不用重新训练,直接将现有模型转换为 MobileNet
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | autocyz
来源 | https://zhuanlan.zhihu.com/p/54425450
原文 | http://bbs.cvmart.net/articles/301
从MobileNet中的深度可分卷积(Depthwise Separable Convolution)讲起
看过MobileNet的都知道,MobileNet最主要的加速就是因为深度可分卷积(Depthwise Separable Convolution)的使用。将原本一步到位的卷积操作,分为两个卷积的级联,分成的两个卷积相对于原始的卷积而言,参数大大减少,计算量大大减少。
1、标准卷积:

2、深度可分卷积:
深度可分卷积是将原来的一个卷积,分解成两个不同的卷积,每个卷积的功能不一样。一个在feature map进行卷积,一个在通道上进行卷积。

3、深度可分卷积的pytorch实现:
def conv_dw(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)将训练好的卷积模型转换为深度可分卷积
既然有了深度可分卷积,并且这个卷积方法可以在不改变特征输入输出大小的基础上极大减少参数量和计算量,那么我们当然会想着把已有模型中的标准卷积换成深度可分卷积。可是,在替换成深度可分卷积时,实际上模型由原来的一个卷积变成了两个卷积,模型结构已经发生了变化,所以我们需要对转换后的深度可分卷积模型重新训练。这就要求我们有足够的数据,足够的时间重新训练。
有没有什么方法能够不重新训练模型,直接将已有的训练好的模型,转换成深度可分卷积呢?
答案是:有!
接下来要讲的方法就是出自文章:https://arxiv.org/abs/1812.08374?context=cs
文章流程图:
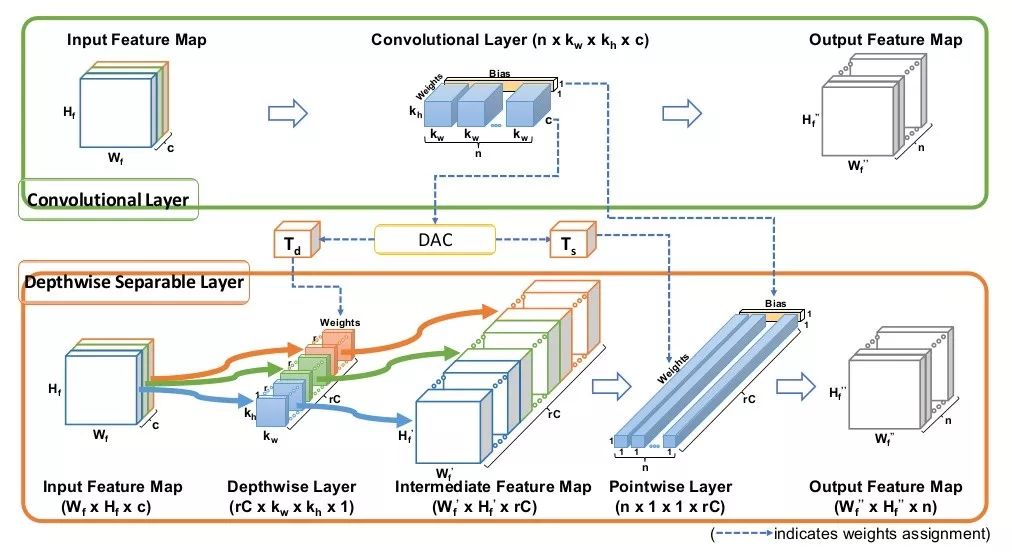
文章思想:
文章思想很简单,通过使用作者提出的DAC方法,直接将一个标准卷积的权植,分解成两个卷积

MobileNet中可分离卷积的区别:
乍一看这种分解出来的结果和可分离卷积形式一样,实则不然,具体区别有两点:
MobileNet的深度可分卷积在depthwise和pointwise之间有BN和激活层,而DAC分解的则没有。
MobileNet的深度可分卷积在depthwise阶段,每个输入channel,只对应一个卷积核,即depthwise阶段卷积核的大小为
,而DAC中每个输入channel对应了 r 个卷积和,所以此阶段总的卷积核大小为
同理,在pointwise阶段,两种方法的卷积核大小也不一样。


具体方法:
作者在文章中给出了非常清晰的算法流程,中间用到了SVD分解的方法获取主成分。具体方法如下:

计算量的减少:
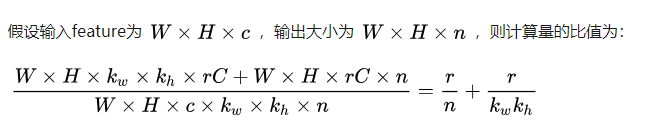
实验分析:
作者做了两个探究性实验,探究了分解哪些层对模型的影响最大,并且在物体分类、物体检测、pose estimation上都做了迁移测试。这里讲一下两个有意思的探究性实验,其他迁移实验可以去文章细看。
实验一:验证分解单个层并且使用不同的rank(即上面说的分解因子 r )对模型整体性能的影响。
作者对CIFAR-VGG模型的不同卷积层进行DAC分解,每次只分解一个卷积层,得到如下结果:

结论:
1、使用较小的rank,比如rank=1时,分解前面的层(例如conv2d_1)会导致模型精度损失特别厉害(93.6->18.6),而分解后面的层(conv2d_13)则不会损失很多(93.6->92.9).
2、越大的rank,精度损失的越小。比如在conv2d_1阶段,rank5 的精度远远高于rank1.
实验二:验证分解前k个层和后k个层对模型精度的影响
前k个层就是从第一个到第k个, 后k就是从最后一个到导数第k个

结论:同等条件下(相同的rank),分解网络后面的层产生的精度损失会小于分解网络前面的层。
总结
方法非常简单使用,而且又很容易迁移到各种模型上去。最最主要的是,直接对训练好的model进行分解,不必再重新训练了。省时又省力,美滋滋。
[1] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[2] Li X, Zhang S, Jiang B, et al. DAC: Data-free Automatic Acceleration of Convolutional Networks[J]. arXiv preprint arXiv:1812.08374, 2018.
*延伸阅读
ECCV2018|ShuffleNetV2:轻量级CNN网络中的桂冠
过往Net,皆为调参?一篇BagNet论文引发学界震动
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~



