一个模型翻译103 种语言!谷歌500亿参数M4模型突破多语言神经翻译极限

新智元报道
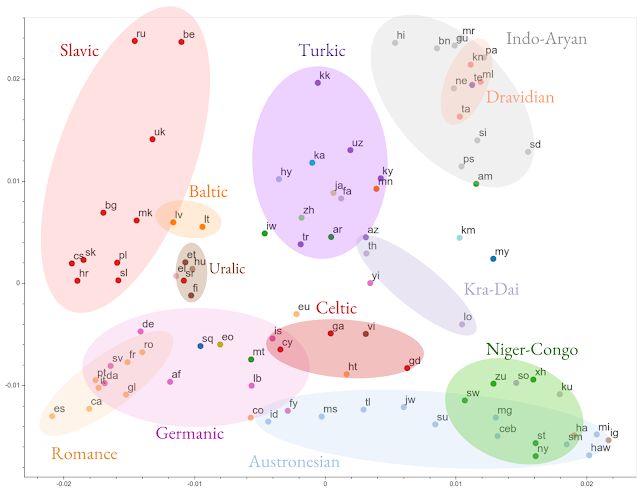
【新智元导读】谷歌最新研究提出一种用于大规模多语言的大规模神经翻译方法,针对100+种语言,超过500亿参数训练一个NMT模型,突破了多语言NMT研究的极限。>>> 如何看待这一突破,来新智元 AI 朋友圈和AI大咖一起讨论吧~






登录查看更多
相关内容
专知会员服务
11+阅读 · 2019年12月28日
Arxiv
5+阅读 · 2018年6月5日
Arxiv
5+阅读 · 2018年4月16日
Arxiv
3+阅读 · 2018年4月8日


相关VIP内容
专知会员服务
11+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年6月5日
Arxiv
5+阅读 · 2018年4月16日
Arxiv
3+阅读 · 2018年4月8日