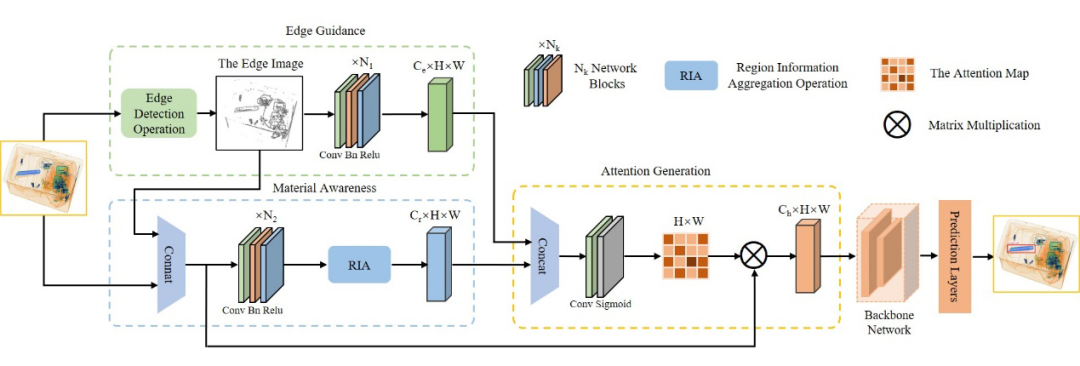
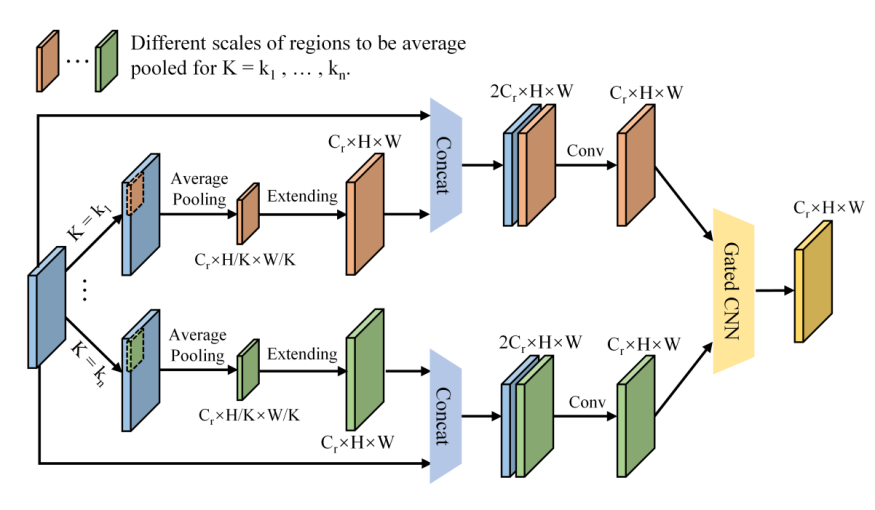
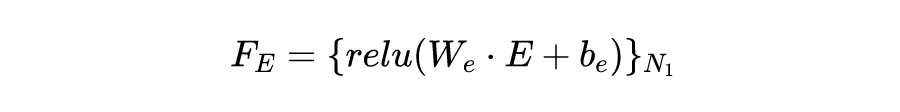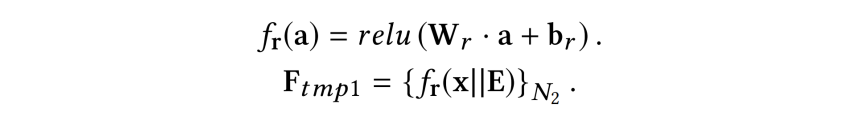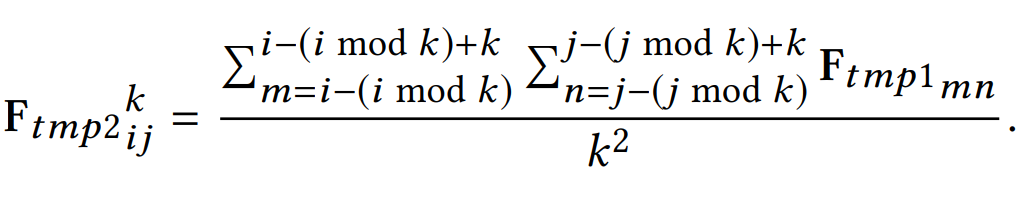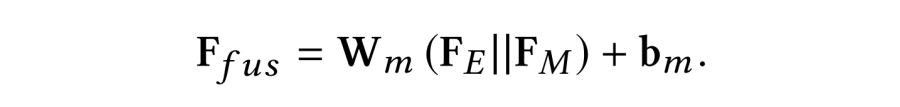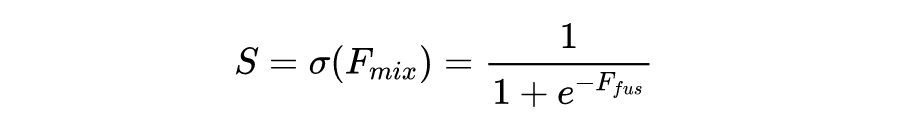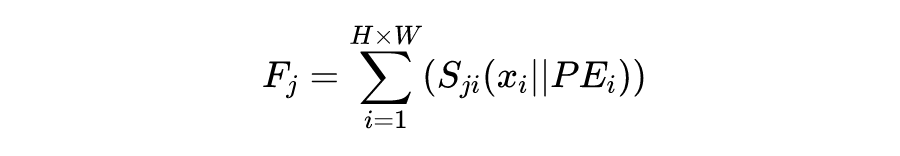随着公共交通枢纽中人群密度的不断增加,安全检查在保护公共空间免受恐怖主义等安全威胁方面的作用越来越重要。安检通常采用 X 射线扫描仪来检查行李中是否含有违禁物品。然而,在安检场景中,在行李箱中的物品是随机摆放的,并且彼此严重重叠,因此安检员要检测出违禁物品十分困难。同时,经过长时间地聚精会神地观看复杂的 X 光图像,安检人员难以准确检测出违禁物品。而频繁人员换班会耗费大量人力资源。因此,社会迫切需要一种快速、准确、自动化的方法来帮助安检员检测 X 射线扫描图像中的违禁物品。 随着深度学习技术的发展,特别是卷积神经网络的发展,在 X 射线图像中识别被遮挡的违禁物品可以看作是计算机视觉中的一个目标检测问题。北京航空航天大学研究团队发表在 ACM Multimedia 2020 上的本一篇题为《Occluded Prohibited Items Detection: An X-ray Security Inspection Benchmark and De-occlusion Attention Module》,提出了针对安检场景下的目标检测任务而设计的高质量数据集 OPIXray,该数据集中所有图片所包含的危险品都由某机场的专业安检员手动标注。 此外,该论文还提出了一种用于检测安检场景下遮挡的违禁物品的方法,该方法的核心是一个能够去遮挡的注意力模块(DOAM)。该模块可以作为一个即插即用的模块插入到大多数检测器中,目的是检测 X 光图像中被遮挡的危险品。
目前该论文提出的数据集和代码均已开源。
论文地址:
https://dl.acm.org/doi/10.1145/3394171.3413828
数据集和代码地址:
https://github.com/OPIXray-author/OPIXray
OPIXray数据集
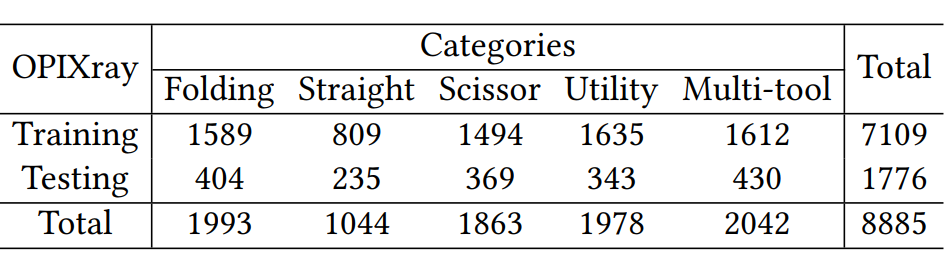
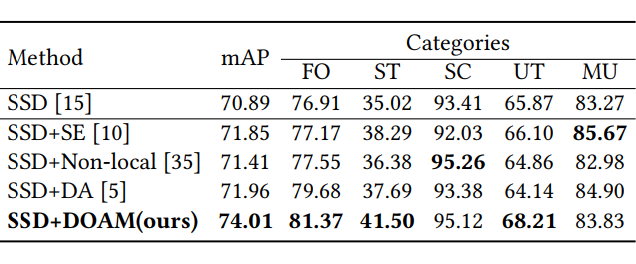
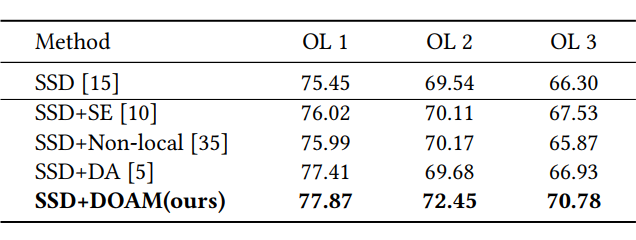
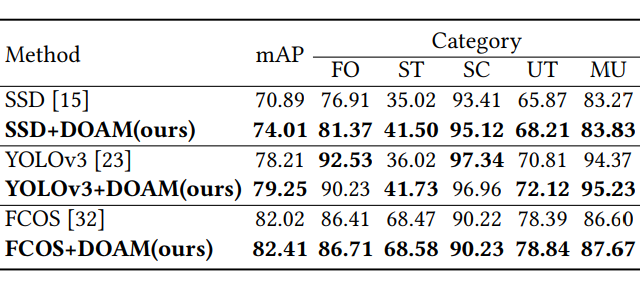
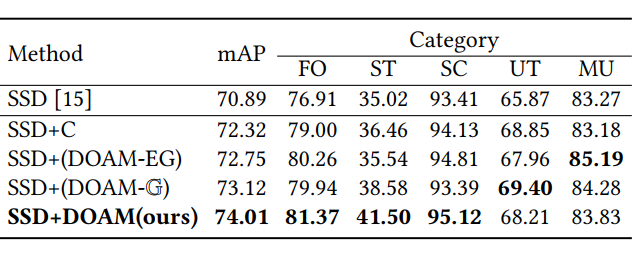
一个高质量的含有违禁物品标注的专业数据集对于模型的训练和评估是必要的,因此,我们建立了第一个针对被遮挡的违禁物品检测任务的 X 光图片数据集。
1.1 数据采集
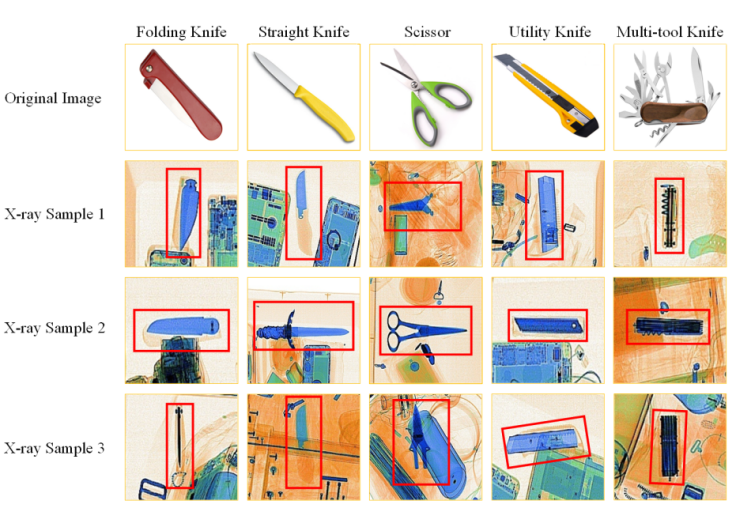
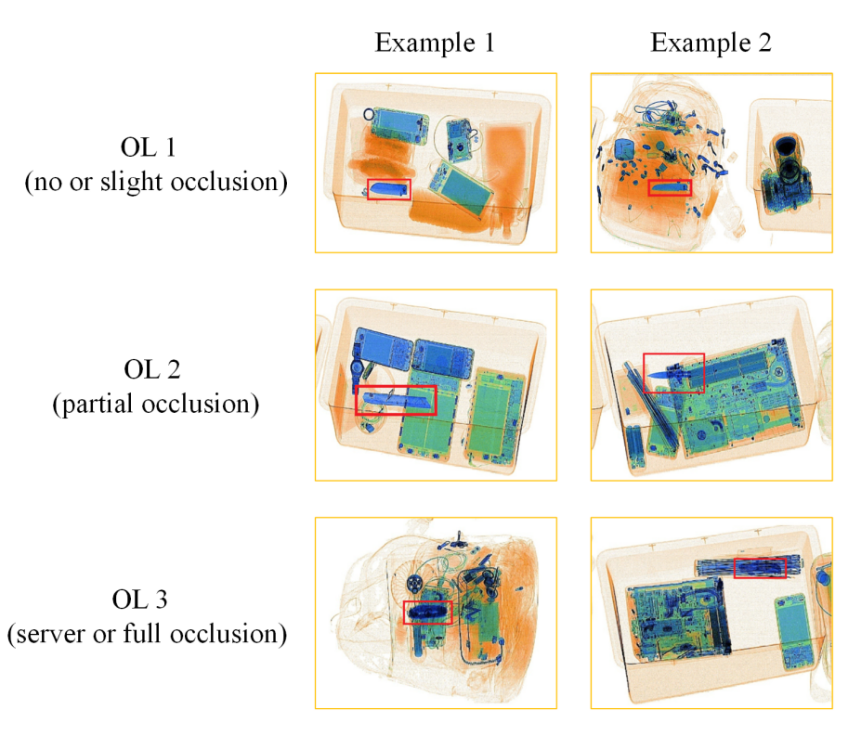
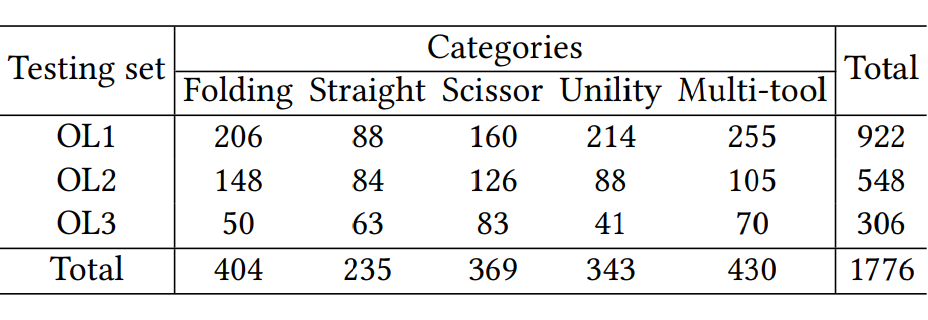
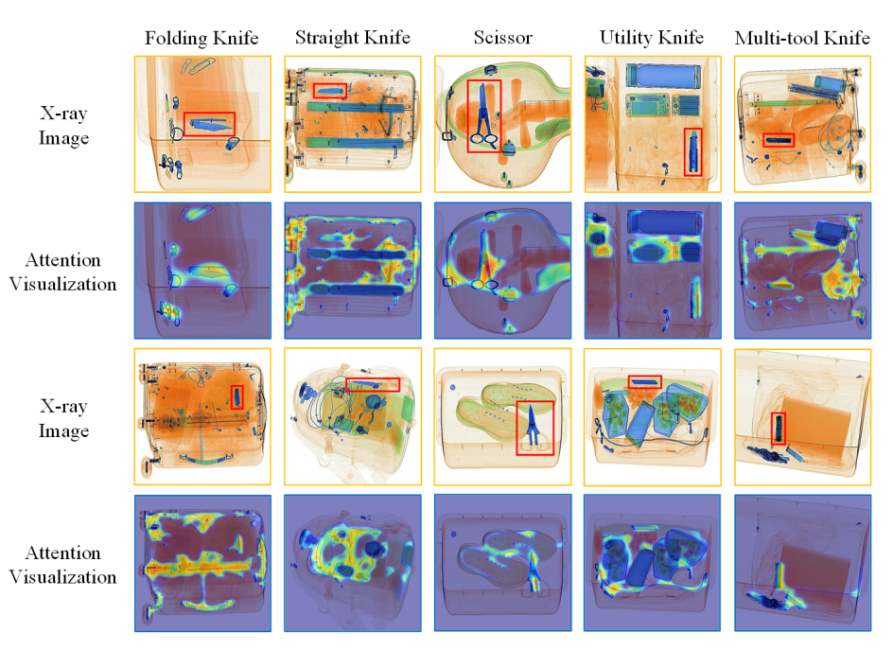
OPIXray 数据集的所有图像均由安检机扫描,并由国际机场的专业检查人员手工标注,标注标准为安检人员的培训标准。这些 X 射线图像仍然保留特定的特性,即不同的材质显示出不同的颜色,并且每个违禁物品都由一个方框进行定位。
计算机视觉技术的进步推动着人工智能时代的到来,视觉技术在我们日常生活中应用广泛,产生了巨大的社会价值。在视觉技术中,热门领域主要为人脸识别、自动驾驶、行人检测等,这些技术的发展极大改善了我们的生活。 AI 安检是一个相对小众的话题,如果能够成功应用于生活实践中,不仅能够提升我们进入火车站、机场的效率,同时极大地节省人工成本,将带来巨大的社会效益。然而,由于在安检过程中,由于行李包裹中的物品随意摆放,互相遮挡,导致机器在 X 光检测的图片中要找出危险物品十分困难。我们应当以更加积极的心态和更加挑剔的眼光去看待 AI 安检,现有技术距离 AI 安检成熟落地还有很多工作要做。 作者简介 尉言路(共同第一作者),北京航空航天大学硕士生,已入职中国移动通信研究院,主要研究方向为小目标检测、小样本学习。已有研究成果在 ACM MM,ICCV,CVPR 等国际顶级计算机视觉与多媒体会议上发表多篇论文,获 2020 年度硕士研究生国家奖学金。
陶仁帅(共同第一作者),北京航空航天大学博士在读,主要研究方向为复杂场景下的目标识别,包括去遮挡、域适应、小样本等,已在 CVPR、ICCV、ACM MM 等国际顶级计算机视觉与多媒体会议上发表多篇论文,获 2021 年度博士研究生国家奖学金。