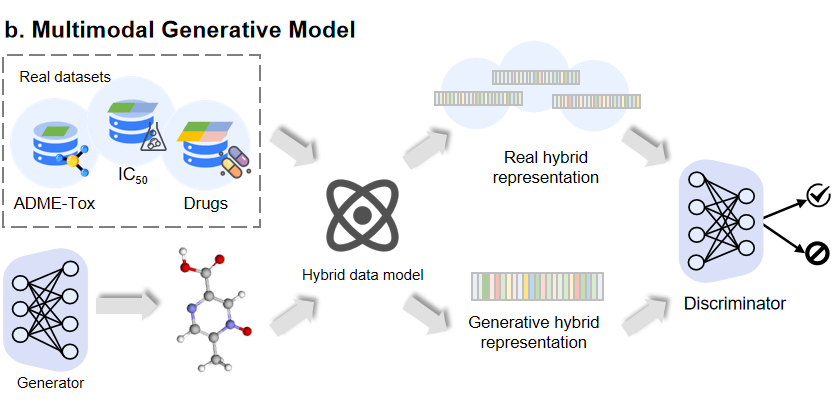
▲ 图4 基于多模态的分子生成模型
4.4 从数据消费者到数据生产者的生成模型
除深度学习算法和 GPU 的高性能计算的进步之外,数据也对于推动数据驱动的药物发现至关重要。但仅凭高质量数据的数量并不能保证药物发现中的决策。另一个问题是尽管认识到热力学和动力学特性的重要性,但在药物设计的深度学习模型中,热力学和动力学性质还未常态化。目前有一种利用 VAE 学习低维非线性嵌入,通过重构时滞构象的非线性嵌入,揭示了蛋白质运动的缓慢动力学。
还有一种是使用 VAE 变体,通过最大化预测信息瓶颈框架优化的加权反应坐标,有效地知道偏差模拟以及计算自由能和运动学。生成网络与分子模拟相结合,不仅可以提供有意义的见解,而且还可以为药物发现(包括 COVID-19)生成统计上可靠的蛋白质动力学数据。虽然目前的药物发现主要致力于小分子系统,但如果蛋白质构象动力学数据变得更加可行,药物设计将朝着提高安全性和有效性的方向发展。

总结
总而言之,深度生成模型的进步为药物发现带来了新的动力。但是 AI 技术的瓶颈,例如模型缺乏或有限的解释性,无法访问以及缺乏高质量数据的可用性,目前限制了它们的应用并影响其性能。目前迫切需要进一步开发和评估生成模型,以便在药物领域发挥其全部潜力。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧