每日三篇 | NIPS 2018关于神经网络训练方面的论文
Training DNNs with Hybrid Block Floating Point
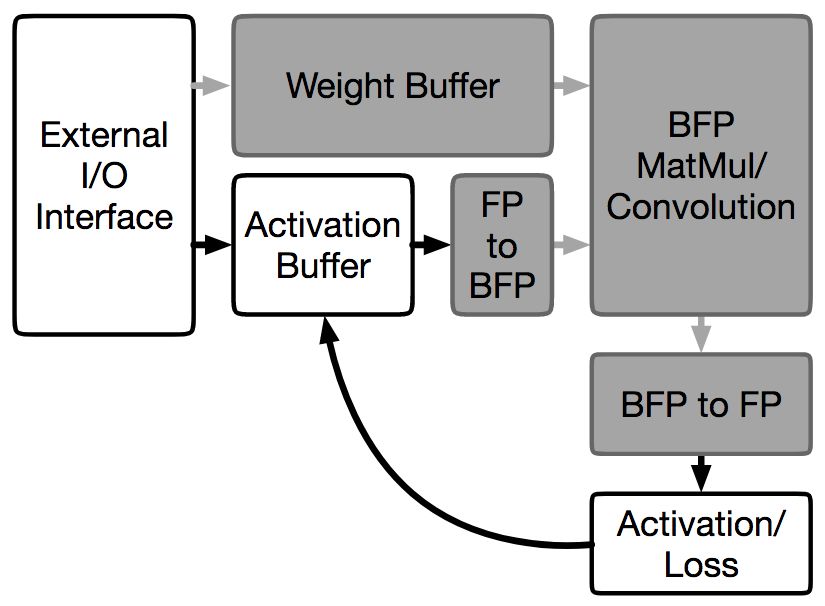
洛桑联邦理工学院的Mario Drumond、Tao LIN、Martin Jaggi、Babak Falsafi在NIPS 2018上发表了一种混合BFP和FP的深度神经网络训练方法HBFP。HBFP在所有点积运算上使用块浮点数(BFP),其他运算上则使用浮点数(FP)。在保持与浮点数相当的精确性的前提下,HBFP使硬件实现的吞吐量可以提高至8.5倍。
地址:http://papers.nips.cc/paper/7327-training-dnns-with-hybrid-block-floating-point
How to Start Training: The Effect of Initialization and Architecture
德州农工大学的Boris Hanin和MIT的David Rolnick在NIPS 2018上报告了他们对深度ReLU网络训练早期两种常见失败模式的研究。他们给出了何时出现这两种模式,以及在全连接网络、卷积网络、残差架构中如何避免这两种模式的严格证明。
地址: http://papers.nips.cc/paper/7338-how-to-start-training-the-effect-of-initialization-and-architecture
Training Deep Models Faster with Robust, Approximate Importance Sampling
在理论上,重要性采样可以加速监督学习所用的随机梯度下降算法。然而,在实践中很少有人这么做,因为计算重要性的成本很高。华盛顿大学的Tyler B. Johnson、Carlos Guestrin在NIPS 2018上发表了一种称为RAIS的重要性采样过程。通过使用鲁棒优化逼近理想的采样分布,RAIS在提供精确重要性采样的许多益处的同时大大降低了计算开销。
地址:http://papers.nips.cc/paper/7957-training-deep-models-faster-with-robust-approximate-importance-sampling