科学家如何使用机器学习?《机器学习导论》2021这份讲义为你简明讲解,80页pdf

这是一门专门为STEM学生开发的机器学习入门课程。我们讨论有监督、无监督和强化学习。笔记开始阐述了没有神经网络的机器学习方法,如主成分分析,t-SNE,和线性回归。我们继续介绍基本和高级神经网络结构,如传统神经网络、(变分)自编码器、生成对抗网络、受限玻尔兹曼机器和递归神经网络。可解释的问题使用对抗性攻击的例子来讨论。
https://ml-lectures.org/docs/index.html
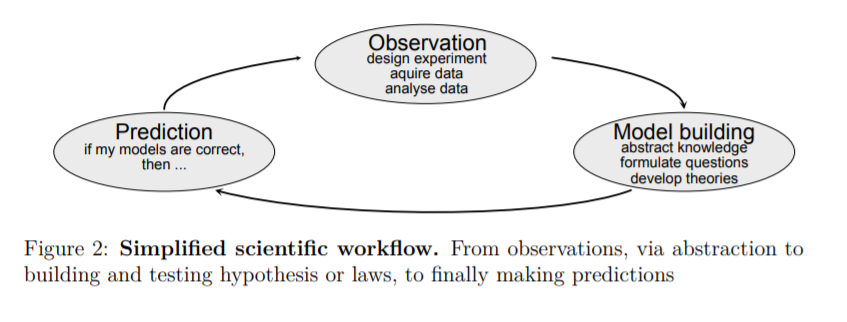
机器学习和人工神经网络无处不在,它们对我们日常生活的影响比我们可能意识到的还要深远。这堂课是专门针对机器学习在不同科学领域的使用的介绍。在科学研究中,我们看到机器学习的应用越来越多,反映了工业技术的发展。这样一来,机器学习就成为了精确科学的通用新工具,与微积分、传统统计学和数值模拟等方法并行其道。这就提出了一个问题,在图2所示的科学工作流程中,这些新方法是最好的。
此外,一旦确定了一项特定的任务,将机器学习应用到科学领域就会面临非常具体的挑战: (i) 科学数据通常具有非常特定的结构,例如晶体图像中近乎完美的周期性; (ii) 通常情况下,我们对应该反映在机器学习分析中的数据相关性有特定的知识; (iii) 我们想要了解为什么一个特定的算法会起作用,寻求对自然机制和法则的基本见解; (iv) 在科学领域,我们习惯于算法和定律提供确定性答案,而机器学习本质上是概率性的——不存在绝对的确定性。尽管如此,定量精度在许多科学领域是至关重要的,因此是机器学习方法的一个关键基准。
这堂课是为科学领域的科学家和学生介绍基本机器学习算法。我们将涵盖:
最基本的机器学习算法,
该领域的术语,简要解释,
监督和无监督学习的原理,以及为什么它是如此成功,
各种人工神经网络的架构和它们适合的问题,
我们如何发现机器学习算法使用什么来解决问题
机器学习领域充满了行话,对于不了解机器学习的人来说,这些行话掩盖了机器学习方法的核心。作为一个不断变化的领域,新的术语正在以快速的速度被引入。我们的目标是通过精确的数学公式和简洁的公式来切入俚语,为那些了解微积分和线性代数的人揭开机器学习概念的神秘面纱。
如上所述,数据是本节课所讨论的大多数机器学习方法的核心。由于原始数据在很多情况下非常复杂和高维,首先更好地理解数据并降低它们的维数往往是至关重要的。下一节,第2节将讨论在转向神经网络的重型机器之前可以使用的简单算法。
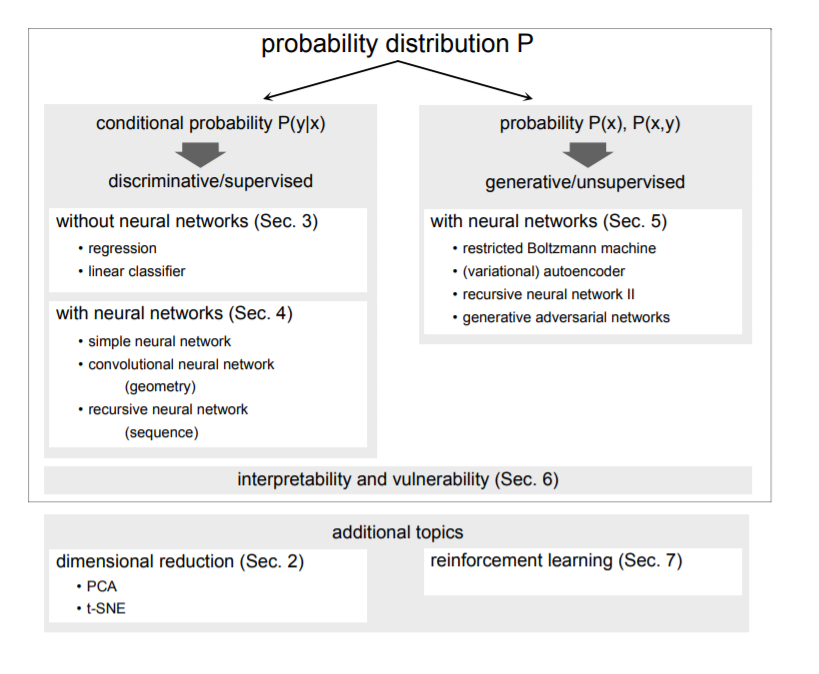
我们最关注的机器学习算法,一般可以分为两类算法,即判别算法和生成算法,如图3所示。判别任务的例子包括分类问题,如上述数字分类或分类为固体,液体和气相给出一些实验观测。同样,回归,也就是估计变量之间的关系,也是一个判别问题。更具体地说,我们在给定一些输入数据x的情况下,尝试近似某个变量y (label)的条件概率分布P(y|x)。由于这些任务中的大部分数据都是以输入数据和目标数据的形式提供的,这些算法通常采用监督学习。判别算法最直接地适用于科学,我们将在第3和第4节中讨论它们。
人工智能的前景可能引发科学领域的不合理预期。毕竟,科学知识的产生是最复杂的智力过程之一。计算机算法肯定还远没有达到那样复杂的水平,而且在不久的将来也不会独立地制定新的自然法则。尽管如此,研究人员研究了机器学习如何帮助科学工作流程的各个部分(图2)。虽然制定牛顿经典力学定律所需的抽象类型似乎难以置信地复杂,但神经网络非常擅长隐式知识表示。然而,要准确地理解它们是如何完成某些任务的,并不是一件容易的事情。我们将在第6节讨论这个可解释的问题。
第三类算法被称为强化学习(reinforcement learning),它不完全符合近似统计模型的框架. 机器学习的成功很大程度上与科学家使用适当算法的经验有关。因此,我们强烈建议认真解决伴随练习,并充分利用练习课程。




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SML80” 可以获取《科学家如何使用机器学习?《机器学习导论》2021这份讲义为你简明讲解,80页pdf》专知下载链接索引