【泡泡一分钟】基于在线多智能体姿态优化的协作大规模稠密三维重建
每天一分钟,带你读遍机器人顶级会议文章
标题:Collaborative Large-Scale Dense 3D Reconstruction with Online Inter-Agent Pose Optimisation
作者:Stuart Golodetz Tommaso Cavallari Nicholas A. Lord, Victor A. Prisacariu David W. Murray Philip H. S. Torr
来源:arXiv 2018
播音员:清蒸鱼
编译:蔡纪源
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——基于在线多智能体姿态优化的协作大规模稠密三维重建方法,该文章发表于arXiv2018。
对真实世界进行三维场景重建是十分重要的,许多任务都要用到重建得到密集体积模型。但这需要花费大量时间来捕获大规模的场景,而且随着捕获时间的推移场景也是在不断变化的,所以这样的方式得到的场景重建效果往往不尽人意。
那么为何不考虑同时捕获多个较小的子场景来一起重建整个大的场景呢。要做到这一点,传统上是很困难的:将这些非同一视角捕获的子场景连接起来,需要高质量的可以处理各种姿态的重定位器,并且要跟踪每个子场景中的漂移以防止它们被加入制作一致的整体场景中。庆幸的是,得益于最近在移动硬件方面的进步,大大提高了我们捕获中等规模子场景的能力,并且几乎没有跟踪漂移。此外,在基于森林的高性能回归重定位器中引入一种新方法,使得它们能够进行在线训练和使用,从而变得更加实用。
如下图1所示,在本文中,作者利用了这些进步,提出了首个允许多个用户交互式协作地对整个场景进行重建的系统。
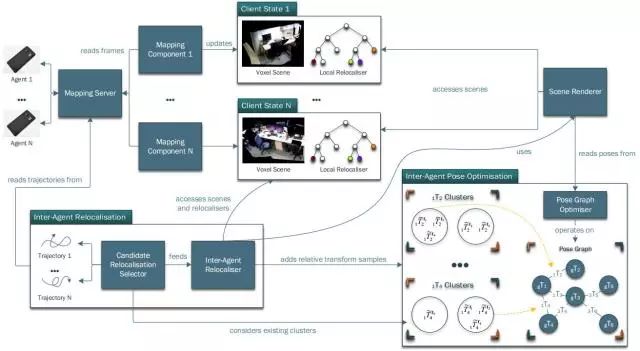
图1 本文方法的系统结构图
无论是本地还是远程的机器人都能够独立完成姿态跟踪和建图,重建出基于体素的场景并训练局部重定位器。如下图2所示,其中候选重定位选择器会多次选择一个机器人的轨迹中的姿态来重定位另一个场景。多智能体之间的重定位器使用场景渲染器来渲染选中姿态对应场景的合成彩色图与深度图,并将结果传给目标场景的局部定位器。一旦重定位成功,就记录两个场景之间的相对变换样本。为了保证鲁棒性,要对每个场景的相对变换样本做聚类。每当聚类中添加足够大的样本时,则在最大聚类中混合相对姿态来构造姿态图,然后完成姿态图优化。最后,将优化后的姿态用于渲染整个场景。
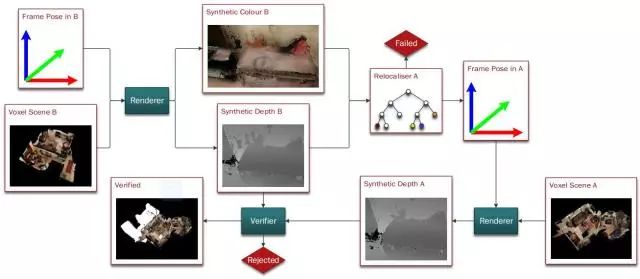
图2 智能体b的场景相对智能体a的场景重定位方法说明
作者已经将该方法整合到了开源框架SemanticPaint中,现有的SemanticPaint和InfiniTAM用户可以从作者的工作中受益啦。作者还构建了一个新的子场景数据集用于验证方法, 并要把代码和数据集公开(敬请期待作者实验室主页http://www.robots.ox.ac.uk/~tvg/index.php)。实验表明,使用作者提出的系统,仅使用消费级硬件就能在半小时内对整个房屋或实验室进行捕获和重建。
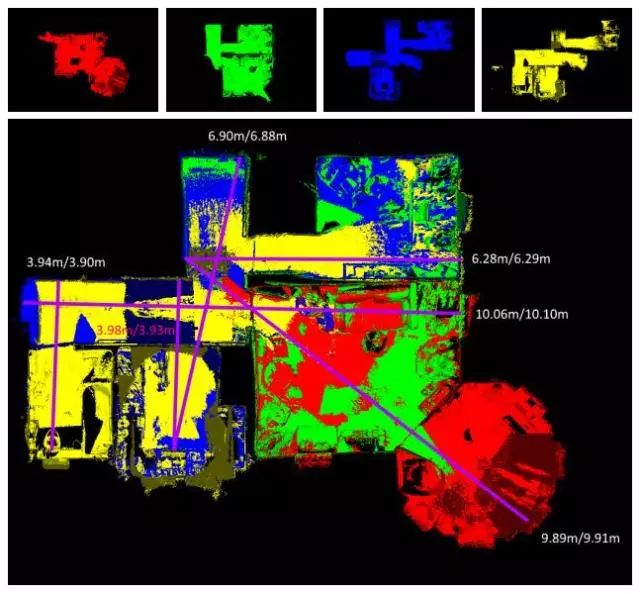
图3 使用本文方法将对四个序列数据协作重建得到的高质量地图

图4 作者提出的系统性能评估

Abstract
Reconstructing dense, volumetric models of real-world 3D scenes is important for many tasks, but capturing large scenes can take significant time, and the risk of transient changes to the scene goes up as the capture time increases. These are good reasons to want instead to capture several smaller sub-scenes that can be joined to make the whole scene. Achieving this has traditionally been difficult: joining sub-scenes that may never have been viewed from the same angle requires a high-quality relocaliser that can cope with novel poses, and tracking drift in each sub-scene can prevent them from being joined to make a consistent overall scene. Recent advances in mobile hardware, however, have significantly improved our ability to capture medium-sized sub-scenes with little to no tracking drift. Moreover, highquality regression forest-based relocalisers have recently been made more practical by the introduction of a method to allow them to be trained and used online. In this paper, we leverage these advances to present what to our knowledge is the first system to allow multiple users to collaborate interactively to reconstruct dense, voxel-based models of whole buildings. Using our system, an entire house or lab can be captured and reconstructed in under half an hour using only consumer-grade hardware.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



