【泡泡航行天下】基于变点行为预测的自动驾驶多策略决策
泡泡航行天下,带你精读决策规划领域的顶会顶刊文章
标题:Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment
作者:Enric Galceran, Alexander G. Cunningham, Ryan M. Eustice, Edwin Olson
来源:AUTON ROBOT 2017
编译:胡星宇
审核:许婧
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——基于变点行为预测的自动驾驶多策略决策,该文章发表于AUTON ROBOT 2017。
自动驾驶的决策面临的挑战是附近车辆的不确定性,特别是它们的潜在意图,如拐弯或变道。在多车场景下,状态空间的计算量非常大,难以估计它们可能采取的行为集。之前是采用启发式或枚举优化,但这些方法对互动的交通事件并不好用。比如一辆后面的车的突然超车动作可能导致前车重新考虑它自己的超车决策。目前,估计临近车辆行为的算法仅考虑了临近车当前的状态或者需要大量训练数据,而没有考虑历史信息。
本文考虑了有限的先验策略,该系统按两个交错的阶段进行:行为预测和决策选择。行为预测是通过贝叶斯变点检测,学习临近车历史上每个点的行为,从而推断出该车每个潜在行为可能性。然后我们通过一种基于变点检测的统计测试来识别异常行为,如行驶在错误的方向上或偏离车道,这样我们可以探测到何时不能使用观测的行为来决策,并且个别策略可以调整其控制措施来对异常车辆做出响应。接着利用所有推断的决策,来评估可能的后果。后果的奖励函数是用户定义的,最终的决策最大化了奖励。
主要贡献
1、利用贝叶斯变化点检测算法权衡历史行为,来预测可能的未来行为。
2、对在线异常行为检测的统计测试。
3、提出一种决策算法,评估了预测行为所带来的后果。
4、在真实场景和模拟场景中对提出的算法进行评估。
算法流程
问题描述
作为一个决策问题,其目标是在一个动态,不确定的环境中,在多车紧密耦合的交互作用下,选择最大化奖励函数的行动。我们首先将这个问题表述为一个完整的POMDP(部分可观测的马尔科夫决策过程),然后利用驾驶知识将这个问题重新表述为一个独立的决策,这个决策是针对的是一小部分高层决策。
用V表示临近车的集合(包括本车),在时间t,一辆车v采取行为a_t,从状态X_t转变到状态X_t+1。在该系统中,一个状态指位姿、速度、加速度的元组,一个行为指用于转向、油门、制动器、换档器和转向的信号元组。
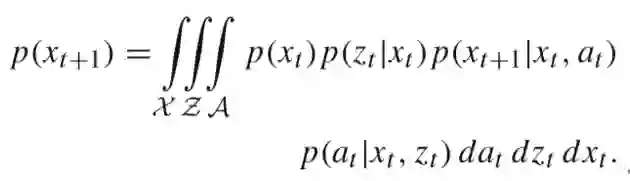
目标是找到一个决策π最大奖励函数,决策π是X*Z->A的映射,其中Z是本车对其他车辆的观测信息,即决策行为是从当前状态的最大后验估计和观测结果计算来的。
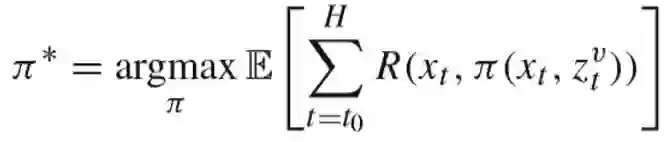
算法描述
由于上述公式在边缘计算上花费昂贵,如果我们考虑所有的决策,将会计算很多小概率的决策动作,比如违反交通规则的行动。因此在每个状态X中,对于每个决策π,需要先计算可行性APPLICABLE(π_i,X)以决定哪些策略可以在这个状态中进行。这样就减少了决策集的大小。
本文中另一个重要处理是对其他车辆v驾驶的建模:
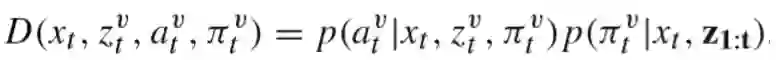
在这里P(at|X_t,Z_t,π_t)是t时刻状态X、本车观察到的信息Z1:t时,车辆v采取决策π的概率,因此之前的预测Xt+1状态的公式可以表示为:
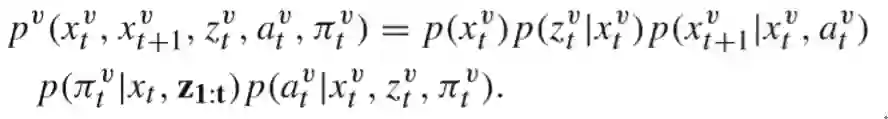
由于本车对自身决策具有完全的控制权限,是完全取决于各项状态参数的,因此对于集合v∈V中的车辆,P(Xt+1)中,可以把本车剔除掉:
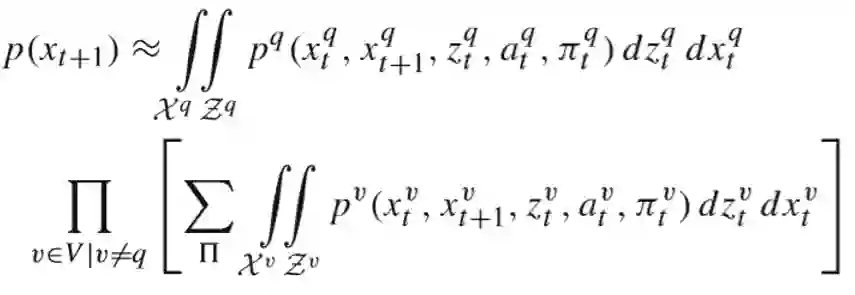
整个车辆的基于变化点预测的决策过程如下所示:
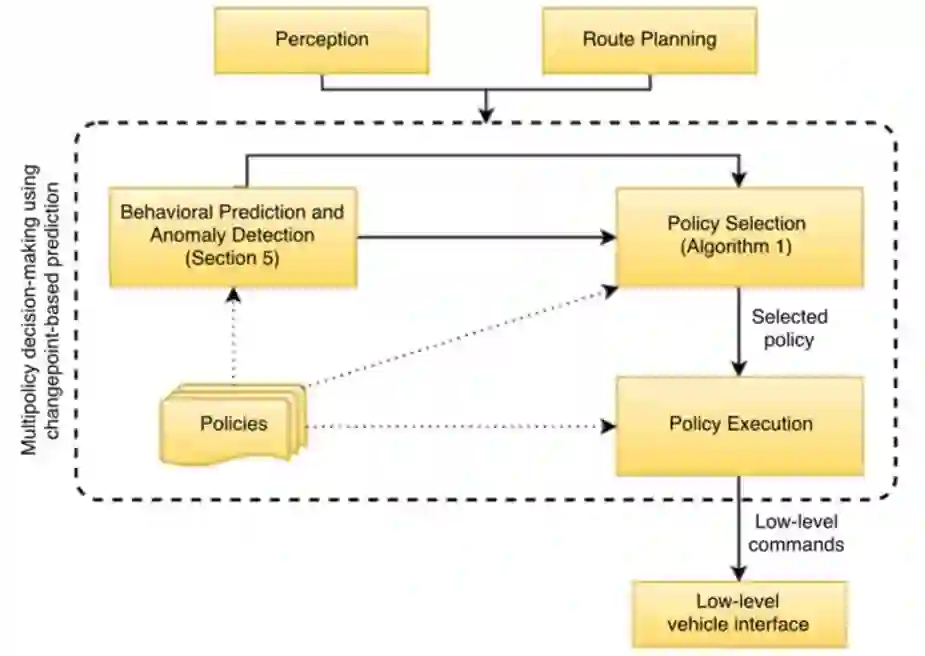
本文中的算法实际上是对POMDP(部分可观察马尔可夫决策过程)的简化和近似,因为POMDP在计算上难以解决。通过减少决策集和减少小概率场景,并将策略结果近似为状态的确定函数,从而实现建模。
本文中设定的车辆策略包括:在当前车道上行驶,并在前方直接与车辆保持距离;车道右转/车道左转,在每个方向上单独制定单车道变换政策;在交叉口右转、左转、直行或让行。上图中的策略执行模块始终运行当前选定的策略,以30~50HZ的频率生成始终平稳和安全的车辆控制策略。策略执行模块只允许有效的策略,而且在机动过程(如车道变换)中策略不会被抢占。之前的一些策略预测算法仅考虑了目标车辆的状态,与之相比,本文利用观测车辆历史上的变化点来计算策略的可能性。
对于异常的检测,首先根据政策相似性定义异常行为的特性,然后将观察到的数据与先前记录的车辆轨迹中标记的正常模式进行比较,本文对异常行为定义了以下两个标准:
1、无可用策略。在文中设计的遵守交通规则并使车辆平稳安全的策略中,反常的行为都不能用可用的策略解释。因此,现有政策不会捕捉到诸如在错误方向行驶或在公路上越过实线的行为。
2、策略不明确。如果在历史记录的片段中,不同的策略频繁波动,表明策略不明确。为表达这个准则,首先构建柱状图来记录每个历史片段中每个策略的出现情况。分布广泛的柱状图表示频繁的波动,而单一模式的柱状图更可能与正常行为相对应,用直方图的过度峰度来度量这个特征。
试验评估
我们的自动车辆平台用于数据收集和自动测试,包括一个配备传感器套件的线控福特Fusion,包括四个Velodyne HDL-32E 3D激光雷达扫描仪、Applanix pos-lv 420惯性导航系统(INS)和GPS。车载五节点计算机集群实时执行系统的所有规划、控制和感知。其他交通参与者的状态估计由车辆上运行的动态物体跟踪器提供,该跟踪器使用激光雷达测距。利用激光雷达测量,还可以推断出静态障碍物的几何结构和位置。
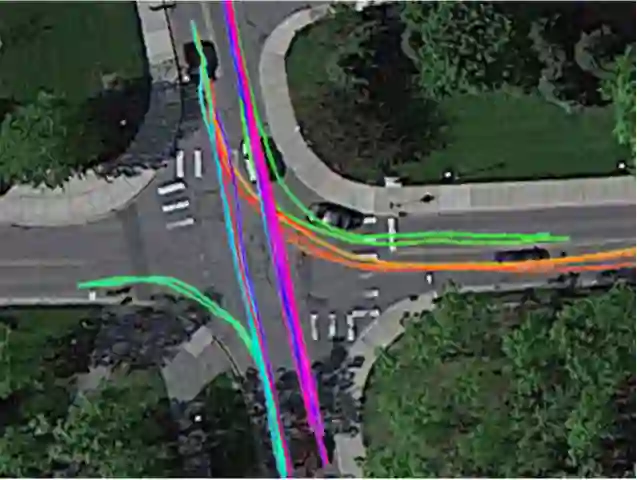
用于评估行为预期的交通跟踪数据集由67条动态目标轨迹组成。记录在城市地区。在这67条轨道中,18条对应于“跟随车道”的机动,20条对应于在有分隔的公路上记录的车道变换机动。其余29条轨道(如下图所示)对应于在停车标志调节的四向交叉口观察到的机动。
主要结果
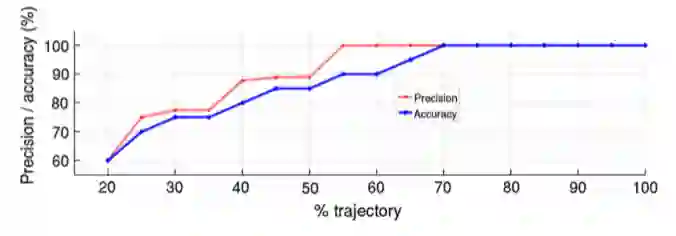
通过变点检测对当前策略识别的精度和精度曲线进行评估,并增加轨迹的子序列。作者的方法在完成50%的轨迹后就达到了85%以上的准确度和精度,并且策略的闭环性质会产生及时寻求安全的车辆行为。
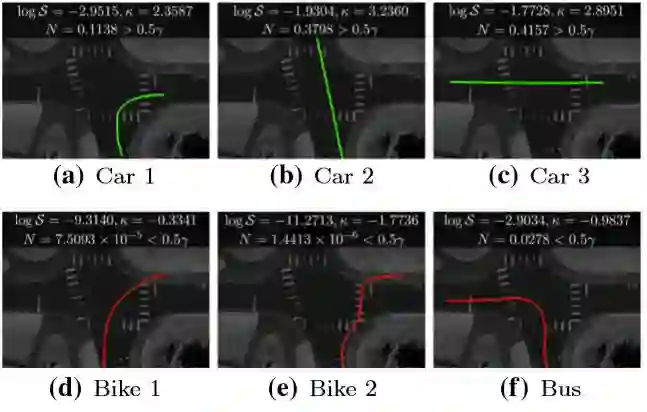
异常检测示例:第一行是在交叉口数据集中汽车驾驶的正常轨道。第二行是由自行车(d)、(e)和公共汽车(f)行驶的异常轨迹。作者的测试能够正确检测出不由交叉口政策建模的异常轨迹。

场景模拟:两辆车(上方)通过测试车辆的前向摄像头显示。在三车道道路的右车道上,测试车辆在两辆车辆的后面启动。车辆1沿道路在右侧车道行驶,而车辆2则连续两次向左改变车道。测试车辆保持在车辆1后面的右车道上,直到车辆2开始从中间车道到左车道的车道变换,然后在这一点上测试车辆将车道变换到中间车道。测试车辆经过了两辆车,然后回到右边的车道。
Abstract
This paper reports on an integrated inference and decision-making approach for autonomous driving that models vehicle behavior for both our vehicle and nearby vehicles as a discrete set of closed-loop policies. Each policy captures a distinct high-level behavior and intention, such as driving along a lane or turning at an intersection. We first employ Bayesian changepoint detection on the observed history of nearby cars to estimate the distribution over potential policies that each nearby car might be executing. We then sample policy assignments from these distributions to obtain high-likelihood actions for each participating vehicle, and perform closed-loop forward simulation to predict the outcome for each sampled policy assignment. After evaluating these predicted outcomes, we execute the policy with the maximum expected reward value. We validate behavioral prediction and decision-making using simulated and realworld experiments.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



