【资源】斯坦福CS231n 2017春季课程全公开,视频+PPT+英文字幕
1 新智元编译
来源:cs231n.stanford.edu
编辑:刘小芹
【新智元导读】斯坦福大学的 CS231n(全称:面向视觉识别的卷积神经网络)一直是计算机视觉和深度学习领域的经典课程,每年开课都吸引很多学生。今年是该课程第3次开课,学生达到730人(第1次150人,第2次350人)。今年的CS231n Spring的instructors 是李飞飞、Justin Johnson和Serena Yeung,并邀请 Ian Goodfellow 等人讲解GAN等重要主题。最近斯坦福大学公开了该课程的全部视频(配备英文)、slides等全部课程资料,新智元带来介绍。
全部课程视频(英文字幕):http://t.cn/R9Dfnxn
所有课程资料、PPT等:http://cs231n.stanford.edu/syllabus.html


讲师和助教团队
计算机视觉在我们的社会中已经无处不在,例如应用于搜索、图像理解、apps、地图、医疗、无人机、自动驾驶汽车,等等。大部分应用的核心是视觉识别任务,例如图像分类、定位和检测。神经网络(又称“深度学习”)方法最新的进展大大提高了这些最先进的视觉识别系统的性能。本课程将带大家深入了解深度学习的架构,重点是学习这些任务,尤其是图像分类任务的端到端模型。
在为期10周的课程中,同学们将要学习实现、训练和调试自己的神经网络,并深入了解计算机视觉的最前沿的研究。期末作业将涉及训练一个数百万参数的卷积神经网络,并将其应用于最大的图像分类数据集(ImageNet)。我们将重点介绍如何创建图像识别问题,学习算法(例如反向传播算法),训练和微调网络的实用工程技巧,引导学生进行实际操作和最终的课程项目。本课程的背景知识和材料的大部分来自 ImageNet 挑战赛。
熟练使用Python,C / C ++高级熟悉所有的类分配都将使用Python(并使用numpy)(我们为那些不熟悉Python的人提供了一个教程),但是一些深入学习的库 我们可以看看后面的类是用C ++编写的。 如果你有很多的编程经验,但使用不同的语言(例如C / C ++ / Matlab / Javascript),你可能会很好。
大学微积分,线性代数(例如MATH 19或41,MATH 51)您应该很乐意使用衍生词和理解矩阵向量运算和符号。
基本概率和统计学(例如CS 109或其他统计学课程)您应该知道概率的基础知识,高斯分布,平均值,标准偏差等。
CS229(机器学习)的等效知识我们将制定成本函数,采用导数和梯度下降执行优化。
课程Notes: http://cs231n.github.io/
模块0:准备内容
Python / Numpy 教程
IPython Notebook 教程
Google Cloud 教程
Google Cloud with GPU教程
AWS 教程
模块1:神经网络
图像分类:数据驱动的方法,k最近邻法,train/val/test splits
L1 / L2距离,超参数搜索,交叉验证
线性分类:支持向量机,Softmax
参数化方法,bias技巧,hinge loss,交叉熵损失,L2正则化,web demo
优化:随机梯度下降
本地搜索,学习率,分析/数值梯度
反向传播,直觉
链规则解释,real-valued circuits,gradient flow中的模式
神经网络第1部分:建立架构
生物神经元模型,激活函数,神经网络架构
神经网络第2部分:设置数据和损失
预处理,权重初始化,批量归一化,正则化(L2 /dropout),损失函数
神经网络第3部分:学习和评估
梯度检查,完整性检查,动量(+ nesterov),二阶方法,Adagrad / RMSprop,超参数优化,模型集合
把它放在一起:一个神经网络案例研究
极小2D玩具数据示例
模块2:卷积神经网络
卷积神经网络:架构,卷积/池化层
层,空间排列,层模式,层大小模式,AlexNet / ZFNet / VGGNet案例研究,计算考虑
理解和可视化卷积神经网络
tSNE嵌入,deconvnets,数据梯度,fooling ConvNets,human comparisons
迁移学习和微调卷积神经网络
Lecture 1:面向视觉识别的卷积神经网络课程简介

Lecture 1介绍了计算机视觉这一领域,讨论了其历史和关键性挑战。我们强调,计算机视觉涵盖各种各样的不同任务,尽管近期深度学习方法取得了一些成功,但我们仍然远远未能实现人类水平的视觉智能的目标。
关键词:计算机视觉,寒武纪爆炸,暗箱,Hubel 和 Wiesel,积木块世界,规范化切割,人脸检测,SIFT,空间金字塔匹配,定向梯度直方图,PASCAL视觉对象挑战赛,ImageNet挑战赛
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture1.pdf
Lecture 2:图像分类

Lecture 2 使图像分类问题正式化。我们讨论了图像分类问题本身的难点,并介绍了数据驱动(data-driven)方法。我们讨论了两个简单的数据驱动图像分类算法:K-最近邻法(K-Nearest Neighbors)和线性分类(Linear Classifiers)方法,并介绍了超参数和交叉验证的概念。
关键词:图像分类,K最近邻,距离度量,超参数,交叉验证,线性分类器
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture2.pdf
Lecture 3:损失函数和最优化

Lecture 3 继续讨论线性分类器。我们介绍了损失函数的概念,并讨论图像分类的两个常用的损失函数:多类SVM损失(multiclass SVM loss)和多项逻辑回归损失(multinomial logistic regression loss)。我们还介绍了正规化(regularization ),作为对付过拟合的机制,以及将权重衰减(weight decay )作为一个具体的例子。 我们还介绍了优化(optimization)的概念和随机梯度下降(stochastic gradient descent )算法。我们还简要讨论了计算机视觉特征表示(feature representation)的使用。
关键词:图像分类,线性分类器,SVM损失,正则化,多项逻辑回归,优化,随机梯度下降
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture3.pdf
Lecture 4:神经网络介绍

在 Lecture 4 中,我们从线性分类器进展到全连接神经网络(fully-connected neural network)。本节介绍了计算梯度的反向传播算法(backpropagation algorithm),并简要讨论了人工神经网络与生物神经网络之间的关系。
关键词:神经网络,计算图,反向传播,激活函数,生物神经元
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture4.pdf
Lecture 5:卷积神经网络

在 Lecture 5 中,我们从完全连接的神经网络转向卷积神经网络。我们将讨论卷积网络发展中的一些关键的历史里程碑,包括感知器,新认知机(neocognitron),LeNet 和 AlexNet。我们将介绍卷积(convolution),池化(pooling)和完全连接(fully-connected)层,这些构成了现代卷积网络的基础。
关键词:卷积神经网络,感知器,neocognitron,LeNet,AlexNet,卷积,池化,完全连接层
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture5.pdf
Lecture 6:训练神经网络1
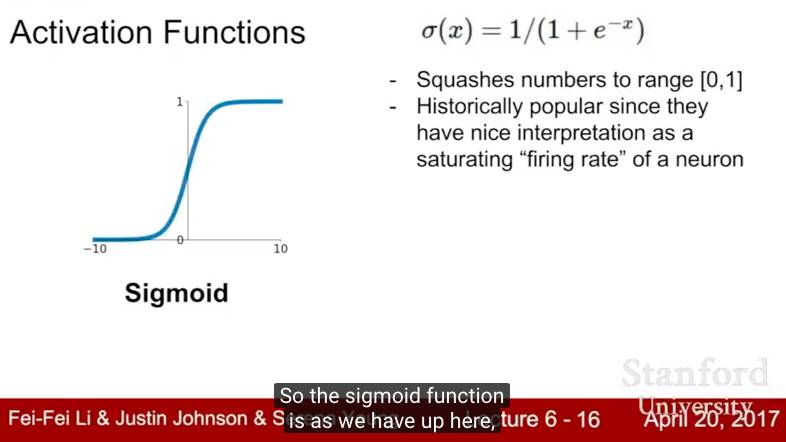
在Lecture 6中,我们讨论了现代神经网络的训练中的许多实际问题。我们讨论了不同的激活函数,数据预处理、权重初始化以及批量归一化的重要性; 我们还介绍了监控学习过程和选择超参数的一些策略。
关键词:激活函数,数据预处理,权重初始化,批量归一化,超参数搜索
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
Lecture 7:训练神经网络2
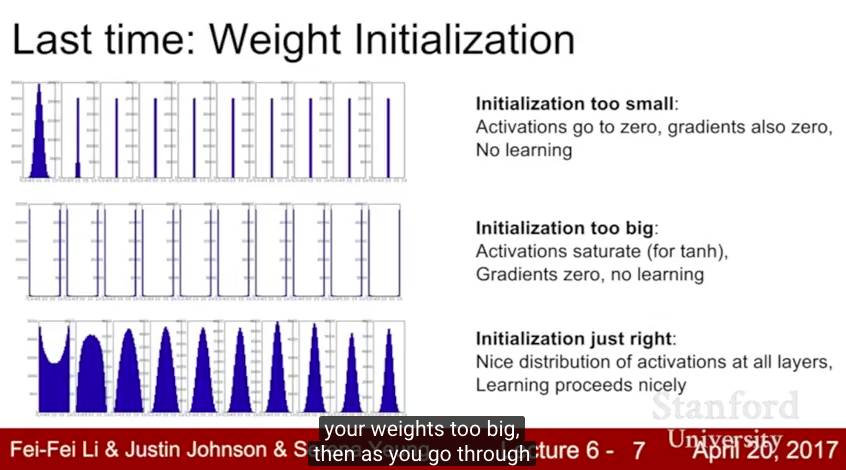
Lecture 7继续讨论训练神经网络中的实际问题。我们讨论了在训练期间优化神经网络的不同更新规则和正则化大型神经网络的策略(包括dropout)。我们还讨论转移学习(transfer learnin)和 fine-tuning。
关键词:优化,动量,Nesterov动量,AdaGrad,RMSProp,Adam,二阶优化,L-BFGS,集合,正则化,dropout,数据扩张,迁移学习,fine-tuning
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
Lecture 8:深度学习软件

Lecture 8 讨论了如何使用不同的软件包进行深度学习,重点介绍 TensorFlow 和 PyTorch。我们还讨论了CPU和GPU之间的一些区别。
关键词:CPU vs GPU,TensorFlow,Keras,Theano,Torch,PyTorch,Caffe,Caffe2,动态计算图与静态计算图
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture8.pdf
Lecture 9:CNN架构

Lecture 9 讨论了卷积神经网络的一些常见架构。我们讨论了 ImageNet 挑战赛中表现很好的一些架构,包括AlexNet,VGGNet,GoogLeNet 和 ResNet,以及其他一些有趣的模型。
关键词:AlexNet,VGGNet,GoogLeNet,ResNet,Network in Network,Wide ResNet,ResNeXT,随机深度,DenseNet,FractalNet,SqueezeNet
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
Lecture 10:循环神经网络

Lecture 10讨论了如何使用循环神经网络为序列数据建模。我们展示了如何将循环神经网络用于语言建模和图像字幕,以及如何将 soft spatial attention 纳入图像字幕模型中。我们讨论了循环神经网络的不同架构,包括长短期记忆(LSTM)和门循环单元(GRU)。
关键词:循环神经网络,RNN,语言建模,图像字幕, soft attention,LSTM,GRU
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
Lecture 11:检测和分割

在Lecture 11中,我们超越了图像分类,展示了如何将卷积网络应用于其他计算机视觉任务。我们展示了具有下采样和上采样层的完全卷积网络可以怎样用于语义分割,以及多任务损失如何用于定位和姿态估计。我们讨论了一些对象检测方法,包括基于区域的R-CNN系列方法和 single-shot 方法,例如SSD和YOLO。最后,我们展示了如何将来自语义分割和对象检测的想法结合起来进行实例分割( instance segmentation)。
关键词:语义分割,完全卷积网络,unpooling,转置卷积(transpose convolution),localization,多任务损失,姿态估计,对象检测,sliding window,region proposals,R-CNN,Fast R-CNN,Faster R-CNN,YOLO,SSD,DenseCap ,实例分割,Mask R-CNN
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
Lecture 12:可视化和理解

Lecture 12讨论了可视化和理解卷积网络内部机制的方法。我们还讨论了如何使用卷积网络来生成新的图像,包括DeepDream和艺术风格迁移。
关键词:可视化,t-SNE,saliency maps,class visualizations,fooling images, feature inversion,DeepDream,风格迁移
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture12.pdf
Lecture 13:生成模型
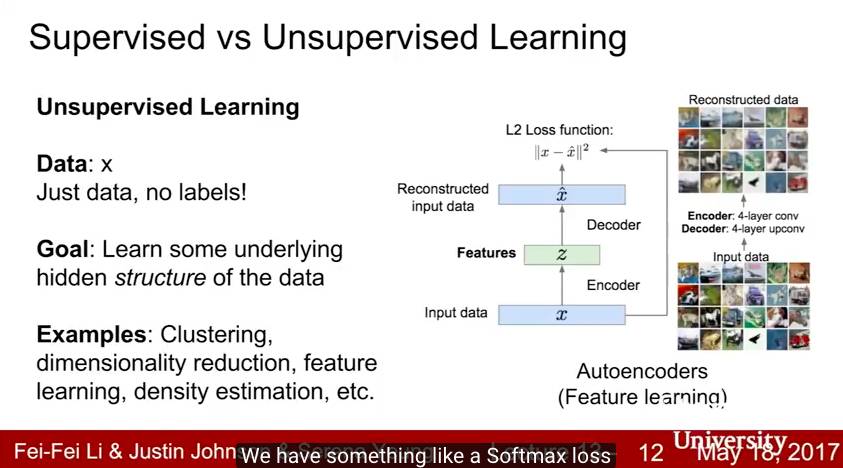
在Lecture 13中,我们超越了监督学习,并将生成模型作为一种无监督学习的形式进行讨论。我们涵盖了自回归的 PixelRNN 和 PixelCNN 模型,传统和变分自编码器(VAE)和生成对抗网络(GAN)。
关键词:生成模型,PixelRNN,PixelCNN,自编码器,变分自编码器,VAE,生成对抗网络,GAN
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture13.pdf
Lecture 14:深度强化学习
在Lecture 14中,我们从监督学习转向强化学习(RL)。强化学习中,智能体必须学会与环境交互,才能最大限度地得到奖励。 我们使用马尔科夫决策过程(MDPs),策略,价值函数和Q函数的语言来形式化强化学习。我们讨论了强化学习的不同算法,包括Q-Learning,策略梯度和Actor-Critic。我们展示了强化学习被用于玩 Atari 游戏,AlphaGo在围棋中超过人类专业棋手等。
关键词:强化学习,RL,马尔科夫决策过程,MDP,Q-Learning,政策梯度,REINFORCE,actor-critic, Atari 游戏,AlphaGo
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture14.pdf
Lecture 15:深度学习的高效方法和硬件

在Lecture 15中,客座讲师 Song Han 讨论了可用于加快深度学习工作负载训练和推理的算法和专用硬件。我们讨论了剪枝,weight sharing,量化等技术,以及其他加速推理过程的技术,包括并行化,混合精度(mixed precision)等。我们讨论了用于深度学习的专门硬件,例如GPU,FPGA 和 ASIC,包括NVIDIA最新Volta GPU中的Tensor Core,以及谷歌的TPU(Tensor Processing Units)。
关键词:硬件,CPU,GPU,ASIC,FPGA,剪枝,权重共享,量化,二元网络,三元网络,Winograd变换,EIE,数据并行,模型并行,混合精度,FP16,FP32,model distillation,Dense-Sparse-Dense训练,NVIDIA Volta,Tensor Core,Google TPU,Google Cloud TPU
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture15.pdf
Lecture 16:对抗样本和对抗训练

Lecture 16由客座讲师Ian Goodfellow主讲,讨论了深度学习中的对抗样本(Adversarial Examples)。本讲讨论了为什么深度网络和其他机器学习模型容易受到对抗样本的影响,以及如何使用对抗样本来攻击机器学习系统。我们讨论了针对对抗样本的潜在防御,以及即使在没有明确的对手的情况下,如何用对抗样本来改进机器学习系统,。
关键词:对抗样本,Fooling images,fast gradient sign method(FGSM),Clever Hans,对抗防御,物理世界中的对抗样本,对抗训练,虚拟对抗训练,基于模型的优化
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture16.pdf
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~





