GroupSoftmax:利用COCO和CCTSDB训练83类检测器
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:程萝卜
链接:https://zhuanlan.zhihu.com/p/73162940
本文获作者授权转载,不得二次转载。
通常,CV算法工程师在利用YOLO,Faster RCNN,CenterNet等一系列detection算法对公司的业务数据一顿猛train,看到自己的模型用在了业务上,陶醉在CEO对自己的工作很满意、即将升职加薪的幻觉之中时,往往迎来的是CEO的灵魂拷问。考虑如下问题:
CEO总是逼我,说客户关心某一个新的类别:对于一个n类检测数据集和一个m类检测数据集,想要得到一个n+m类检测模型。实际生产环境中,已经标注完成的数据集,因为业务需要增加k个新的检测类别。但不希望对已有数据重新标注,而是只标注接下来新的数据。
CEO总是逼我,说客户希望把某一类别分成两种情况对待:上一个问题再进一步推广,因为业务需要,数据的标注标准发生改变,比如将过去某个类别拆分为多个新的类别。但不希望对已有数据重新标注,而是只标注接下来新的数据。
CEO总是逼我,说标注成本太高,公司要倒闭:对于一个长尾分布的数据集,标注成本往往是巨大的,我们希望收集那些少数类别样本,但是在标注时遇到了多数类别样本,也要花很大的代价进行标注。是否有办法能够对于那些简单的样本类别,选择不进行标注,只标注有价值的少数类别目标。
为了讨好CEO,我们设计了GroupSoftmax交叉熵损失函数,能够有效解决上述3个问题。如下图所示,GroupSoftmax交叉熵损失函数允许类别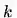
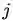
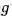
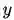
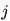
softmax交叉熵损失函数和groupsoftmax交叉熵损失函数的梯度对比图,在groupsoftmax中,类别k和类别j能够进行组合,形成一个新的类别g,以此计算相应的梯度
我们利用了80类检测数据集COCO和3类检测数据集CCTSDB联合训练,基于Faster RCNN算法(SyncBN),联合训练得到了一个83类检测器,在coco_minival2014测试集上,GroupSoftmax交叉熵损失函数和原始的Softmax交叉熵损失函数训练效果相比,mAP由原来的38.6上升到了39.3,也就是说我们利用了一个与COCO无关的CCTSDB数据集,将检测指标提高了0.7个点,还同时能够完成更多的类别检测任务,这算是比较理想的。此外,我们还训练了一个trident*模型,6个epoch在coco_minival2014测试集上的mAP为44.0,由此可见GroupSoftmax交叉熵损失函数是切实有效的。理论上而言,利用GroupSoftmax交叉熵损失函数,可以无限添加不同标注标准的数据集,进行联合训练。


我们基于SimpleDet检测框架,实现了mxnet版本的GroupSoftmax交叉熵损失函数,源码地址为:https://github.com/chengzhengxin/groupsoftmax-simpledet,欢迎试用。下面详述GroupSoftmax交叉熵损失函数的工作原理。
GroupSoftmax交叉熵损失函数的推导
翻开任意一篇介绍softmax交叉熵损失函数的文章,都能看到,损失
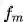

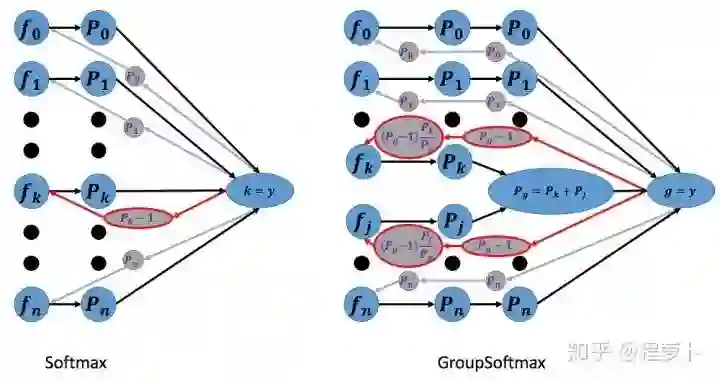
一般地,我们采用交叉熵损失函数处理分类问题,使用式(1)中得到的梯度,已经能够满足识别分类等算法任务的训练。但是在真实情况中,我们有时候无法确定类别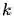
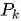

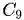

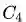

GroupSoftmax交叉熵损失函数的定义为如下,为群组

式(2)中,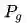
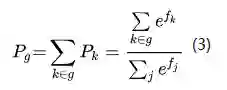
如上文提到的,在数据集B中,类别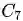
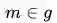

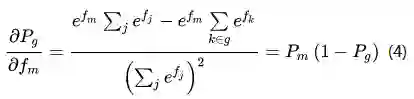
同理,考虑式(3)中的情况,当 
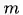
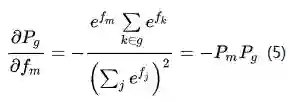
由式(2)、式(4)、式(5),可以得到GroupSoftMax交叉熵损失函数对激活值 
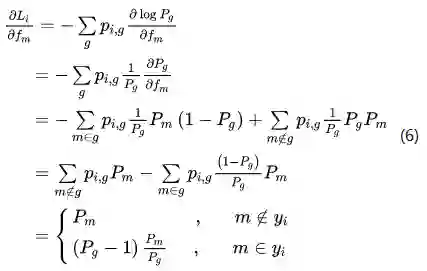
式(6)中,
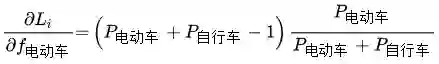
可以看到,对比式(1)和式(6),得出的结论非常的make sense,对于一个群组类别中的子类别而言,其对应的梯度为群组类别的梯度乘以相应的权重,权重取值为当前子类别的预测概率 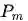

工程实现需要注意的细节
1、对于某一个数据集中的未进行标注的类别,可以理解为和背景一起作为新的群组类别。
2、在two-stage检测算法中,用于提取proposal的RPN网络通常是2分类网络,因为只用于区分前景和背景,但是对于某些类别未标注的数据集,是无法正确区分前景和背景的。此时需要将RPN网络修改为多分类。比如COCO+CCTSDB联合训练时,COCO中是一种前景,CCTSDB中是另外一种前景,所以此时的RPN应该修改为3分类,如下图所示:

3、COCO(80)+CCTSDB(3)联合训练时,最终的分类任务为1+83类,对于某个数据集中未标注的类别,比如COCO中未标注的3类,可以和背景类组成一个组合类别。如下图所示:

4、编写CUDA代码时,计算群组类别的概率 

GroupSoftmax的CUDA代码请参考:
https://github.com/chengzhengxin/groupsoftmax-simpledet/blob/master/operator_cxx/contrib/group_softmax_output.cu
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



