
摘要
一个能够理解自然语言指令并在视觉世界中执行相应动作的agent是人工智能(AI)面临的长期挑战之一。由于来自人类的指令繁杂,这就要求代理能够在非结构化的、前所未见的环境中,将自然语言与视觉和行动联系起来。如果人类给出的指令是一个导航任务,那么这个挑战就称为视觉语言导航(Visual-and-Language navigation, VLN)。它是一个蓬勃发展的多学科领域,越来越重要,具有非凡的实用性。本文不关注具体方法的细节,而是对VLN任务进行全面的综述,并根据这些任务中语言指令的不同特点进行细致的分类。根据下达指令的时间,任务可分为单回合和多回合。对于单回合任务,我们根据指令是否包含路径,进一步将其分为目标导向和路径导向。对于多回合任务,我们根据agent是否响应指令将其分为命令式任务和交互式任务。这种分类方法可以帮助研究者更好地把握具体任务的关键点,明确未来的研究方向。
引言
想象你要去一个你从未去过的地方参加一个会议。在GPS和数字地图的帮助下,可以很容易地规划一条路线,覆盖最终目标99%的距离。然而,我们可能会迷路,甚至只剩下一公里。这时,我们可以打电话给主人或转向路人,她/他会指导你一些语言上的说明。说明书可能包含一些方向性指南和一些视觉地标。在帮助下,你可以到达会面地点。
视觉和语言导航(VLN)[1]是在非结构化、不可见的环境中连接自然语言和视觉和导航的任务。它引起了计算机视觉(CV)和自然语言处理(NLP)领域研究人员越来越多的兴趣。由于深度学习的成功,在CV和NLP领域的一些任务都有了重要的进展。这种激增首先出现在CV的一些任务中,如分类[2]、检测[3]、分割[4]等,使用的是自监督[5]或大型注释数据集。接下来,NLP在以预训练的语言模型为骨干的多任务解决方面取得了显著的进步[6,7],该模型在大型无标记语料库上进行了训练。
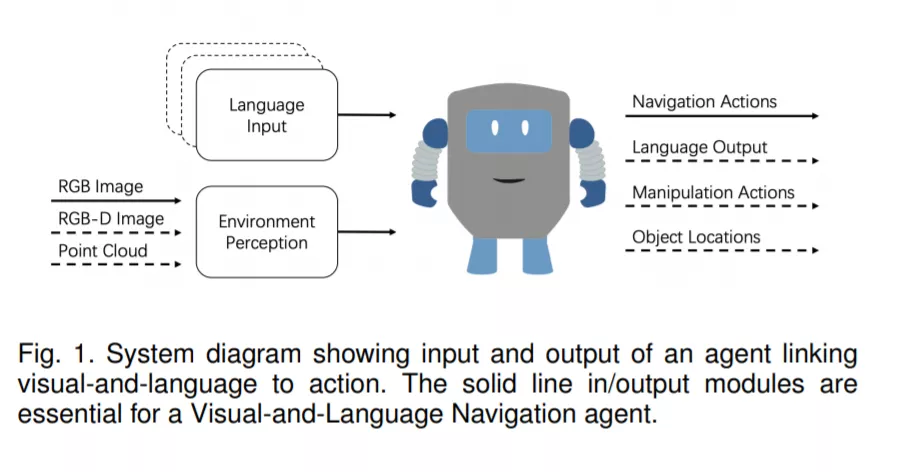
与此同时,Lee等人[8]证明,使用神经网络策略,四足机器可以获得超越以往方法的运动技能。这些巨大的进步增强了研究人员解决更复杂任务的信心,将视觉与语言和行动结合起来。VLN是这一趋势的一个里程碑。执行VLN的能力进一步支持各种更高级别的人工智能任务,如ALFRED任务[9],其中agent需要学习从自然语言指令和自我中心视觉到家庭任务动作序列的映射。同时,从前面的例子中我们可以看出,VLN任务不仅对室内环境[10]有价值,对室外环境也有价值。
在这次综述中,我们将全面回顾现有的视觉和语言任务,并发现大多数方法基本上都是为了解决一个任务而设计的。在这种情况下,我们试图找出VLN任务之间的内部差异。可见视觉部分的差异相对较小。无论是2D还是3D,室内还是室外,虚拟还是真实感,它们都只是环境感知的导航轨迹。例如,任务REVERIE[19]和Room-to-Room[1]基于相同的环境模拟器。然而,语言部分导致这些任务完全不同。基于这一见解,我们引入了一种新的分类法来对VLN任务进行分类。根据语言指令的给出方式,VLN任务可分为单圈和多圈两种类型。对于单回合任务,在代理开始滚动之前会给出一系列指令。无论是否指定路由,指令可以分为: 目标导向指令和路由导向指令。
-
目标导向。说明书中包含了几个目标,但没有关于如何实现这些目标的线索。当智能体处于起始点时,目标可能是可见的。一个智能体可以先找到目标,然后规划整个轨迹,然后完成它。所有的物体都可以看到,研究人员试图解决低水平控制的挑战。然而,目标在某些任务中是不可见的。智能体必须搜索环境中的对象。
-
路由导向。智能体如果不严格按照指令中所包含的路线运行,可能会迷路。该指令可能格式良好。它们可以被一些规则分解成几个有意义的部分,每个部分表示一个动作。在这种情况下,智能体可以计划一个动作序列,然后执行它。所有的前沿研究,如[39,40],都是在这个框架下进行的。即使是最近,[41,42,43,44,45]中任务的路由指令解析起来也相对简单。实际上,自然语言指令是非结构化的,难以解析。然而,随着深度学习的迅猛发展,利用深度神经网络处理非结构化指令的兴趣越来越多。最令人印象深刻的任务无疑是房间到房间[1]。关于非结构化面向路由指令的任务的更多细节将在下面的章节中说明。
对于多回合任务,导航员将在几个回合中向导航员给出指令。根据导航器是否能够响应指南,任务被分为: 命令式和交互式。由于指令可以多次给出,所以一个回合的指令主要是可见的目标导向,便于执行。
-
命令式:导航器不能响应指南,只能执行指令。
-
交互式:指南器和导航员都可以提问和分享信息,这在日常生活中更为常见。
为此,我们简要分析了VLN任务的指令。然而,训练VLN代理需要一个“软件堆栈”[46]: (1)提供带有语义注释的2D/3D资产的数据集,(2) 渲染这些资产并在其中模拟agent的模拟器,以及(3)定义可评估问题的任务,使我们能够对科学进展进行基准测试。如表1所示,我们总结了典型的任务和相关的模拟器,数据集将在下一节中说明。除了导航之外,一些任务还可能与其他操作交织在一起,比如操作一个对象、回答一个问题、定位一个目标对象。我们的分类法只考虑导航部分的贡献。首先,我们对现有的视觉语言任务进行了全面的回顾。与最近的工作相比,这项调查涵盖了更多的最近的论文,更多的任务和数据集。其次,精心设计了VLN任务的分类,如图1所示。第三,对第四节至第六节的每一项任务进行总结和分析。在第7节中还描述了当前方法的常见限制和可能的解决方案。这可能会为这一领域的研究人员提供鼓舞人心的想法。