Partial FC:让你在一台机器上训练1000万个id人脸数据集成为可能!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI人工智能初学者

-
论文下载地址和代码开源地址:
https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc
https://arxiv.org/abs/2010.05222
本文彻底分析了基于softmax的损失函数的优化目标以及训练大量身份的难度,还实现了一种非常高效的分布式采样算法:PPRN,其仅使用八块RTX2080Ti来训练上千万个身份的分类任务。代码现已开源!
作者单位:格灵深瞳, 北邮, 湘潭大学等
1、简介和相关方法
我们都知道在人脸识别模型的学习过程中,模型会将数据集中每个人脸的特征映射到所谓的嵌入空间中,而在这个空间中,属于同一个人的特征被拉到一起,属于不同人的特征会被推开。同时也存在一个重要的法则是数据集提供的身份越多,模型的表征能力就越强。
在当前的研究进展中,很多关于损失函数的工作都是基于Softmax Loss或者其变体(如NormFace、ArcFace、Circle Loss、AdaCos等改进),虽然这些工作非常具有价值和实际意义,但是当数据集的id数量特别大的时候,其对于GPU的占用特别的大,也因此对于一个千万级别id的人脸数据集来说,训练一个基于Softmax Loss或者其改进形式作为损失的模型是非常耗时的。
基于上述问题,本文提出在所有GPU上,首先同样存储Softmax线性变换矩阵的非重叠子集。然后,每个GPU都负责计算被存储在自己内存的采样子矩阵的点积的和。之后,每个GPU将本地和从其他GPU收集到近似全类softmax函数。通过只与本地采样和进行通信,可以只使用少量的通信来近似Softmax。该方法大大降低了每个GPU的通信、计算和存储成本。从多个数据集的实验结果显示该方法在只使用了10%的类来计算softmax可以达到SOTA的水平。
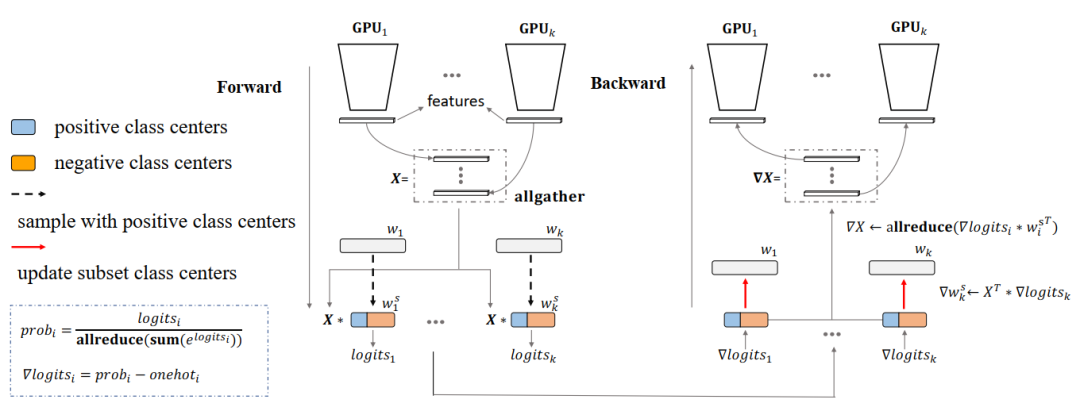
2、本文方法
2.1、模型并行化分析
在没有使用并行模型的情况下,训练具有大量身份的模型比较困难,这受制于单一显卡的内存容量。softmax权重 矩阵存储存在瓶颈。打破瓶颈的一种最为直接的方法是将W划分为k个子矩阵w;因此,为了计算最终的softmax输出,每个GPU必须从所有其他GPU收集权重,因为权重在不同的GPU之间被分割。

并行模型可以完全解决w的存储和通信问题,因为无论C多大都可以轻松地增加更多的GPU。然而,w并不是唯一存储在GPU内存中的。predicted logits的存储会受到总批大小的增加的影响。基于模型并行化的问题和发现(详细见论文分析),提出近似的策略。
2.2、Approximate Strategy
2.2.1、Roles of positive and negative classes
Softmax Loss可以表示为:
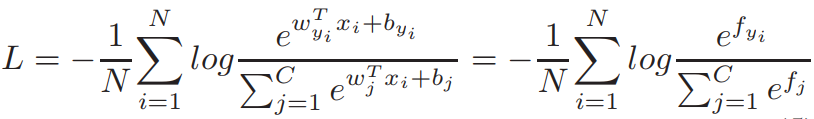
其中, 表示第i个sample,C表示class number,N表示Batch Size, 表示第j个W权重;
通常表示为具有权重向量 和偏置 的全连通层的激活函数,这里设置bias为0:
其中
是特征
和权重
之间的角度,本文所提方法对
和
进行
正则化,同时把
rescale为s;这里特征和权值的归一化步骤可以使预测只依赖于特征和权值之间的角度。
线性变换矩阵的每一列都被视为类中心,矩阵的第j列对应于类j的类中心。在这里将
表示为
的正类中心,其余为负类中心。通过对softmax表达式的分析,得出以下假设:
如果想通过选择类中心的子集来近似softmax,则必须选择正类中心,而负类中心只需要从所有的子集中选择,通过这样做,可以保证模型的性能。
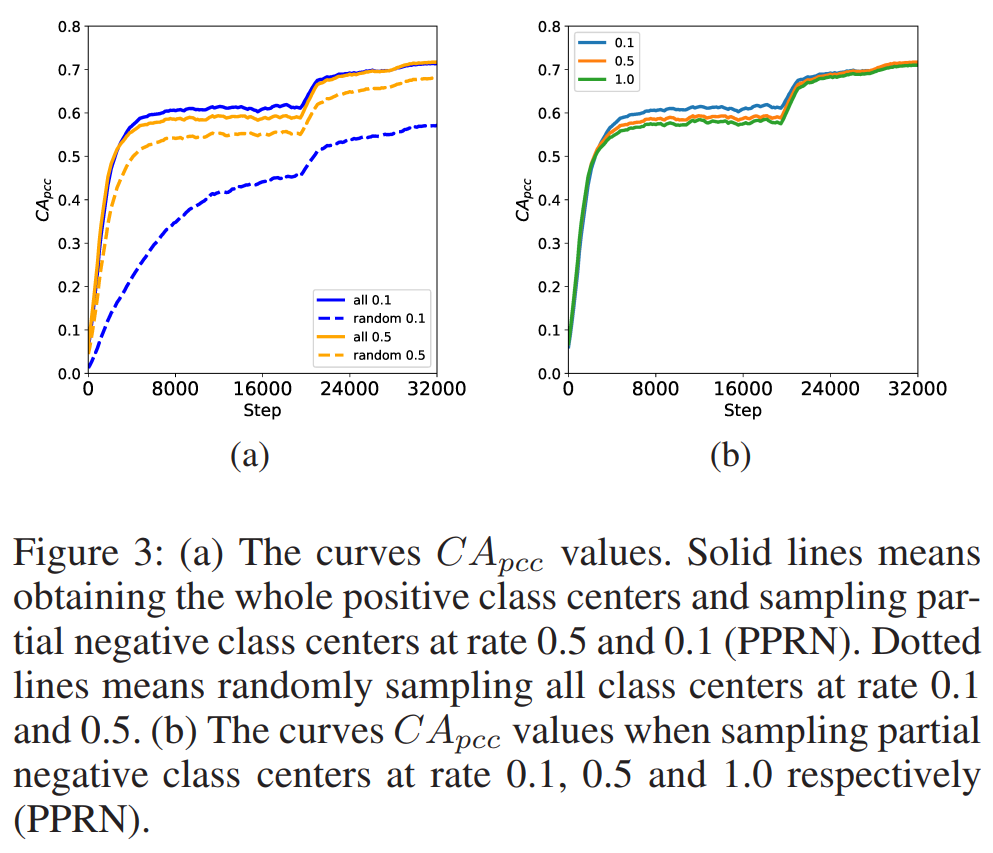
文中用两个实验来证明这个假设。在每次实验中,只采样一定百分比的类中心来计算每次迭代中近似的softmax损失:
第一个实验:主要选取当前批次中与输入特征相对应的所有正类,然后对负类中心进行随机采样。将这种抽样策略简称为(PPRN)。
第二个实验:从所有的类中心进行随机选择。两个实验的采样率都设置为0.1和0.5。
在训练过程中,将
和
的平均余弦距离定义为
:
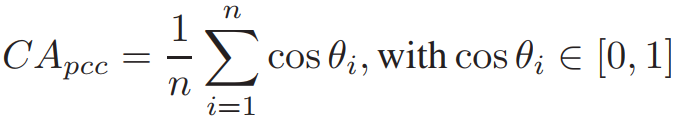
2.2.2、Distributed Approximation
如前所述只有类中心的一个子集可以实现比较好的性能。为了训练具有大量恒等式的训练集,提出了一种分布逼近方法。抽样子集类中心的过程如下:
-
1、选择正类中心 -
2、随机抽样负类中心
在模型并行的情况下,为了平衡每个GPU的计算和存储,每个GPU上采样的类中心数应该相等,因此采样过程改变如下:
1、获得这个GPU上的正类中心
W将按顺序平均分到不同的GPU,如W=[w1, w2,…, wk],k为GPU数量。当知道样本
的标记
时,它的正类中心是W线性矩阵的第i列。因此,通过对当前批处理中的特征进行标记y,可以很容易地获得当前GPU上的正类中心
。
2、计算负类中心数
根据前面的信息,该GPU上存储的类中心数为
,正类中心数为
,则该GPU上需要随机采样的负类中心数为
3、随机抽样负类
通过在
和
的差集中随机采样
的负类中心。最后,得到所有参与softmax计算的类中心
,其中
。实际上,该方法是一种近似的方法来获得每个GPU的负载均衡。
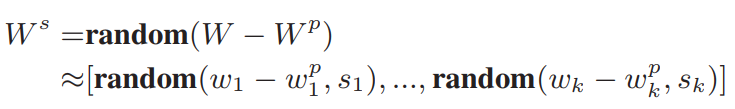
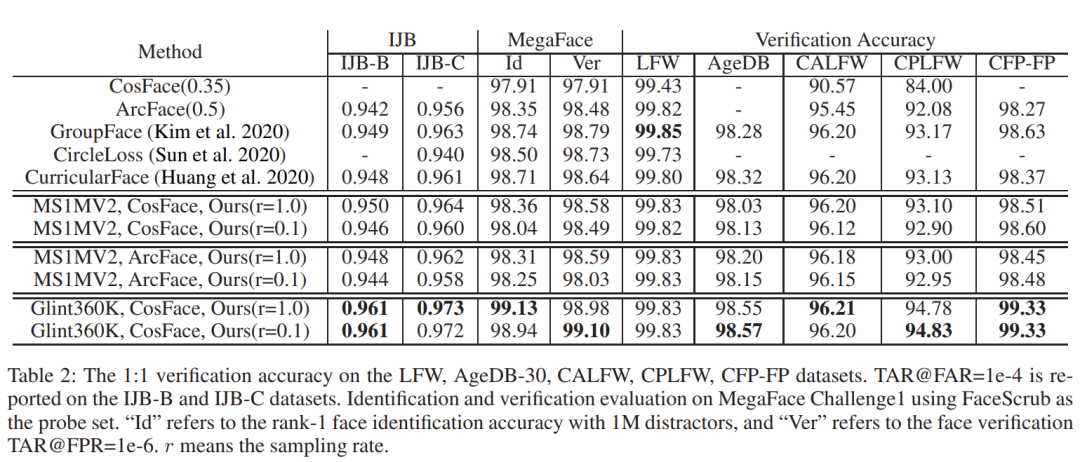
3、实验结果
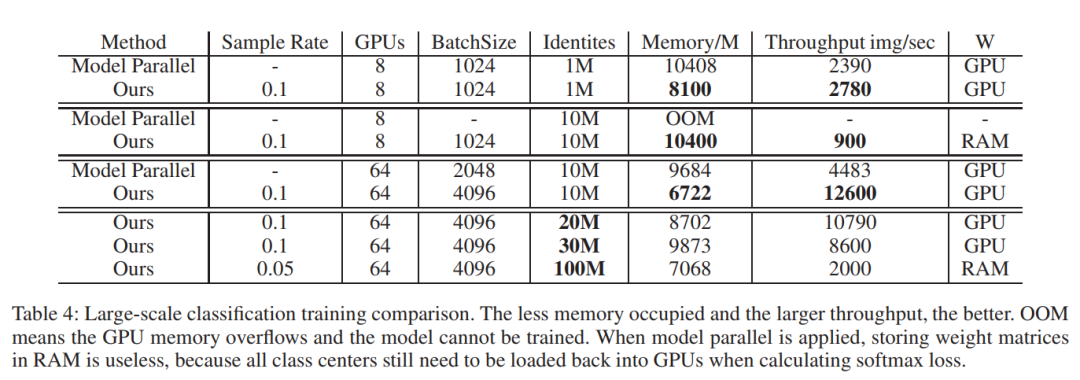
更为详细内容可以参见论文中的描述。
References
[1] Partial FC:Training 10 Million Identities on a Single Machine
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-人脸交流群成立
扫码添加CVer助手,可申请加入CVer-人脸 微信交流群,目前已满900+人,旨在交流人脸识别、检测、活体检测等。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如人脸+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



