顺手训了一个史上最大ViT?Google升级视觉语言模型PaLI:支持100+种语言
![]()
新智元报道
新智元报道
【新智元导读】壕无人性!最近Google又利用钞能力,不仅将语言模型PaLM升级为视觉语言模型,还训了一个史上最大的ViT模型!|2022 IEEE北京国际女工程师领导力峰会重磅来袭,点击预约👇🏻
近几年自然语言处理的进展很大程度上都来自于大规模语言模型,每次发布的新模型都将参数量、训练数据量推向新高,同时也会对现有基准排行进行一次屠榜!
比如今年4月,Google发布5400亿参数的语言模型PaLM(Pathways Language Model)在语言和推理类的一系列测评中成功超越人类,尤其是在few-shot小样本学习场景下的优异性能,也让PaLM被认为是下一代语言模型的发展方向。
同理,视觉语言模型其实也是大力出奇迹,可以通过提升模型的规模来提升性能。
当然了,如果只是多任务的视觉语言模型,显然还不是很通用,还得支持多种语言的输入输出才行。
最近Google就将PaLM扩展升级成PALI(Pathways Language and Image model),兼具多语言和图像理解的能力,同时支持100+种语言来执行各种横跨视觉、语言和多模态图像和语言应用,如视觉问题回答、图像说明(image caption)、物体检测、图像分类、OCR、文本推理等。

论文链接:https://arxiv.org/abs/2209.06794
模型的训练使用的是一个公开的图像集合,其中包括自动爬取的109种语言的标注,文中也称之为WebLI数据集。
在WebLI上预训练的PaLI模型在多个图像和语言基准上取得了最先进的性能,如COCO-Captions、TextCaps、VQAv2、OK-VQA、TextVQA等等,也超越了先前模型的多语言视觉描述(multilingual visual captioning)和视觉问答的基准。
模型架构
模型架构
PALI的目标之一是研究语言和视觉模型在性能和规模上的联系是否相同,特别是语言-图像模型的可扩展性(scalability)。
所以模型的架构设计上就很简单,主要是为了实验方便,尤其是可重复使用且可扩展。
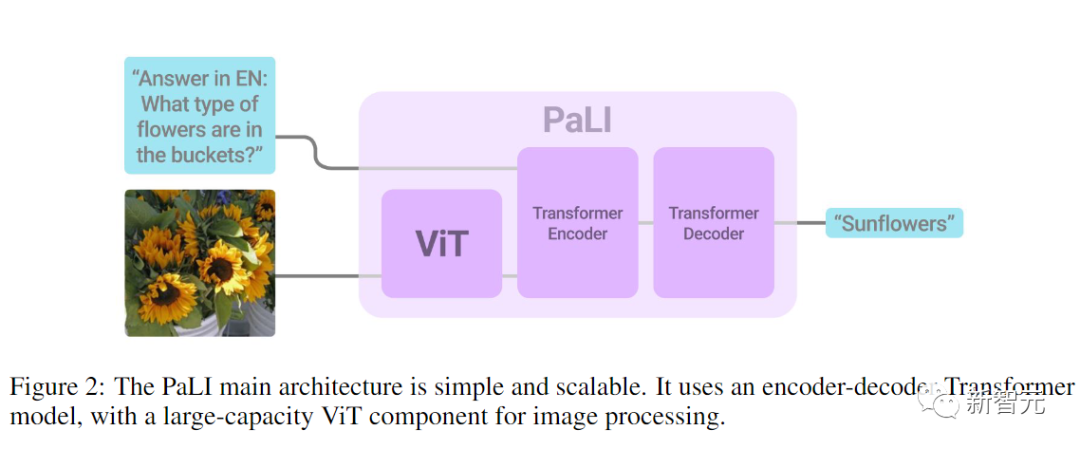
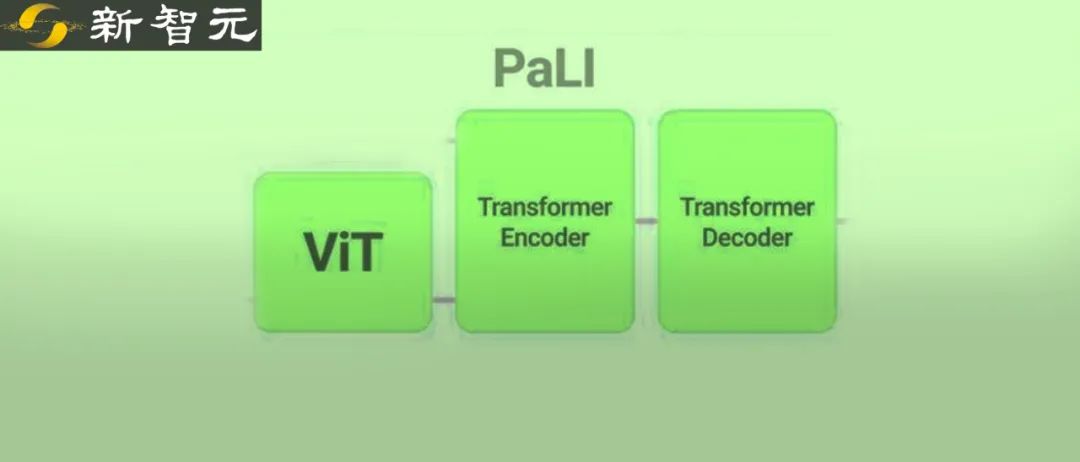
模型由一个处理输入文本的Transformer编码器和一个生成输出文本的自回归Transformer解码器组成。
在处理图像时,Transformer编码器的输入还包括代表由ViT处理的图像的视觉词(visual words)。
PaLI模型的一个关键设计是重用,研究人员用之前训练过的单模态视觉和语言模型(如mT5-XXL和大型ViTs)的权重作为模型的种子,这种重用不仅使单模态训练的能力得到迁移,而且还能节省计算成本。
模型的视觉组件使用的是迄今为止最大的ViT架构ViT-e,它与18亿参数的ViT-G模型具有相同的结构,并使用相同的训练参数,区别就是扩展为了40亿参数。
虽然在视觉领域和语言领域都对缩放规律进行了研究,但在视觉和语言的组合模型中对缩放行为的探讨较少,扩大视觉骨干模型的规模可能会导致在分类任务中的收益饱和。
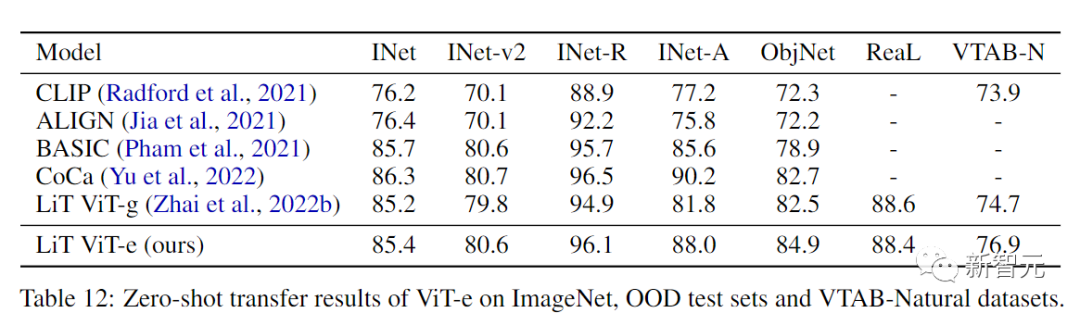
研究人员也进一步证实了这一点,可以观察到 ViT-e在ImageNet上只比ViT-G好一点,但ViT-e在PaLI的视觉语言任务上有很大的改进。例如,ViT-e在COCO字幕任务上比ViT-G多出近3个CIDEr点。任务上比ViT-G多出3分。这也暗示了未来在视觉语言任务中使用更大的ViT骨架模型的空间。
研究人员采用mT5骨干作为语言建模组件,使用预训练的mT5-Large(10亿参数)和mT5-XXL (130亿参数)来初始化PaLI的语言编码器-解码器,然后在许多语言任务中进行继续混合训练,包括纯语言理解任务,这也有助于避免灾难性的遗忘mT5的语言理解和生成能力。
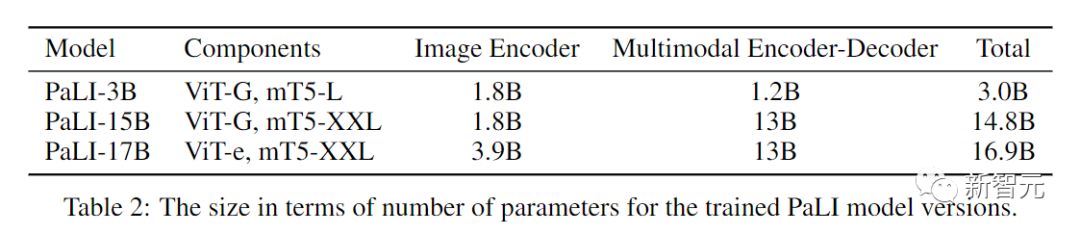
最后得到了三个不同尺寸的PALI模型。
109种语言的数据集
109种语言的数据集
深度学习相关的扩展研究表明,模型越大,所需的训练数据集也越大。
所以为了全面研究和释放语言-图像预训练模型的潜力,研究人员从互联网上爬取了大量的图像和文本数据,构建了一个全新的数据集WebLI,其中包括109种语言的120亿alt-texts和100亿张图片。
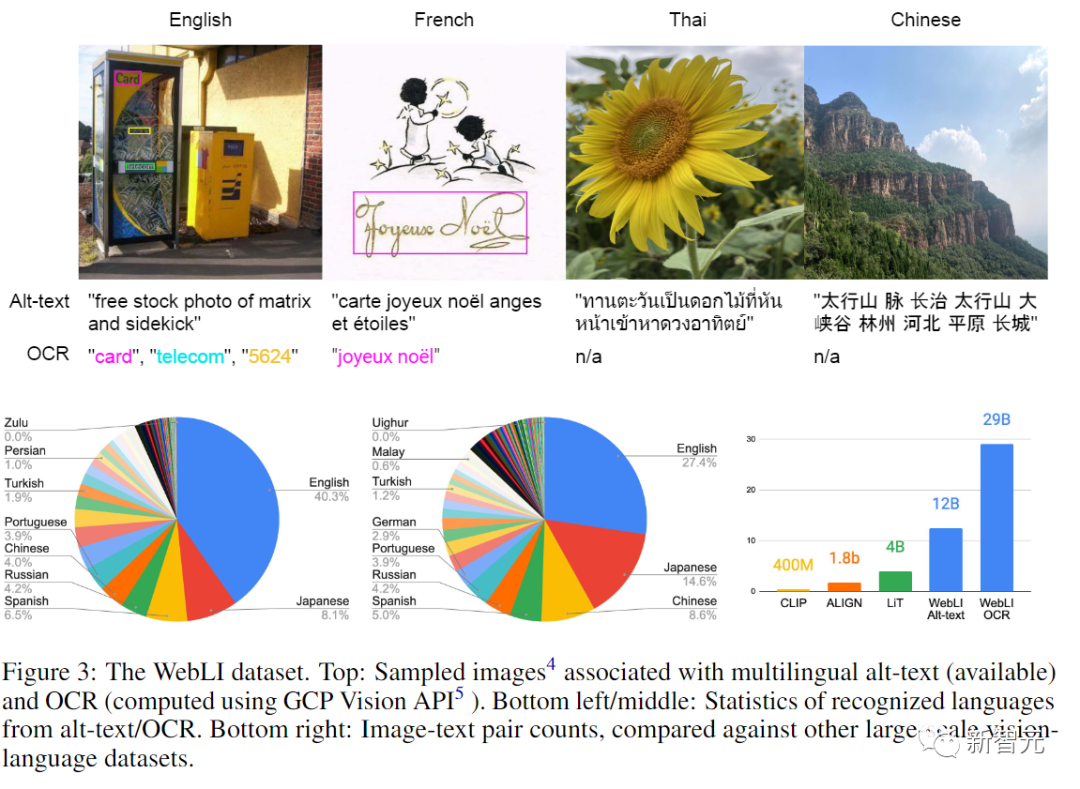
除了用网络文本进行标注外,研究人员还应用云端视觉API对图像进行OCR识别,进而得到290亿个图像-OCR的数据对。

使用near-duplication对68个常见的视觉和视觉语言数据集的训练、验证和测试部分的图像进行了去重处理,以避免下游评估任务的数据泄露。
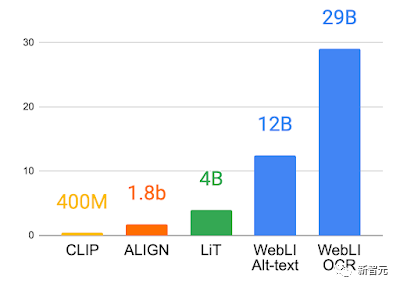
为了进一步提高数据质量,研究人员还会根据「图像和alt-text」的跨模态相似度进行评分,并调整阈值,最后只保留10%的图像,总共有10亿张图像用于训练PaLI
训练大模型
训练大模型
由于视觉-语言任务是多模态,所以需要模型具有多种语义处理能力,而且会有不同的目标。比如有些任务需要对物体进行局部定位以准确解决任务,而其他一些任务可能需要更多的全局语义信息。
同样地,有的语言任务可能需要长的答案,而有些则需要紧凑的答案。
为了解决所有这些不一致的目标,研究人员利用WebLI预训练数据的丰富性,引入预训练任务的混合(Pretraining Task Mixture),为各种下游应用准备模型。
为了让模型更通用以解决多种任务,作者将所有的任务归入一个单一的通用API(输入:图像+文本;输出:文本),使多个图像和语言任务之间能够进行知识共享,这也是与预训练设置的共享。
用于预训练的目标作为加权的混合被投影到同一个API中,目的是既保持重复使用的模型组件的能力,又能训练模型执行新的任务。
模型使用开源的T5X和Flaxformer框架在JAX中用Flax进行训练,视觉部分的ViT-e使用开源的BigVision框架,将语言部分的词向量与视觉部分生成的patch向量级联起来,共同作为多模态编码器-解码器的输入,编码器使用mT5-XXL预训练初始化。在PaLI的训练过程中,视觉组件的权重被冻结,只更新多模态编码器-解码器的权重。
在实验部分,研究人员在常见的视觉语言基准上对PaLI进行了比较,且PaLI模型在这些任务上取得了最先进的结果,甚至超过了以往文献中提出的超大型的模型。
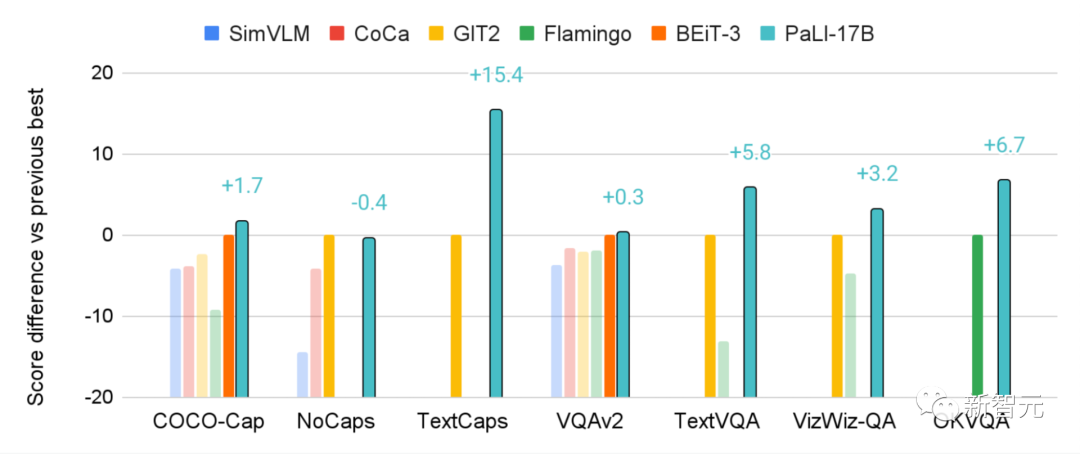
比如170亿参数的PALI在一些VQA和图像标题任务上的表现优于800亿参数的Flamingo模型。
并且PALI在单语言或单视觉的任务上也保持了良好的表现,虽然这并非是PALI主要的训练目标。
文中还研究了图像和语言模型组件在模型扩展方面是如何相互作用的,以及模型在哪里产生最大的收益。
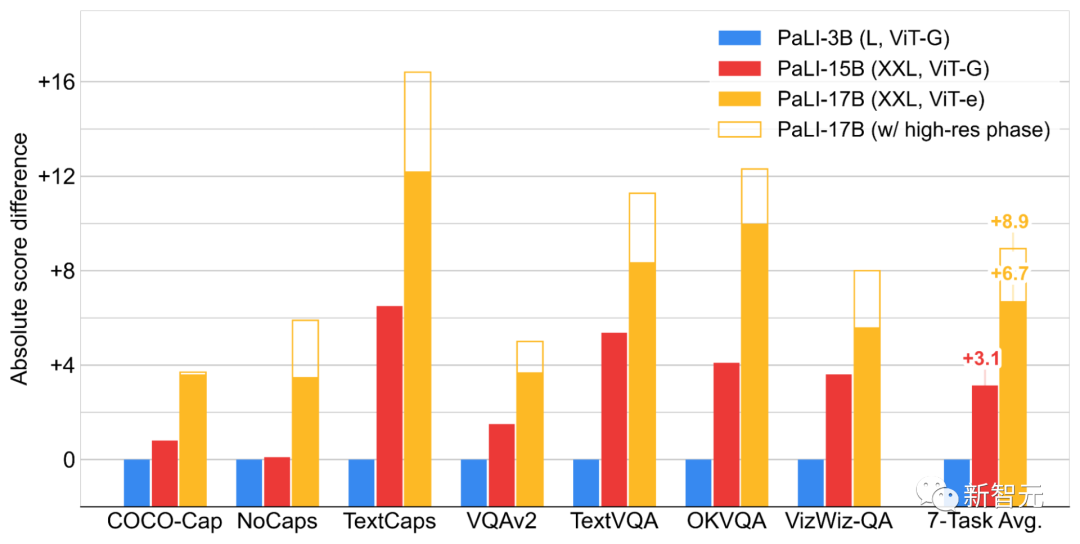
最后得出的结论是,对这两个组件进行联合扩展(缩放)会产生最好的性能,具体来说,对需要相对较少参数的视觉组件进行缩放是最关键的,同时缩放对于提高多语言任务的性能也很重要。
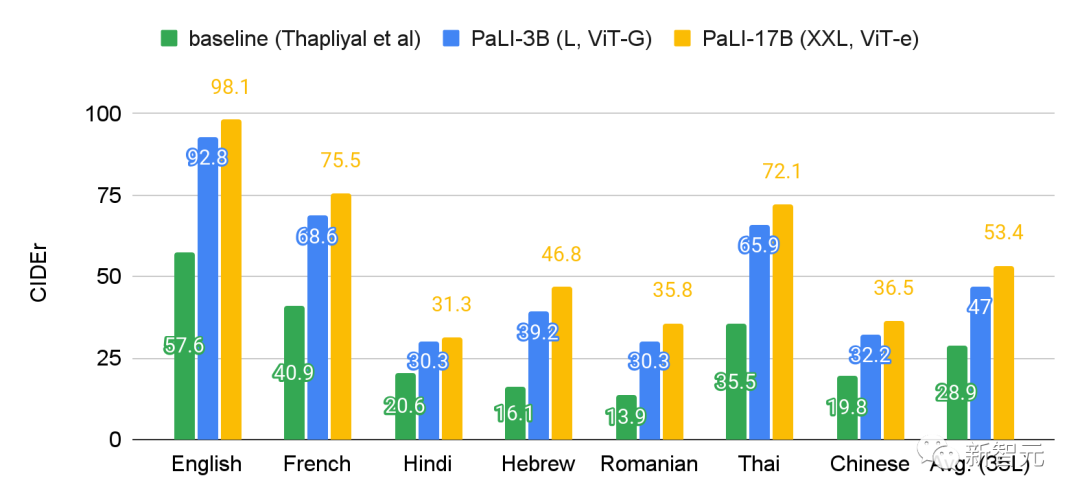
在35种语言的基准Crossmodal-3600上评估了PaLI后可以发现多语言起标题任务从PaLI模型的扩展中受益更多。
为了避免在大型语言和图像模型中产生或加强不公平的偏见,需要对所使用的数据和模型如何使用这些数据保持透明,以及测试模型的公平性并进行负责任的数据分析,所以文中同时提供了一个Data Card和Model Card