停车位检测新数据集、新方法,精准又快速(含视频解读)
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 论文已上传,文末附下载方式

本文是一篇关于停车位检测的文章,文章的视频有详细解读,文章的创新点就是在圆形描述器来回归定点坐标。地址: https://www.bilibili.com/video/BV1CA411v74F?t=32。 希望各位看官们,多多支持,一键三连。
论文地址:https://arxiv.org/pdf/2005.05528.pdf
数据集地址:https://github.com/wuzzh/Parking-slot-dataset
已获得原UP主授权,转载请联系。地址:https://www.bilibili.com/video/BV1CA411v74F?t=32。超专业,超良心,各位看官记得去B站一键三连。
实时停车位检测在泊车系统中起着至关重要的作用,现有的方法主要有两个原因导致性能不理想:1、目前有关停车位检测的可用数据集多样性有限,这导致训练出来的模型泛化能力较低。2、停车位检测的专业性通常是被低估了的。因此,本文为了更好地训练停车位检测模型,对大规模的benchmark进行了标注,并在社区中共享。
本文提出了一个圆形描述符来回归停车位顶点的坐标,从而准确地定位停车位。为了进一步提高性能,开发了一个两阶段的深度体系结构,以从粗略到精细的方式定位顶点。在benchmark和其他数据集的测试中,本文设计的方法可以在实践中达到实时性的同时保持最先进的准确性。
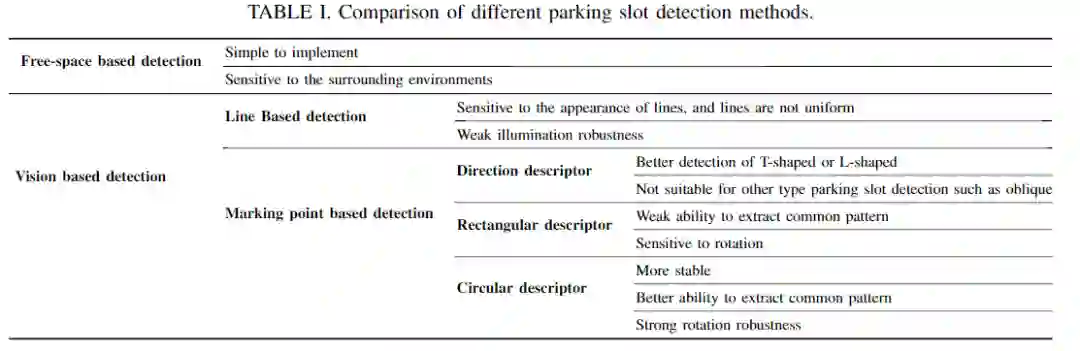
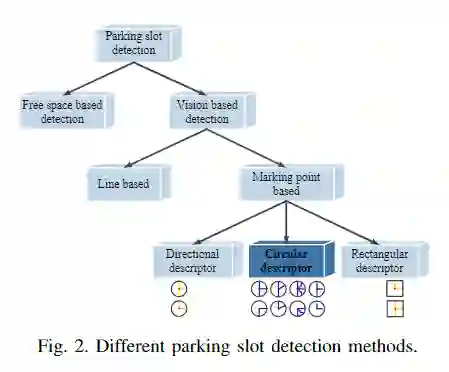
基于标记点的深度方法在停车位检测中占据了主导地位。已经提出了包括DeepPS 和DMPR-PS 等典型工作来识别用于停车位检测的标记点。这两种方法的主要区别在于标记点的描述方式。DeepPs 利用矩形描述符提取停车位顶点的矩形邻域内的图案。然而,矩形描述符对方向变化敏感。因此,具有T / L模板的方向性的描述符来描述顶点的方法已在DMPR-PS中应用。尽管此描述符对方向变化更鲁棒,但它只能提取T / L形等垂直的停车位,不适用于描述复杂的非T / L形场景,例如倾斜和梯形停车位。
同时,各种停车位顶点没有固定的模式,这使得很难找到一种通用的方式来描述不同的停车位顶点。为解决这一问题,在本文中提出了一种可变形的圆描述符,以学习不同类型的停车位顶点的特征模式。对于不同类型的停车位顶点,使用相应的特征模式作为停车位顶点的描述子。因此,该描述符可以与不同类型的停车位检测任务兼容并且具有更好的归纳能力。
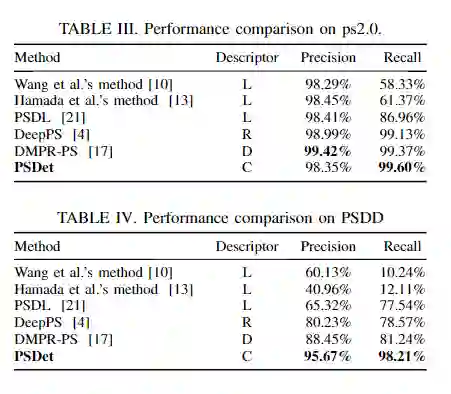
表I列出了不同的停车位检测方法的比较。
此外,网络的计算开销严重限制了深度学习算法在实际工程应用中的应用。例如,DeepPS 和DMPR-PS 需要强大的GPU来运行深度学习算法。但是,批量生产的嵌入式环境仅具有CPU或功能较弱的GPU。尽管DMPR-PS是为嵌入式系统的任务而设计的,但是在没有强大的GPU的情况下仍然难以进行实时检测。在这种情况下,迫切需要寻找一种高效的时隙检测算法。为此,本文以粗糙到精细的方式解决了该任务,以降低网络的模型复杂度。
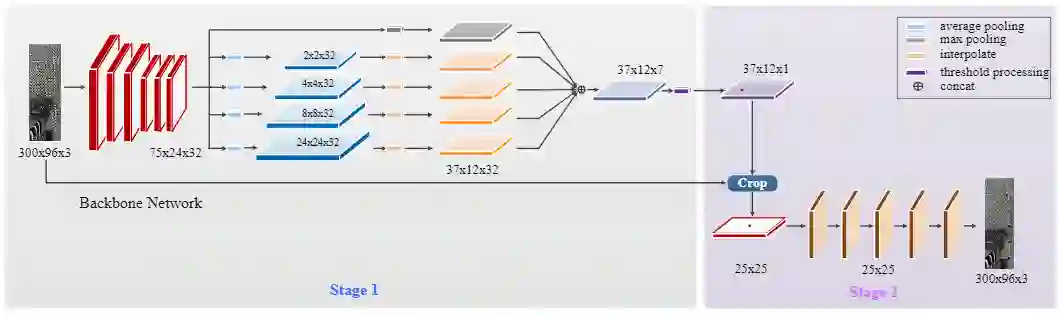
图1.本文提出的PSDet的体系结构。该模型是一个级联结构,第一级主要由backbone,几次下采样操作和插值过程组成。将这些插值后的特征图连接起来以获得包含标记点初始位置的特征图。在第二阶段中,将在第一阶段中获得的标记点的粗略位置作为中心来裁剪子图像,这些子图像被用作卷积神经网络的输入。最后,检测子图像中标记点的准确位置。
具体来说,本文的算法将任务分解为两个阶段,如图1所示。特别地,第一阶段学习回归标记点的粗略位置。这表明由于任务的简单性,第一阶段的优化具有快速收敛性。第二阶段将裁剪的子图像作为输入以预测的粗略位置为中心,并输出更精细的位置以进一步提高性能-粗略位置与ground truth之间的偏移。同时,在两个阶段使用大小不同的圆形描述符,粗略阶段(即第一阶段)比精细阶段(即第二阶段)使用更大的圆形描述符。
此外,为了验证实际应用中的性能,本文收集并标注了大规模benchmark停车位检测数据集(PSDD),该数据集由7种停车场景组成,包括砖、草、斜面、梯形、开放、矩形和立体停车位。实验证明了本文的方法在PSDD和ps2.0数据集上的有效性和效率。结果表明,PSDet在实现竞争性能的同时,其计算复杂度要比其他方法小得多。
在现有的停车位检测方法中,很难找到通用的特征描述符来描述具有复杂和可变类型的停车位顶点。因此,本文将各种类型的停车位顶点定义为通用特征表达,并使用该范式描述不同类型的停车位顶点。与以前的矩形描述符和方向描述符相比,本文提出的圆形描述符可以描述不同类型的停车顶点模式。
顶点特征的概念
顶点特征是标记点周围的相邻像素的公共模式,它表示标记点周围的可变形标记线之间的重叠关系,如图3所示。
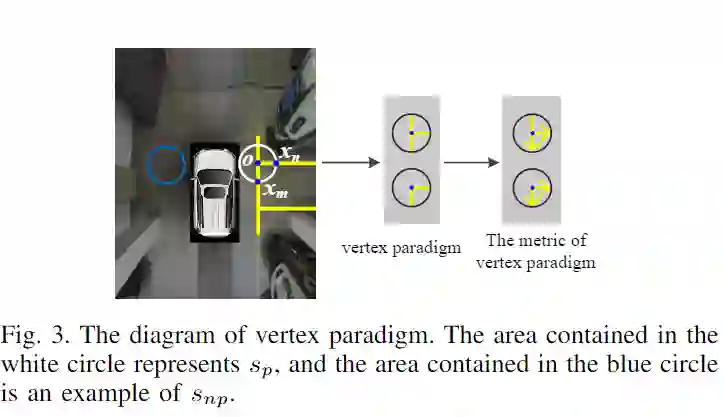
顶点区域和非顶点区域:顶点区域是包含停车线顶点的像素集合。非顶点区域是不以任何停车位顶点为中心的像素集合。
顶点特征的评价指标:

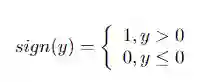
圆形描述符
为了描述停车位顶点区域p的顶点特征,本文引入了一个圆形区域描述符。圆形描述符是可变形的圆形模板,可以包含半径足够大的各种类型的停车位顶点。图4描绘了不同停车位的圆形描述符。圆形描述符能够提取更常见的图案并帮助解决非L-形状和非T形情况,例如倾斜、砖块和梯形等。圆形描述符能够包含各种类别的图案。这些圆形描述符可以根据不同标签给出的相应特征模式来学习,如图4所示。

顶点的下界
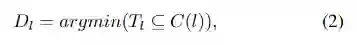
顶点的上界
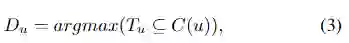
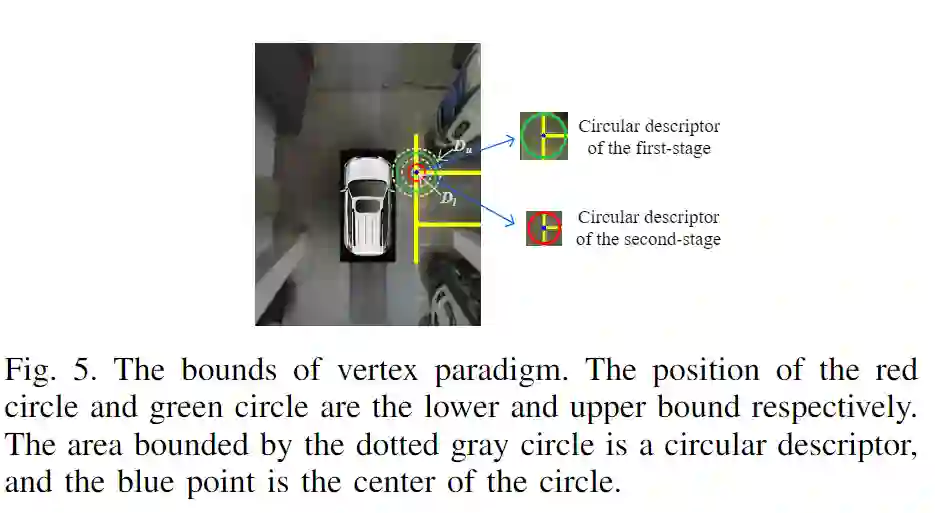
图1.本文提出的PSDet的体系结构。该模型是一个级联结构,第一级主要由backbone,几次下采样操作和插值过程组成。将这些插值后的特征图连接起来以获得包含标记点初始位置的特征图。在第二阶段中,将在第一阶段中获得的标记点的粗略位置作为中心来裁剪子图像,这些子图像被用作卷积神经网络的输入。最后,检测子图像中标记点的准确位置。
1、实现细节
级联结构:首先计算顶点区域候选,然后回归到精确的顶点位置。更精确地说,在第一阶段,提取顶点的近似区域,以初步粗略地定位标记点。然后,从输入图像中裁剪以第一阶段生成的顶点候选为中心的子图像。此外,利用第二阶段网络将精确的顶点位置从子图像中以偏移的形式回归到粗略的顶点候选。
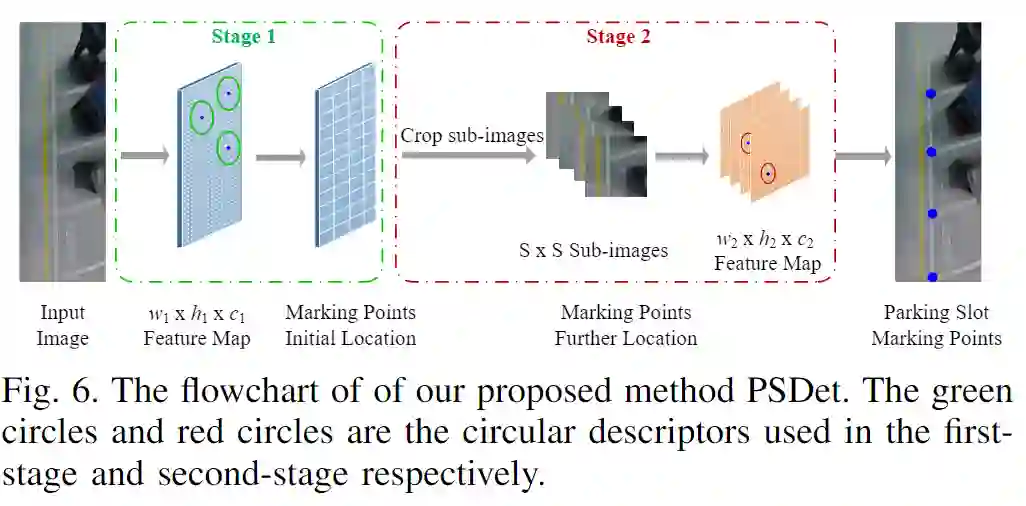
First Stage:给定一个320×240的全景图像I,裁剪成两个320×96的图像,并以I的左侧和右侧作为初始边界。然后从320×96图像中提取出一组特征图,如图1所示。此外,金字塔网络被用于提取具有不同分辨率的特征图,这可以将缩放鲁棒性引入网络。然后,将这些特征图插值入到固定大小,并concat到合并的特征图中。因此,获得了一系列大小为w1×h1×c1的特征图,如图6所示。例如,将其中一个特征图命名为M,将M中点的值命名为M(i,j)。(i,j)可以看作是输入图像对第一阶段圆形描述符的响应强度。此外,M(i,j)通过softmax归一化为[0,1],如等式(5)所示。最后,保留其归一化值M′(i,j)≥0.5的点位置(i,j)作为停车位的顶点候选。
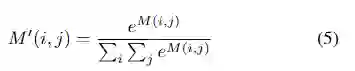
Second Stage:在第一阶段获得标记点的初始位置之后,以顶点候选的位置为中心,从输入图像中裁剪出一系列S×S子图像。然后使用基于CNN的回归模型和第二阶段圆形描述符模板进一步检测子图像中的所有顶点。最后,将输出特征图上响应强度最高的点的位置保留为停车位顶点的最终位置,并在第一阶段相应地纠正停车位顶点候选的位置偏差。这样,停车位的准确位置检测到停车位标记点。
2、损失函数
First Stage Loss.
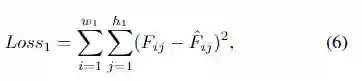
Second Stage Loss
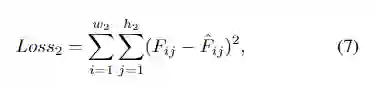
数据集PSDD制作:
PSDD数据集由从典型的室内和室外停车位收集的14628个校准的环视图像组成。对21种视频序列中的图像进行采样,这些视频序列在7种不同场景中捕获。每个场景有3个序列,进行帧拆分后,对PSDD中的样本进行过滤,从而得到14628个样本。数据集中每个类别数据的数量是不同的,这是由于现实应用中不同停车位的广泛普及,例如矩形停车位和开放式停车位最为常见。露天停车位类别共有3342个样本,矩形停车位类别共有5667个样本,草木停车位类别共有1242个样本,立体停车位类别共有63个样本,梯形停车位类别共有1946个样本,斜停车位类别共有500个样本,砖停车位类别共有1868个样本。一组样本如图7所示,所有实验中训练集与测试集的比例为1:1。

可视化测试
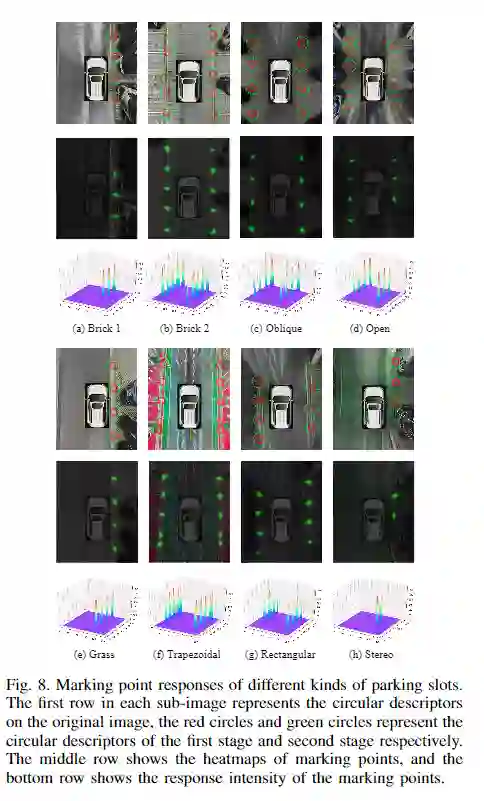
对比实验

实时性测试

更多实验细节,可以参考原文。
论文下载
在CVer公众号后台回复:停车位检测,即可下载本论文和PSDD数据集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer一个在看!



