

本次文献汇报分享一篇2021年3月哈佛大学的研究人员发表于《EXPERT OPINION ONDRUG DISCOVERY》的文章[1]。
前言
简介:近年来,人工智能(Artificialintelligence,AI)在计算机视觉、自然语言处理和游戏等领域取得了巨大进展。在药物发现领域,尽管已经有一些人工智能模型成功应用于ADME/T和活性预测,但仍然存在一个关键的挑战:这些预测模型是否具有可泛化性?
涵盖的领域:作者总结了药物早期发现阶段用于ADMET性质预测的人工智能模型的相关概念,进一步讨论了人工智能部署的适用性领域和数据集构建问题。进一步回顾了多任务、迁移和元学习的作用,这些学习框架利用辅助数据来克服泛化问题。
专家意见:作者的结论是,将可靠和信息丰富的人工智能模型集成到药物发现流程中,最有前途的方向是将学习特征表示、深度学习和新颖的学习框架结合起来。这样的方案能很好地解决药物发现相关的数据集稀疏和不完整的问题。
介绍
人工智能技术和深度学习(deeplearning,DL)技术已经在计算机视觉、自然语言处理、围棋游戏等多种领域产生了令人难以置信的结果。人工智能的广泛应用给药物的发现和重新利用带来了很大的希望,具有里程碑意义的案例包括新抗生素halicin的发现,以及AlphaFold2从序列到蛋白质结构的成功预测。尽管历年来大型人工智能模型的训练成本和资源消耗都很高,但计算机技术的创新已经打破了这些障碍。 从人工智能中受益的药物发现的关键领域之一是ADME/T性质预测,通过定量结构活性关系(quantitative structure–activity relationship,QSAR)模型来预测多种性质,从简单的物理化学性质到复杂的药代动力学(pharmacokinetic,PK)、药效学和毒理学特性。重要的PK端点包括清除率、通透性和稳定性;重要的药效学端点包括药物靶标特异性和选择性;重要的毒理学端点包括细胞色素P450诱导和hERG抑制。
预测模型的可用性是非常重要的,决定了化学家和生物学家是否能在临床中选择最有可能成功的候选药物。这些计算工具可以降低候选药物的流失率和研究成本,从而降低新药的价格,减轻病人的负担。 有许多的研究评估了新兴的人工智能模型与传统的机器学习和化学信息学模型。默克公司举办了一个Kaggle竞赛,挑战参赛者为15个不同的QSAR数据集建立模型。获胜的项目使用的是深度神经网络(deep neural network,DNN)。2015年,Ma等分析了这些结果,发现深度神经网络的简单应用通常优于随机森林(random forests,RFs)。2018年,Mayr等使用ChEMBL数据库对机器学习模型进行了详细的药物靶点预测比较,类似地发现DNN优于RFs,以及支持向量机(support vector machines,SVMs)、k-最近邻(K-nearest-neighbors,KNN)、朴素贝叶斯(NaïveBayes,NB)和相似集成方法(a similarity ensemble approach,SEA)。
未来的挑战在于提高人工智能的泛化能力,即从很少的数据推广到更广泛的化学空间。在某种程度上,这是一个固有的、棘手的问题;毕竟,人工智能模型只能基于现有数据进行预测。而且,药物发现的数据非常稀疏,在广阔的可能性化学空间中只有很少的实验数据点,而且根据分析的准确性和灵敏度,常常是带有噪声的,但这一挑战并非不可克服。
目前有很多工具和案例研究可以成功地对数据稀缺的环境建模。因此,开发用于性质预测的人工智能模型仍有很大的潜力。
人工智能分子性质预测正在迅速发展。尽管新模型多种多样,但每一种模型都有相同的两部分结构:(1)分子表征方法,它以计算机可读的格式对化合物进行编码;(2)人工智能算法,它基于分子表示法进行预测。这些是决定人工智能模型的准确性和可泛化性的决定性因素。
分子表征
在QSAR建模的早期历史中,分子描述符是人工定制的,用于非常小的数据集的特定模型框架。如果研究人员知道一个特定的性质依赖于一个特定的描述符,那么他们就可以使用那个描述符。然而,在大多数情况下,其中的关系更加复杂,包含了多种因素的组合。因此,当研究人员开始处理更大、更多样化的数据集时,对通用描述符的需求变得非常明显。多年来,研究人员开发和测试了许多类型的描述符。
描述符的选择应该遵守一下规定:首先,描述符应谨慎选择和删减,以避免过拟合。第二,描述符应该尽可能具有多样性。不同的描述符集合涵盖了物理化学空间的不同部分,必须确保一组描述符为特定的性质而建立,并且描述符能够扩展和泛化狭窄的训练集。第三,描述符在描述符空间中应该尽可能地相互正交。这使得模型具有更强的可解释性,同时也避免了将冗余的信息合并到模型中。
选择正确的描述符的困难很大程度上在于第一点和第二点之间的冲突。特别是在预测具有未知的或定义不清的数据框架的小型数据集时,很难找到一组合理的避免模型过拟合的描述符,同时仍包含模型作出准确预测所需的所有信息。
选择合适的分子描述符是一个特征工程问题。近来,某些模型试图通过直接从化合物的结构中学习特征表示来克服特征选择的缺点,通常表示为分子图、图理论矩阵或SMILES。使用学习得到的特征而不是设计的特征已经成为近来人工智能的一个基本主题。例如,在计算机视觉领域的重大突破ImageNet,它使用DL和大量的卷积层,而不是手工设计的特征。同样,在DeepMind的AlphaGo中,人工智能也没有使用任何预先设定好的动作序列。
然而,学习后的特征表示方法仍然面临困难。一个关键的限制是,一个模型需要大量的数据才能学习特征并且不过度拟合。
表1 小分子最常用和最有用的分子表示(表格翻译自原文)

人工智能算法
类似于分子表示,人工智能算法可以大致分为使用特征工程或特征学习。SVM、KNN、RF、线性回归和MLP模型属于特征工程;CNN、RNN和MPNN以及Transformers属于特征学习。这种划分并不完全明确,许多已学习特征的模型也将分子描述符作为输入。 在特征工程模型之外,MLP已被证明至少与支持SVM、KNN、RFs和线性回归模型相匹配,甚至经常在溶解度、细胞生长抑制、logD和CLINT等数据集上优于SVM、KNN、RFs和线性回归模型。虽然Ma等和Korotcov 等研究都同意MLPs优于所有其他模型,但Korotcov等发现,在hERG端点上,DNNs的表现更差,而Ma等发现DNNs的表现明显更好。尽管它们的模型架构略有不同,但这些差异只会带来适度的改变,不会对性能产生显著的变化。事实上,主要的区别在于Korotcov等人在他们的训练集中使用了大约500种化合物,而Ma等人使用了大约50000种化合物。也就是说,在大型复杂数据集上,特征学习模型比特征工程模型表现得更好。
表2 预测分子性质最常用和最有用的机器学习算法(表格翻译自原文)

数据质量和适用性领域****************
1.适用领域****************
模型的适用领域(The applicability domn,AD)指模型可以合理应用于预测的响应空间和描述符空间。药物发现空间正在扩展到小分子以外,面向的是更具有挑战性的、新的靶标。Hanser等人将AD的概念扩展到如图1所示的模型的决策域(decision domain,DD)。图1是一个层级结构,定义了一个空间,在这个空间中,模型可以在三个方面做出预测:(1)适用性,(2)可靠性,(3)可判定性。适用性衡量模型所要求的预测是否符合预期。可靠性衡量模型在其训练集中是否被给予足够的信息来做出明智的预测。可判定性衡量的是一个决策的实际有用程度。虽然没有明确说明,但大多数AD方法都可应用这个框架,这为分析模型的泛化性提供了一个有用的方法。
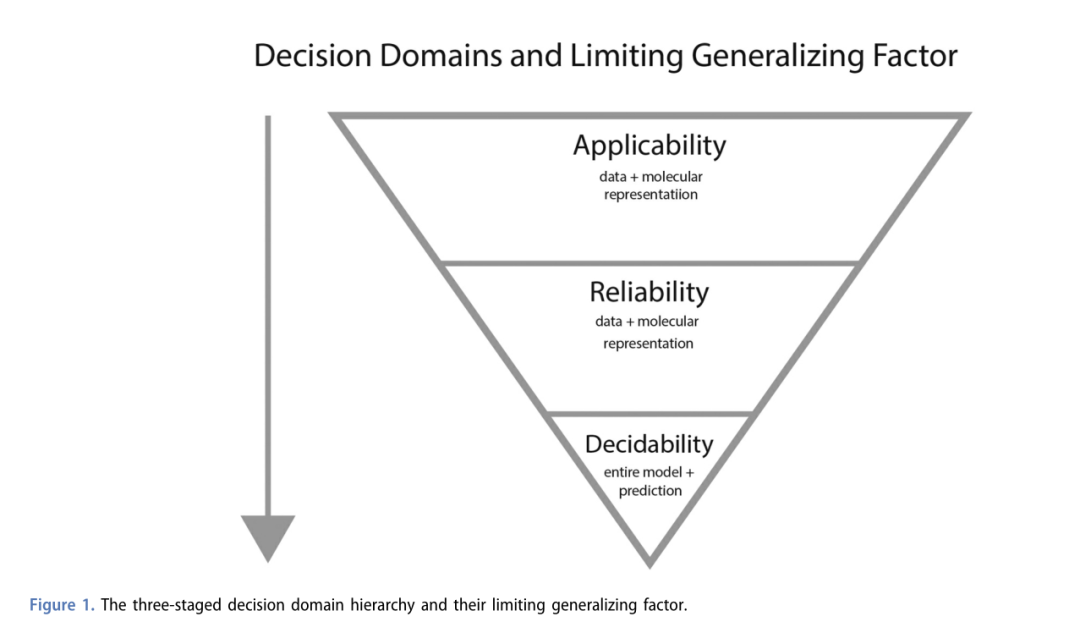
**图1 三级决策域层级结构及限制其泛化的因素(图片来自原文)**2.数据质量
对于实际的模型构建,数据是最基本的限制。在药物发现过程中的数据集生成较为困难,每个实验数据点都必须由生物学家和化学家来测量,这需要时间和资源。高通量初级试验的数据较多,而资源密集型的PK/PD和毒性端点所包含的数据较少,这些端点在候选药物选择的后期阶段更为重要。 药物发现中的数据量与人工智能的其他领域进行对比:在计算机视觉中,ImageNet拥有120万个数据点用于图像识别;在GPT3的自然语言处理中,研究人员使用了5000亿个文本数据标记。这种数量的数据对于任何端点来说都是难以获得的,PubChem的所有生物活性数据量也只有大约2.7亿个。尽管数据增强是一项强大的技术,即通过创建额外的样本以供模型学习,例如,通过采样不同的SMILES或同一化合物的不同构象,然而这并不能改变化合物的实验数据有限这一事实,因此无法表示新颖的化学物质。 还有一些更具体的、影响泛化性的因素。数据集可能会有很大的误差,或者偏向于特定的结构或端点值。另外,噪声数据集的问题降低了每个数据点的可靠性,从而降低了整个模型的可靠性。同时,模型不能比它所训练的实验数据更准确。因此,对于任何试验数据源,必须与领域专家一起仔细评估试验的稳健性和可靠性,以确定如何在模型构建中使用它。
3.数据集构建
近年来,无论是在工业领域还是公共领域,药物发现相关的数据量都有了很大的增长。在PubChem、ChEMBL和ZINC等数据库中存在的数据集,可供大众使用。制药公司有自己的内部专有数据库。为了创建更大、更全面的数据库,以构建更精确的模型,人们一直在努力将这些专有数据库集中在一起。其中规模最大的是MELLODDY,这是一个由10家制药公司组成的联盟,它使用联邦学习(federated learning,FL)来训练人工智能模型。 然而,许多数据集往往是异构的,因此不能直接应用模型。在筛选过程中,必须非常小心,如果汇总数据,则必须聘请领域专家。此外,数据归一化过程必须统一应用到整个数据集。在执行数据管理之后,数据分割的选择,创建训练、测试和验证集,对于生成可泛化模型也至关重要。
********学习框架
为了克服这些数据问题,研发人员提出了迁移学习、多任务学习和元学习框架。这些框架都建立在分子性质预测任务彼此相似这一假设的基础上,这些模型的基础思想是,通过给人工智能模型提供其他任务的额外信息,可以让它在某些特定任务中表现得更好。此类任务基于的假设是,所有的分子性质预测任务都植根于某些物理、化学和生物系统。
1.迁移学习
通过迁移学习,模型将知识从一个任务推广到另一个任务,以提高模型的适用性和可判定性。这种方法已经在一定程度上被用于调整全局模型以创建局部模型的实践中,两种最常见的迁移学习方法是:一、基于功能,其中一个模型学习一些分子表示,然后用于其他模型,二、基于参数,一个模型在一个任务上训练,然后它的权重作为近似解,微调至不同的任务。
2.多任务学习
多任务学习是一个单一的人工智能模型在同一时间预测一个化合物的许多不同的属性。这个框架背后的核心概念是,人工智能模型将在它所预测的每个属性之间共享信息。在适用性领域方面,假设我们有一种化合物,我们想要预测它的某些性质,而该化合物没有类似的化合物与实验数据。如果我们训练一个单任务模型,它就会脱离适用性领域。但对于多任务学习,假设可能存在不同性质的类似化合物的实验数据,人工智能模型可以利用这些信息做出明智的预测。
3.元学习
在元学习框架中,创建了一个二阶模型,二阶模型接收任务的数据,然后输出另一个人工智能模型的规范,然后在任务上进行训练。这些规范可以是模型的类型、要使用的超参数或权值初始化。 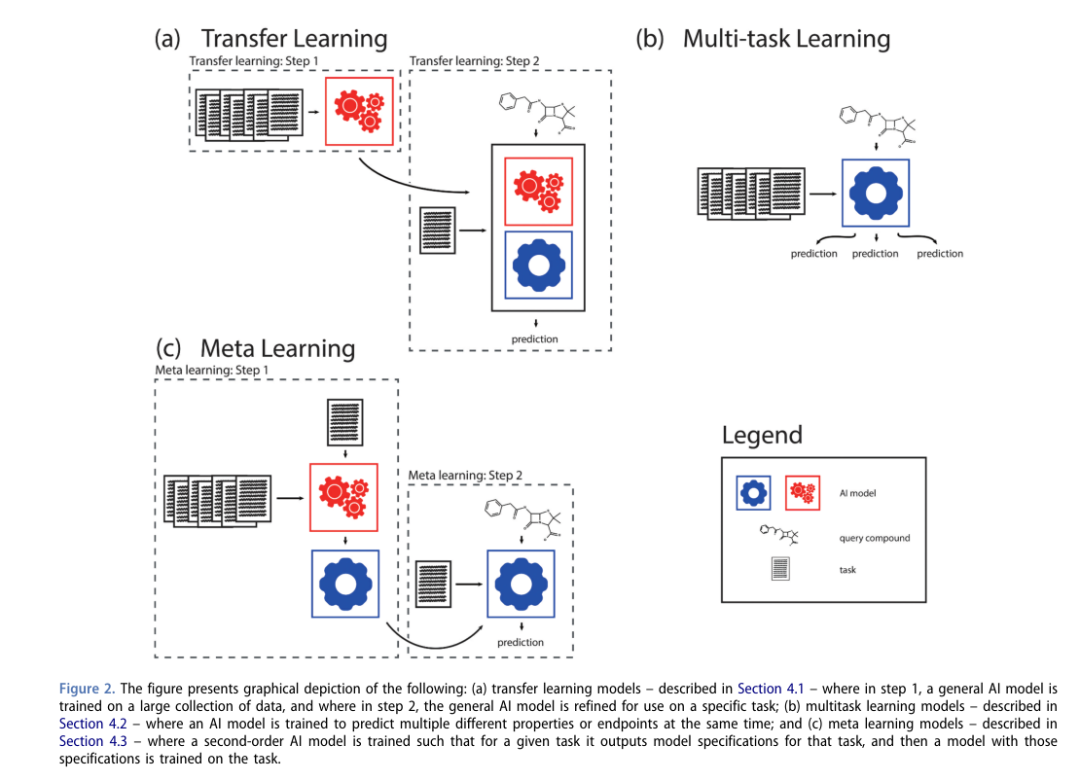
**总结
关键ADME/Tox端点和活性预测的人工智能模型对早期药物发现过程具有很高的应用价值,因为它们将加速临床选择更安全、更有效的药物,最终降低经济成本。仍然存在的关键挑战是数据的可用性和依赖于数据的模型的泛化性。 必须仔细评估数据的偏差或噪声,仔细地进行一致化处理,以构建稳健的数据集。在构建数据集之后,必须开发模型,以便从数据中最好地归纳并做出适当的预测。虽然目前选择使用哪些组件来创建模型还没有明确的答案,但总体趋势是向学习特征表示和深度学习模型发展,并且被集成在一些元学习、迁移学习或多任务学习框架下。
**参考文献 **[1] HUANG D Z, BABER J C, BAHMANYAR S S. The challenges of generalizability in artificial intelligence for ADME/Tox endpointand activity prediction. Expert Opinion on Drug Discovery, 2021, 16(9):1045-1056.
供稿:张满湛
**校稿:张梦婷/冯紫燕编辑:毛丽韫华东理工大学/上海市新药设计重点实验室/李洪林教授课题组

