ICLR 2019论文解读:量化神经网络
机器之心原创
作者:Joshua Chou
参与:Haojin Yang、Panda
今年五月举办 ICLR 2019 会议共接收论文 502 篇,本文将解读其中两篇有关量化神经网络的研究。
UNDERSTANDING STRAIGHT-THROUGH ESTIMATOR IN TRAINING ACTIVATION QUANTIZED NEURAL NETS
https://openreview.net/pdf?id=Skh4jRcKQ
ANALYSIS OF QUANTIZED MODELS
https://openreview.net/pdf?id=ryM_IoAqYX
深度神经网络(DNN)已经极大推升了机器学习(ML)/人工智能(AI)在许多不同任务中的性能,并由此带来了许多我们日常生活中所见的成熟应用。经典案例包括图像目标识别(Krizhevsky et al., 2012; Szegedy et al., 2014)、语音识别(Hinton et al., 2012; Sainath et al., 2013)、统计机器翻译(Devlin et al., 2014; Sutskever et al., 2014; Bahdanau et al., 2015)和掌握围棋(Silver et al., 2016)。
神经网络包含两部分:训练和推理。由于计算神经元输入的加权和以及执行神经网络所需的运算需要大量乘法-累加运算(MAC),所以在传统的(通用型)数字硬件上训练神经网络以及使用神经网络执行推理的效率很低。
DNN 基本上都是在一个或多个图形处理单元(GPU)上训练的。本质上而言,GPU 速度很快且支持高度并行,但功耗却很高。此外,一旦模型训练完成,仍然很难在手持设备等低功耗设备上运行训练后的网络。因此,人们投入了大量研究精力,想要在通用和专用计算硬件上加速 DNN 的运行。
理解训练激活量化网络中的直通估计器(Understanding Straight-Through Estimator in Training Activation Quantized Neural Nets)
引言
使用直通估计器(STE)的理由可以通过一个简单实例进行说明。设有一个简单的阈值函数——ReLU 函数,即 f(x) = max(0,x)。此外,设网络一开始就有某套初始权重。这些 ReLU 的输入(乘上了权重的信号)可以是负数,这会导致 f(x) 的输出为 0。
对于这些权重,f(x) 的导数将会在反向传播过程中为 0,这意味着该网络无法从这些导数学习到任何东西,权重也无法得到更新。STE 的概念也由此而来。STE 会将输入的梯度设置为一个等于其输出梯度的阈值函数,而不管该阈值函数本身的实际导数如何。有关 STE 的最早研究(Bengio et al. 2013)请见:
https://arxiv.org/pdf/1308.3432.pdf
这篇论文使用了「粗粒梯度(coarse gradient)」这个术语来指代通过「经 STE 修改的链式法则」而得到的损失函数在权重变量方面的梯度。通过选择这种非一般的梯度,问题就变成了:STE 梯度并非该损失函数的实际梯度(实际上,STE 梯度不是任何函数的梯度),为什么在其负方向搜索有助于最小化训练损失?此外,该如何选择一个「好的」STE?
这篇论文讨论了通过二元激活和高斯数据学习二层线性层网络的三种代表性 STE。作者还证明选择适当的 STE 能得到表现优良的训练算法。
我选择解读这篇论文的原因是想要详细解读使用 STE 的权重更新的梯度。直接复制这些公式进行使用当然完全可以,但是我希望能围绕数学进行解读,并能提供一些这种数学过程为何有效的见解。
在继续解读之前,我们先看看这篇论文所使用的符号表示方式:
|| ⋅ || 表示一个向量的欧几里德范数或一个矩阵的谱范数
0_n ∈ R^n 表示全为零的向量
1_n ∈ R^n 表示全为一的向量
I_n 是 n 阶单位矩阵
<w, z> = (w^T)z 表示 w, z ∈ R^n 的内积
w⊙z 表示哈达玛积(Hadamard product,也被称为 entry-wise product)
使用二元激活学习二层线性层 CNN
模型设置和问题构建
考虑以下模型:
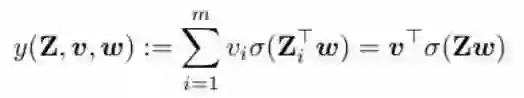
其中 Z ∈ R^(mxn) 是输入,w ∈ R^n 和 v ∈ R^n 分别是第一和二层线性层的权重。(Z_i)^T 表示 Z 的第 i 行,σ( ⋅ ) 是在向量 Zw 上逐分量工作的激活函数。第一层用作卷积层,第二线性层用作分类器。标签根据 y*(Z) = (v*)^T σ(Zw*) 生成,其中 v* 和 w* 是一些最优参数。式 (1) 描述了损失函数,其就是一个简单的平方损失:
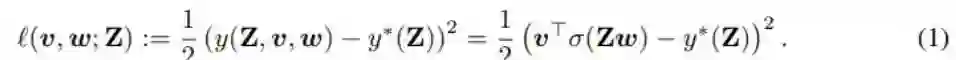
σ( ⋅ ) 被取为一个二元函数,即 σ( x ) = 1_{x>0}。Z ∈ R^(mxn) 的项是独立同分布地(i.i.d.)采样自一个高斯分布 N(0,1)。不失泛化性能,我们将假设 || w || = 1 并将优化问题构建成 (2) 式形式:
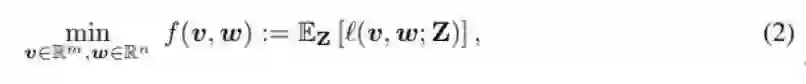
反向传播和粗粒度梯度下降
(2) 式是对问题的数学描述,即最小化 (1) 式中定义的损失函数与 Z 相关的期望。注意,由于对 Z 的高斯假设,所以取期望是可能的。获取的梯度信息由下式给出:
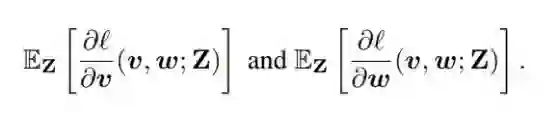
其中期望中的表达式由 (3) 和 (4) 式描述。
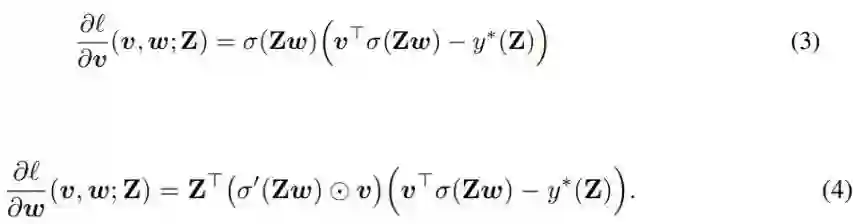
注意 (4) 式中的 σ' 为零,会导致反向传播过程中不会传播信息。也就是说,如果使用标准的梯度下降更新规则,网络将什么也学习不到。STE 的思想很简单,就是用一个相关的非平凡函数 µ' 替代 (4) 式中的零分量 σ',其中 µ' 是某个次(可微分)函数 µ 的导数。也就是说,使用 STE µ' 的反向传播会为 (∂l / ∂w)(v, w; Z) 提供一个非平凡的表达。这就是作者称之为粗粒梯度(coarse gradient)的东西,如 (5) 式所示。
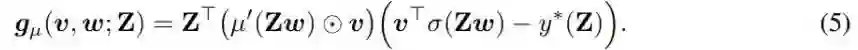
然后,将这个粗粒梯度插入到标准梯度下降更新规则中,就得到了算法 1 所示的梯度下降算法。

注意这只是用 g_µ(v^t, w^t; Z) 替换了时间 t 的真实梯度 (∂l / ∂w)(v, w; Z),其中的 t 是指时间步骤(或迭代)。
分析——计算梯度
让我们更进一步深入群损失函数 f(v, w) 及其梯度 ∇ f(v, w)。首先,将两个向量 w 和 w* 之间的角度定义为:对于任意 w ≠ 0_n,有
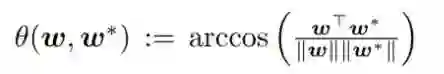
这在后面会用到,因为这被用于描述两个带有高斯项的向量的一个积的期望。arccos(⋅) 中的参数是 w 和 w* 的内积除以 ||w|| ||w*||,这是 w 和 w* 之间的余弦角。这两个向量越近,这个角就越小。
现在来看式 (1) 和 (2) 中描述的 f(v, w),我们可以取式 (1) 的转置,因为一个标量的转置还是一样,将所得到的表达式放入 (2) 中,然后扩展得到(不正确的)表达式如下(下一段会说明这个错误):
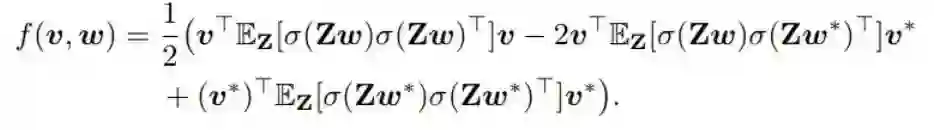
现在的目标是使用分析表达式替换表达式 E_Z[ σ(Zw) σ(Zw)^T ]、E_Z[ σ(Zw) σ(Zw*)^T ] 和 E_Z[ σ(Zw*) σ(Zw*)^T ]。读者应该把这个牢记在心,不然下一节会很吃力。
因此,(v*)^TZw* 就等于 y*(Z),即为标签。如果我们查看这个 (m x m) 矩阵 E_Z[ σ(Zw) σ(Zw)^T ]。当 i≠j 时,EZ[ σ(Zw) σ(Zw)^T ] 的元素为 E[ σ(**Zi^Tw) σ(Zj^Tw) ],并且可以写成 E[ σ(Zi^Tw) ] E[ σ(Zj^Tw) ]。而当 i=j 时,元素为 E[ σ(Zi^Tw) ] E[ σ(Zi^Tw) ] = ( E[ σ(Zi^Tw) ] )^2。其中 Z_i**^T 是指 Z 的第 i 行。
现在我们可以按下式求得对角元素:
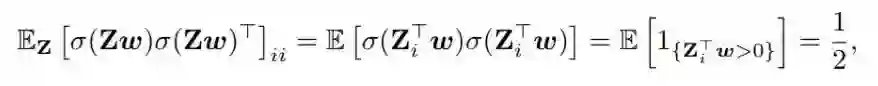
为什么会得到第二个等式?我会尝试给出一些见解。首先,注意 σ(Z_i^Tw) 就是 1_{Z_i^Tw},这是一个指示函数。有一个参数 x 的指示函数 1_{x} 在与自身相乘时会保持不变,因此会得到第二个等式。
最后一个等式源自一个高斯分布的统计情况。将 w 固定为 R^n 中的任意向量,则其元素是分布为 N(0,1) 的高斯随机变量的向量 Z_i 将与 w 形成一个锐角的概率是 0.5。
因此,每个元素都有 0.5 的概率为 1,得到总的期望为 (0.5)x1 + (0.5)x0 = 1/2。我们可以考虑这个例子的极限情况,即仅有 1 个维度的情况。令 w 为任意正数,z 为一个高斯随机变量 ~N(0,1),则 P [ 1_{w x z > 0} ] = P[ 1_{w x z < 0} ] = 0.5。
对于 i≠j 的情况,E[ σ(Z_i^Tw) σ(Z_j^Tw) ] = E[ σ(Z_i^Tw) ] E[ σ(Z_j^Tw) ],而且因为 Z_i 和 Z_j 是独立同分布,所以这两个期望是独立的且每一个都估计为 1/2。使用这一观察,我们可得以下结果:
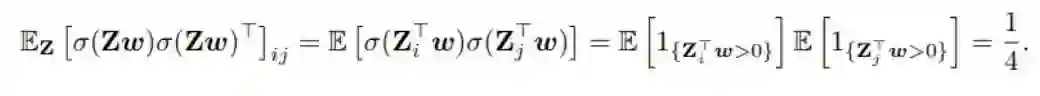
因此,我们可以综合以上结果得到表达式:
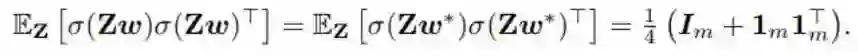
也就是说,E_Z[ σ(Zw) σ(Zw)^T ] 沿对角的元素等于 1/2,其它地方为 1/4。E_Z[ σ(Zw*) σ(Zw*)^T ] 也有一样的参数。
最后,对于元素为 E_Z[ σ(Zw) σ(Zw*)^T ]_{i, j} 的矩阵,如果 i≠j,则由于独立同分布的假设,该期望可以被分解和独立地评估。这会得到 E_Z[ σ(Zw) σ(Zw*)^T ]_{i, j} = E[ σ(Z_i^Tw) ] E[ σ(Z_j^Tw*) ] = 1/4.
对于 i=j 的情况,我们有如下结果:
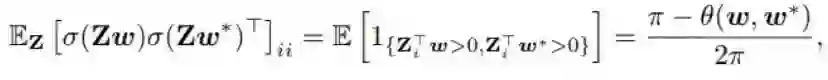
其中 θ(w, w*) 是 w 和 w* 之间的夹角。
主要结果与分析
这篇论文主要关注的是算法 1 中总结的粗粒梯度下降的行为。其研究了 STE 被设置为基本 ReLU、截断式 ReLU(clipped ReLU)和恒等函数的导数的情况。这篇论文证明通过使用普通或截断式 ReLU 的导数,算法 1 会收敛到一个临界点;而使用恒等函数则不会。
作者在论文中给出一个说明,其表示粗粒梯度下降的收敛保证基于训练样本无限的假设。在仅有少量数据时,在粗粒尺度上,实验损失大致会沿负粗粒梯度方向下降。随着样本规模增大,实验损失会变得单调和平滑。图 1 给出这一思路的图示。
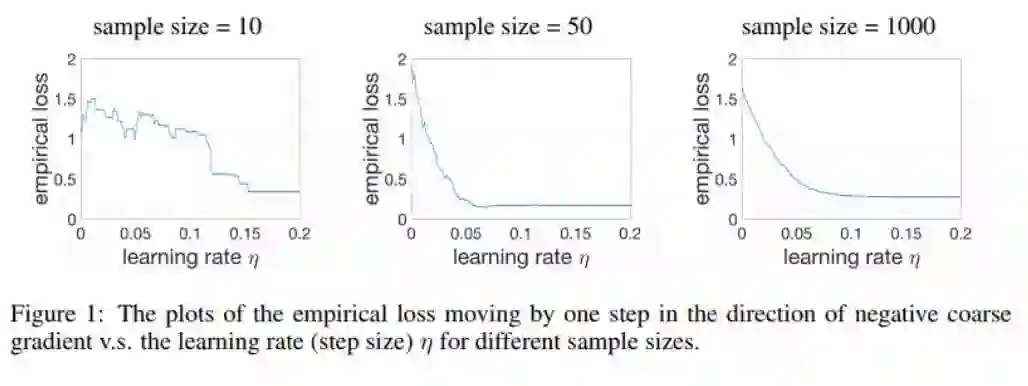
注意随着样本规模的增大,单个步骤的损失是如何获得变得单调和越来越平滑的。这能解释为什么(合适的)STE 在具有大量数据时(就像深度学习一样)的表现会那么好。
将普通 ReLU 的导数视为 STE
(5) 中使用了 ReLU 函数 µ(x) = max(x, 0) 的导数作为 STE。不难看出 µ'(x) = σ(x),全梯度 ∇ f(v, w) 的表达式如下所示。
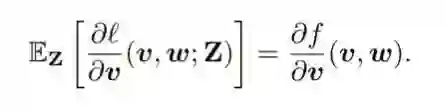
与 w 相关的粗粒梯度遵循下式:
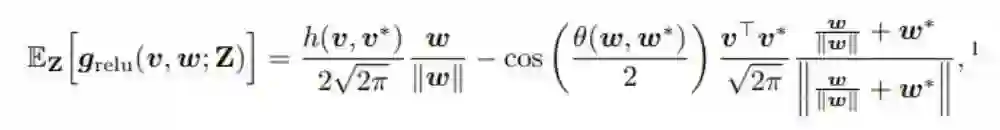
要让粗粒梯度成为真实梯度的一个可接受的估计量,我们需要两者之间的内积为非负。这也可被解释为两个梯度之间的非负相关性。
相关性、内积、夹角
我想稍微扩展,介绍一下夹角、内积和相关性之间的关系,因为这些术语在论文中出现的次数很多。相关性和内积之间的联系可通过以下示例理解。
首先有一个带有实值随机变量的向量空间。设 X 和 Y 为随机变量,它们可能相互独立,也可能不独立。X 和 Y 之间的协方差可这样计算:Cov(X,Y) = E[ (X- µ_X) (Y-µ_Y)],其中 u_X 和 µ_Y 分别为 X 和 Y 的均值。因为这个协方差是双线性的,所以我们可以在随机变量的向量空间上定义内积,使其成为一个内积空间。为了完整说明,下面给出了协方差的公式。
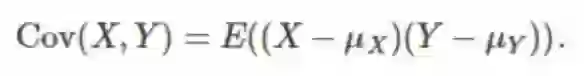
有了内积之后,我们可以定义向量的范数,即 || X || = √X⋅X,这等于 Cov(X,X) 的平方根、E[ (X-mX)(X-µ\X) ] 的平方根、Var(X) 的平方根以及最后的 X 的标准导数,即 𝜎_X。更进一步,两个随机变量的相关性定义为:
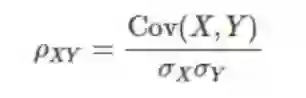
这本质上就是在处理点积(内积)时,两个向量之间的夹角的余弦的定义,即:
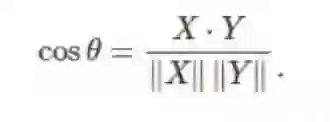
总结来说,协方差是内积,标准差是范数,相关性是夹角的余弦。了解了这一点,我们再回到论文。
内积可以用一种闭式(closed form)表示:
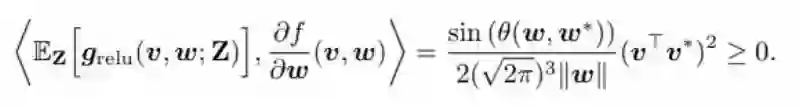
不难看出这个内积是非负的,因为 θ(w, w*) 的范围是 [0, π],所以 sin( θ(w, w*) ) 总是非负的。范数 || w || 也是非负的,(v^Tv*)^2 也是。前面提到,非负内积能保证粗粒梯度大致与真实梯度在同一方向上。因此,ReLU 函数的导数可以用作 STE,以及 f(v, w) 的梯度下降方向。
要让该算法收敛,EZ[(∂l / ∂w)(v, w; Z) ] 和 EZ[ g_{relu}(v, w; Z) ](粗粒梯度)必须同时消失。这只会发生在 (2) 式(即构建的问题)的鞍点和最小量处。(2) 式的最小量应该有 v = v* 且 θ(w, w*)=0。
将截断式 ReLU 的导数视为 STE
现在我们将截断式 ReLU 看作潜在的 STE,即 µ(x) = min(max(x, 0), 1)。图 2 展示了截断式 ReLU 的一个四级量化的版本。
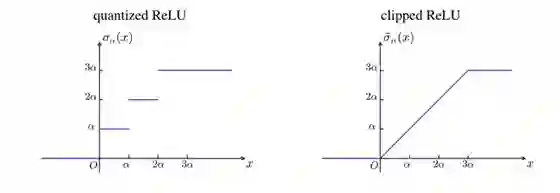
图 2:一个四级(2 位)量化的截断式 ReLU σ_α(x) 和对应的非量化版本。α 是量化级别。
实验和讨论
表现
这篇论文的作者提供了对 STE 的详尽分析,并且表明普通和截断式 ReLU 都能学习两层的线性 CNN。他们继续将这些 STE 用于更深度的网络。注意它们在这些更深度网络上的实验表现不同于在两层网络上的表现。他们在 MNIST(LeCun et al., 1998)和 CIFAR-10(Krizhevsky, 2009)基准上,针对 2 位和 4 位量化激活,执行了利用恒等函数、ReLU 和截断式 ReLU 作为 STE 的实验。
在使用量化模型进行操作时,研究者们已经提出了很多用于获取优良性能的策略。之前的一篇解读给出了近期 SYSML 2019 会议上的一些研究成果:《SysML 2019 论文解读:推理优化》。
表 1 总结了实验结果。表 1 记录了这三种 STE 在不同实验和网络上的训练损失和验证准确度。
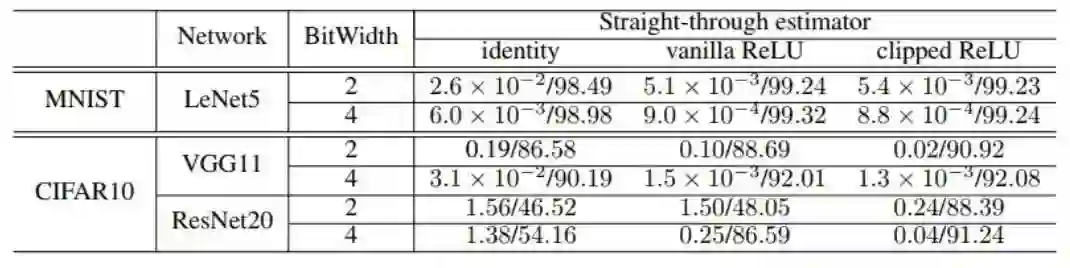
表 1:使用量化激活和浮点权重,三种不同的 STE 在 MNIST 和 CIFAR-10 数据集上的训练损失/验证准确度(%)。测试了 2 和 4 位的位宽。
可以看到截断式 ReLU 的整体表现最佳,尤其是在 CIFAR-10 数据集上。
有人会认为,直观上讲,也许量化的普通 ReLU 应该会有最佳的表现,因为其最接近非量化的版本。但是,表 1 中的实验数据表明截断式版本的 ReLU 的表现最佳。我并不能真正证明为何为这样,但也许可以提供一个直观思路。
总的来说,需要挑选量化 ReLU 的参数 α 以维持全精度水平的准确度,即最高层面需要考虑(截断式)ReLU 的最大值。但是,这可能并不总是最优设置。考虑一个 95% 的激活都落在 [0, 10] 区间的案例,并假设剩余的可能值都固定在 100。「牺牲」这些固定在 100 的激活并在 [0,10] 区间内取 4 级可能是合理的。这能让 95% 的激活都有更好的表征准确度,仅损失激活 5% 的准确度。
话虽如此,当在相对浅的 LeNet-5 网络上时,普通 ReLU 的表现与截断式 ReLU 相当,这在一定程度上与这一理论发现一致,即:ReLU 是一种很好的用于学习二层线性层(浅)CNN 的 STE。
如果使用恒等函数作为 STE 的不稳定性
作者在论文前几节表明恒等 STE 并不能保证收敛。此外,他们还确实观察到了一个现象,即当在有 4 位激活的 ResNet-20 上使用恒等 STE 时,会被推离优良的极小值。
作者执行了以下实验并得出结论:恒等 STE 可能远离一个「优良」极小值。作者使用相对好的 v 和 w 对训练进行了初始化,并在后续 epoch 中使用了恒等 STE 继续训练。他们观察了随 epoch 增多而变化的训练损失和验证误差。
在 2 位激活的 ResNet-20 上使用 ReLU STE 时也观察到了类似的现象。图 3 展示了一个案例:当使用粗粒梯度执行梯度下降时,带有 2 位激活的截断式 ReLU 实际上让算法的结果更差了。
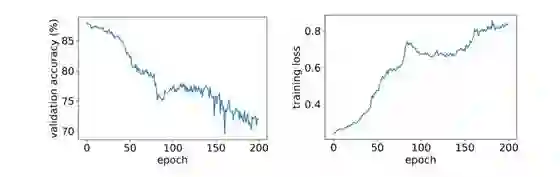
图 3:在带有 2 位激活的 ResNet-20 上,截断式 ReLU STE 所得到的验证准确度和训练损失。激活准确度和训练损失在粗粒梯度方向上都随 epoch 数量而增长。
因此,尽管之前的分析表明使用截断式 ReLU 作为 STE 应该对浅度网络能收敛,但在网络变深时却并不总是有效。读者应当记住这一点。
总结
再次说明,作者试图在这篇论文中回答以下问题。为什么在 STE 的负方向执行搜索有助于最小化训练损失,以及怎样才算是一个「好」STE?
在我们回答这个问题之前,STE 值得尝试的原因是机器学习中的梯度消失问题。当梯度为 0 时,网络就会在反向传播过程中「学习」不到任何东西,因为所有的权重都会保持一样。
因此,作者讨论了使用二元激活学习二层线性 CNN 的三种不同 STE,即 ReLU 函数、截断式 ReLU 函数和恒等函数的导数。作者推导了这些 STE 对应的粗粒梯度,并表明基于普通和截断式 ReLU 的负期望的粗粒梯度是最小化群损失的下降方向,这是因为粗粒梯度和真实梯度之间的内积总是非负的,即它们在同一方向。另一方面,恒等 STE 却并非如此,因为其得到的粗粒梯度并不能保证非负内积的条件。
但是,尽管这些 STE 表明了普通和截断式 ReLU 的收敛性保证,它们在训练更深更大的神经网络时仍可能遭遇稳定性问题。因此,未来的一个研究方向是进一步理解用于梯度难解的大规模优化问题的粗粒梯度下降。
量化模型分析(ANALYSIS OF QUANTIZED MODELS)
引言
近年来,为了加快推理速度、降低内存成本或降低功耗,研究者们已经提出了很多量化模型。这在便携式或手持式设备方面尤显重要。但是,这些模型的训练仍然而且往往是基于浮点精度完成的。因此,训练过程仍然非常耗时。
人们已经提出许多不同的用于加速训练的方法,比如用于在训练过程中近似全精度权重的权重量化(Courbariaux et al., 2015, Lin et al., 2016)。此外,为了在近似/量化权重时取得更好的表现,人们也对量化的方法进行过研究。
近期另一个引人关注的方法是利用分布式训练加速量化网络(Dean et al., 2012)。分布式学习面临的一些关键难题是梯度和模型参数同步过程具有高昂的通信成本(Li et al., 2014)。此外,(Ferdinand et al., 2019)已经从编码理论角度研究了同步丢失梯度和模型参数的问题。我认为在将纠错(error correction)用于机器学习的分布式计算方面,这是一种非常有趣的方法。
在这篇论文中,作者考量了分布式设置中权重和梯度都量化的情况。之前的 DoReFa-Net(Zhou et al., 2016))和 QNN(Hubara et al., 2017)等研究已经探索过权重和梯度的量化。但是,它们都不是在分布式设置中完成的。
之前的工作
之前在量化神经网络方面的研究包括:使用全精度梯度和通过随机权重量化的量化权重的模型(Li et al., 2017; De Sa et al., 2018),仅使用权重的符号的 1 位权重量化(Li et al., 2017)。
此外,也有人研究了带有全精度权重和量化梯度的模型(Alistarh et al., 2017; Wen et al., 2017; Bernstein et al., 2018)。最后,也有研究者研究过权重和梯度都量化的模型(Zhang et al., 2017),但仅限于在线性模型上的随机权重量化和平方损失。
前提概念
在线学习(online learning)
在线学习是指使用一组观察序列作为输入时模型持续适应和学习自己的参数。这些输入在到达时即被处理,而不会划分批次。因此,在线学习是统计学习的一种自然延展,只是在这种序列性方面不同。
该算法有一个损失 f_t(w_t),在每次迭代,经过 T 轮后,通过一个后悔函数(regret function)R(T) = Σ_{t=1 to T} ft(**wt) - f_t(w*),其中 w*** = argminw Σ\{t=1 to T} f_t(w) 评估其表现,即评估之后得到的模型参数的最佳集合。
「后悔(regret)」这一术语在在线机器学习中很常用。直观上讲,最小化(或者说优化)「后悔值」就是降低所采用的动作的数量,事后来看,很显然总是存在一个更好的选择。通过最小化后悔值,我们就是要最小化算法的次优动作。
权重量化(weight quantization)
这篇论文重点关注的是所谓的损失感知型权重量化(loss-aware weight quantization)。不同于现有的用每层、输出或激活(全精度模型)的直接近似来量化权重的方法,损失感知型权重量化会利用来自损失扰动(loss perturbation)、权重量化的信息,并会构建一个渐进的量化策略来执行量化。
通过以一种渐进的方式来显式地规范化损失扰动和权重近似误差,损失感知型量化方法在理论上是合理的,并且在实践中也有效(Hou et al., 2017)。
这篇论文有以下设置。将网络的所有 L 层的权重设为 w。对应的量化权重表示为 Qw(w) = ^w,其中 Qw() 是权重量化函数。这种损失感知型策略涉及到在每个时间实例的优化问题。在 t+1 个迭代时,问题是如何优化一个二次规划(quadratic program):
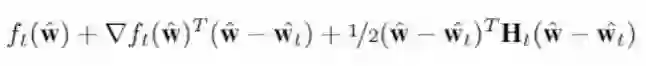
其中优化是针对 ^w 而言,Ht 是指在 ^w 的 Hessian。某些读者可能了解这个,而且知道这是 ft(^w) 的二阶泰勒展开。在实践中,Hessian 往往具有高昂的计算成本,所以往往使用近似的 Hessian。这里也是如此,这里的 Hessian 近似为了 Diag( √^v_t),其中 ^v_t 是移动平均线(moving average)。
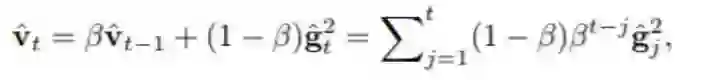
其中 g_t 是随机梯度,β 是 Adam 等深度网络优化器中可直接使用的一个超参数。移动平均线是通过之前在 t-1 的移动平均线、在时间 t 的当前梯度的平方与决定每个分量所受重视程度的参数 β 的凸组合(convex combination)而计算得到的。
最后,在每次迭代根据以下规则更新权重:
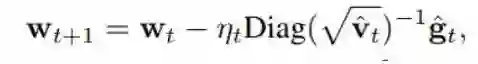
梯度量化(gradient quantization)
在分布式设置下,主要的瓶颈在于由于梯度同步所造成的通信成本。我们可以通过一个简单的例子来理解。假设有 N 个要执行 SGD 的并行处理节点,该过程的伪代码会是这样:
并行处理每一批数据:
读取当前参数,即权重、激活等等
根据这批数据计算梯度
更新梯度
现在假设处理器 1 在剩余的 N-1 个处理器之前率先结束,它已经更新了权重并希望继续处理下一批数据。但是,当处理器 1 读取「当前」参数时,这些参数还没有整合来自另外 N-1 个处理器的更新。
这可能是由于剩余的处理器还没有结束它们的计算,或者它们仍在将它们的更新传输到存储梯度信息的中心位置。一般来说,后者是导致瓶颈的原因。这就是所谓的同步问题,也是提出量化梯度以降低节点之间的通信时间的原因。
量化模型的性质
作者考量了分布式设置下权重和激活两者的量化。我们用 N 表示并行处理数据的工作器(worker)的数量。图 1 简单展示了分布式设置的大致情况。
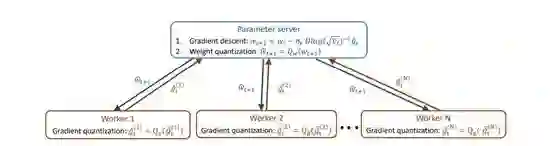
图 1:使用数据并行化的分布式权重和梯度量化
这种分布式设置的工作方式如前一节所描述的伪代码一样。在迭代 t,n ∈ {1, ..., N} 中每一个工作器都执行以下任务:
根据量化的权重计算全精度梯度 (^g_t)^(n),即第 n 个工作器在迭代 t 的 ^g
将 (^gt)^(n) 量化为 (~gt)^(n) = Qg( (^gt)^(n))
将这些信息发送到参数服务器
一旦参数服务器收到来自这些工作器的 n 个结果,就继续:
计算量化梯度的平均 (~g_t) = (1/N) ∑_(n=1 to N) (~g_t)^(n)
基于 (~g_t) 更新二阶矩 ~v_t
使用全精度计算更新权重,根据 w_(t+1) = w_t − η_t Diag( √(~v_t))^(−1) (~g_t)
然后使用损失感知型权重量化计算量化的权重,得到 (^w_(t+1)) = Q_w(w_(t+1)),然后在下一轮迭代将其发送回工作器。
之前在量化网络方面的研究都重在用线性模型分析平方损失。这篇论文没有将成本函数局限于线性模型,但做出了以下假设:
成本函数 f_t 是凸的;
f_t 可用 Lipschitz 连续梯度二次可微分
f_t 的梯度有界
很显然,对神经网络而言,凸假设 1 基本上都不成立。但是,这能促进对深度学习模型的分析。假设 2 在凸假设中很常用。二次可微性是为了确保存在与 Hessian 相关的信息,而假设 2 的「Lipschitz 连续梯度」部分通常是由于强凸性与 Lipschitz 连续梯度之间存在对偶关系。一旦我们很好地理解了其中一个,我们就能轻松理解另一个。
使用全精度梯度的权重量化
当仅对权重进行量化时,损失感知型权重量化的更新为
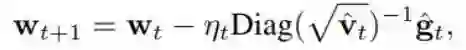
其中 (^v)_t 是之前定义的(平方的)梯度 (^g_t)^2 的移动平均线。论文表明,对于用全精度梯度和 η_t = η/√ t 的损失感知型权重量化,R(T)/T 的边界这样给定:
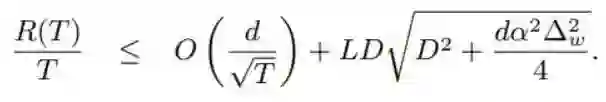
其中 R(T) 是后悔值。这里,平均后悔值的收敛速度为 d/√(T),其中 d 是维度。还有一个与权重量化分辨率 ∆_w(量化层级之间的步长)和维度相关的非零项。L 是 ft 的梯度的 Lipschitz 常数,D 也是一个常数,其为所有 w\m, wn ∈ S(S 是量化权重值的集合)限定了 || w*\m - w_n* || 的边界。
第二项很直观,维度和分辨率 ∆_w 越高,平均后悔值的边界就宽松。此外,常数 L 和 D 直观地描述了 ∇f_t 和 w 的最糟情况的「拉伸/变化」行为,它们也能宽松化平均后悔值的边界。
使用全精度梯度的权重和梯度量化
现在我们看看权重和梯度都量化的情况。损失感知型权重量化的更新为:
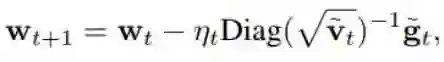
其中 (~g_t) 是随机量化的梯度 Q_g(∇f_t(Q_w(w_t)))。(~v_t) 是平方的量化梯度的移动平均线。在这种设置下,期望的平均后悔值的边界为:
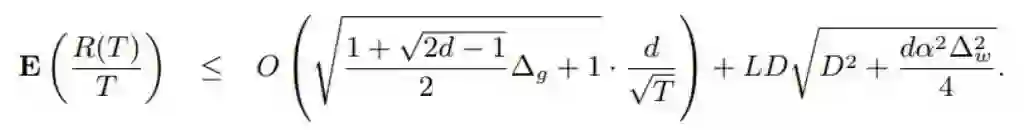
我们可以总结出这一点:在权重之外,量化梯度能将收敛速度降低这样的倍数:
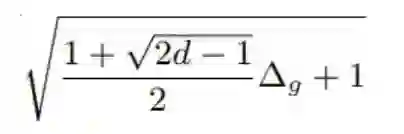
这总是 >1。这会带来问题,因为深度网络的维度 d 通常很大,而分布式学习更倾向于为梯度使用少量比特数,这会导致 ∆_g 很大。
实验
维度的影响
作者研究了维度 d 对收敛速度的影响,还研究了一些常见模型的最终误差,比如使用平方损失的简单线性模型、多层感知器模型和 CifarNet。图 2 展示了结果:
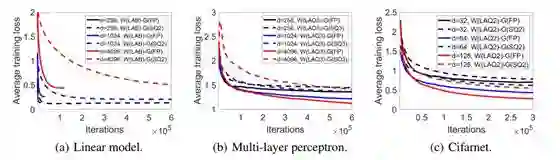
图 2:不同 d 的权重量化模型的收敛
首先我们看看图 2(a),这代表使用平方损失的合成式简单线性模型。可以看到,随着维度增大,其训练损失随迭代的收敛速度就越慢。在 d 更大时,全精度和量化梯度都会导致收敛上的损失更大。前一节的分析也能推知这样的结果。
下一个模型是带有一个包含 d 个隐藏单元的层的多层感知器(Reddi et al., 2016)。其权重使用 LAQ3 被量化成了 3 位。其梯度要么是全精度的(表示为 FP),要么就随机量化为了 3 位(表示为 SQ3)。选择的优化器是 RMSProp,学习率设置为 η_t = η /√ t,其中 η = 0.1。
最后,另一个被测网络是 Cifarnet(Wen et al., 2017)。维度 d 为每个卷积层中过滤器的数量。其梯度要么是全精度的,要么就随机量化为了 2 位(表示为 SQ2)。使用的超参数优化器为 Adam。学习率如(Wen et al., 2017)中一样,从 0.0002 开始衰减,每 200 epoch 以 0.1 的因子衰减。
图 2 的 (b) 和 (c) 分别给出了多层感知器和 Cifarnet 的结果。类似于简单线性模型,参数 d 越大,与使用全精度梯度相比,量化梯度的收敛劣化就越严重。
权重量化分辨率 ∆_w
为了研究不同 ∆_w(量化权重的步长)的效果,论文中使用了(Wen et al., 2017)中一样的 d=64 的 Cifarnet 模型。权重被量化为 1 位(LAB)、2 位(LAQ2)或 m 位(LAQm)。
梯度是全精度的(FP)或随机量化到 m = {2, 3, 4} 位(SQm)。使用的优化器为 Adam。学习率从 0.0002 开始衰减,每 200 epoch 以 0.1 的因子衰减。这个实验使用了两个工作器。结果如图 3 所示。
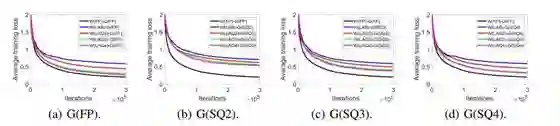
图 3:在 CIFAR-10 上不同位数的权重的收敛情况
图 3 展示了不同位数的量化权重下平均训练损失的收敛情况。结果表明,使用全精度或量化的梯度时,权重量化网络在收敛后的训练损失比全精度网络更高。使用的位数越多,最终损失就越小。这确认了分析部分的结果,也是我们直观上能预期的结果。
梯度量化分辨率∆_g
这里使用了同样的 Cifarnet 模型设置,优化器也是 Adam,研究了 ∆_g(量化梯度的步长)的影响。图 4 给出了不同数量的量化梯度位数下平均训练损失的收敛。同样,结果和预期一样。位数更少时,最终误差就更大,而且使用 2 或 3 位梯度比使用全精度梯度的训练损失更大、准确度更低。
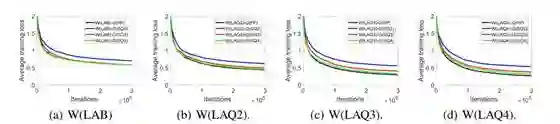
图 4:在 CIFAR-10 上不同位数的梯度下的收敛情况。其权重是二值化的(记为 W(LAB))或 m 位量化的(W(LAQm))
不同的工作器数量
最后,作者调查了不同工作器数量 N 的影响。他们的目标是调查当使用不同数量的工作器时准确度是否会有损失。他们使用了 Cifarnet(Wen et al., 2017)在分布式学习设置中测试不同数量的工作器。
每个工作器的 mini-batch 大小设置为 64。其中测试和比较了 3 位量化的权重(LAQ3),全精度或随机量化到 m = {2, 3, 4} 位(SQm)的梯度。表 1 展示了不同工作器数量下的测试准确度。
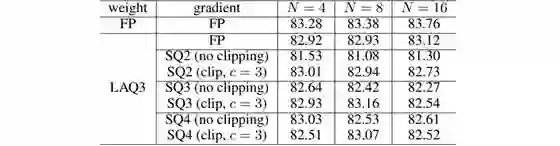
表 1:使用不同数量(N)的工作器时,在 CIFAR-10 上的测试准确度(%)
表 1 还包含了使用梯度裁剪(gradient clipping)的结果。梯度裁剪是一种防止非常深度的网络中梯度爆炸问题的技术。梯度爆炸是指梯度变得过大且错误梯度累积的情况,这会导致网络不稳定。尽管如此,我相信从表 1 可以看到量化模型能够实现与全精度模型相媲美的表现。
总结
这篇论文研究了具有量化梯度的损失感知型权重量化网络。量化梯度的目的有两个。第一,这可以减少反向传播阶段的计算量。第二,这可以降低分布式设置中通信单元之间的通信成本。论文提供了具有全精度、量化和量化裁剪的梯度的权重量化模型的收敛性分析。此外,作者还通过实证实验证实了理论结果,表明量化网络可以加快训练速度,并能取得与全精度模型相当的表现。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

