关于知识图谱,各路大神最近都在读哪些论文?

本期内容选编自微信公众号「开放知识图谱」。
TheWebConf 2018

■ 链接 | https://www.paperweekly.site/papers/1956
■ 解读 | 花云程,东南大学博士,研究方向为自然语言处理、知识图谱问答
动机
对于 KBQA 任务,有两个最为重要的部分:其一是问题实体识别,即将问题中的主题实体识别出来,并与 KB 做实体链接;其二是谓词映射。
对于主题实体识别任务,之前的做法多为依靠字符串相似度,再辅以人工抽取的特征和规则来完成的。但是这样的做法并没有将问题的语义与实体类型、实体关系这样的实体信息考虑进来。
实体类型和实体关系,很大程度上,是与问题的上下文语义相关的。当只考虑实体关系时,会遇到 zero-shot 的问题,即测试集中某实体的关系,是在训练集中没有遇到过的,这样的实体关系就没法准确地用向量表达。
因此,为了解决上述问题,本文首先利用 entity type(实体类型)的层次结构(主要为实体类型之间的父子关系),来解决 zero-shot 的问题。
如同利用 wordnet 计算 word 相似度的做法一般,文章将父类型的“语义”视为所有子类型的“语义”之和。一个实体总是能够与粗颗粒的父类型相关,例如一个实体至少能够与最粗颗粒的 person、location 等类型相连。这样,利用实体所述的类型,在考虑实体上下文时,就可以一定程度上弥补实体关系的 zero-shot 问题。
此外,本文建立了一个神经网络模型 Hierarchical Type constrained Topic Entity Detection (HTTED),利用问题上下文、实体类型、实体关系的语义,来计算候选实体与问题上下文的相似度,选取最相似的实体,来解决 NER 问题。
经过实验证明,HTTED 系统对比传统的系统来说,达到了目前最优的实体识别效果。
贡献
文章的贡献有:
利用父子类型的层次结构来解决稀疏类型训练不充分的问题;
设计了基于 LSTM 的 HTTED 模型,进行主题实体识别任务;
提出的模型通过实验验证取得了 state-of-art 的效果。
方法
本文首先对于父子类型的层次结构进行解释和论述,也是 HTTED 的核心思想。
本文认为,父类型的语义视为接近于所有子类型的语义之和。例如父类型 organization 的语义,就相当于子类型 company、enterprise 等语义之和。如果类型是由定维向量表示,那么父类型的向量就是子类型的向量之和。
此外,由于在数据集中,属于子类型的实体比较稀疏,而父类型的实体稠密,如果不采用文中的方法,那么稀疏的子类型将会得不到充分的训练。若将父类型以子类型表示,那么父子类型都可以得到充分地训练。
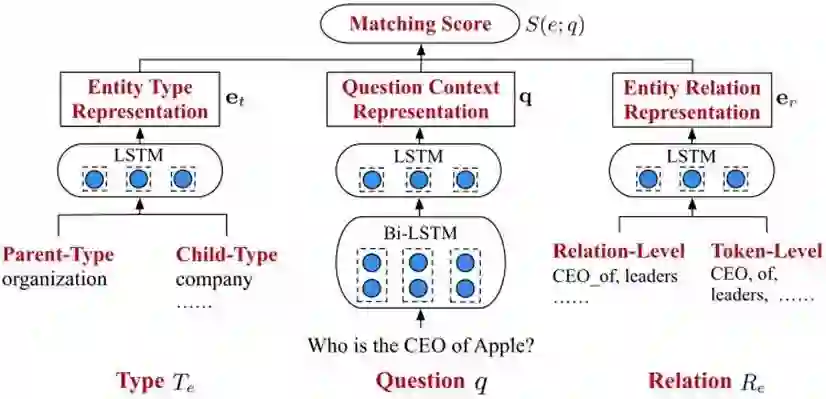
▲ 图1:HTTED模型图
其次是对文中模型的解释。如上图 1 所示,HTTED 使用了三个编码器来对不同成分编码。
其一,是问答上下文编码器,即将问题经过分词后得到的 tokens,以预训练得到的词向量来表示,并依次输入双向 LSTM 进行第一层的编码;此后,将双向 LSTM 得到的输出拼接,再输入第二层的 LSTM 进行编码,即得到表示问题上下文的 d 维向量 q。
其二,是实体类型编码器,即对于某个候选实体 e,得到其连接的类型,并将父类型以所有子类型向量之和表示,再将这些类型对应的向量输入一个 LSTM 中进行编码,得到实体类型的 d 维向量 et。
其三,是实体关系编码器,即对于某个候选实体 e,得到其所有实体关系,并表示成向量。此外,对于实体关系,将其关系名切割为 tokens,并以词向量表示。然后将实体关系和实体关系名这两种向量,输入一个 LSTM 中进行编码,得到实体关系的d维向量 er。
得到三个向量后,文章认为实体的语义可以由实体类型、实体关系近似表达,所以有:
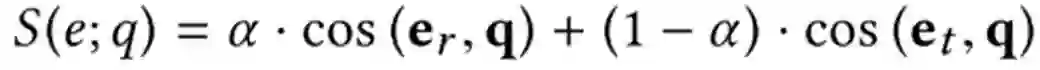
而在训练时,设置一个 margin,则 ranking loss 为:
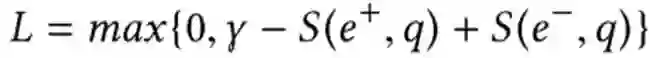
其中 γ 为超参数。
实验结果
文章使用单关系问答数据集 SimpleQuestions 和知识图谱 FB2M,并有 112 个具有层次父子关系的实体类型。
HTTED 的词向量为经过预训练的,关系向量是初始随机的,而类型向量中,叶子类型初始随机,父类型的向量由子类型的向量累加得到。如下图 2 所示,为 HTTED 与其他系统的效果对比,其中 -Hierarchy表示 HTTED 去除了实体类型的层次结构表示。
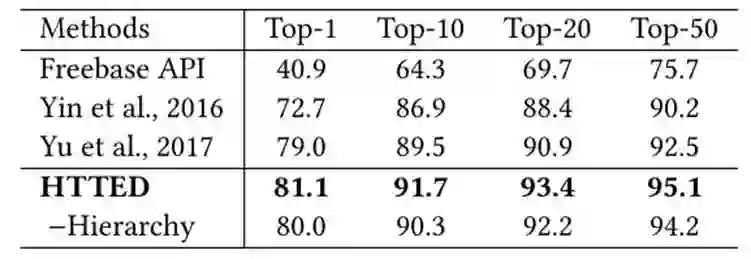
▲ 图2:主题实体识别效果对比图
由图 2 可见,HTTED 为 state-of-art 的效果。并且,将实体类型的层次结构去除,HTTED 的准确性下降很多。可见层次类型约束对于该模型的重要性。
由下图 3 可见,由于使用了层次结构的类型,同名的实体被识别出来,但是与问题上下文更相关的实体都被挑选出来,所以能够正确识别到主题实体。
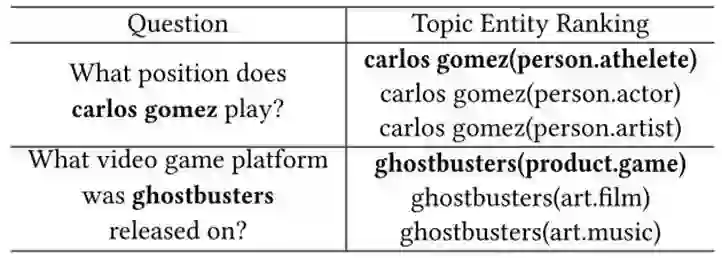
▲ 图3:主题实体识别示例图
总结
这篇文章,主要有两个主要工作:其一,是引入了层次结构的实体类型约束,来表达实体的语义,使得与问题上下文相关的实体,更容易被找到;其二,是建立了基于 LSTM 的 HTTED 模型,提高了主题实体识别的效果。
AAAI 2018

■ 链接 | https://www.paperweekly.site/papers/1957
■ 解读 | 张文,浙江大学博士生,研究方向知识图谱的分布式表示与推理
动机
知识图谱的分布式表示旨在将知识图谱中的实体和关系表示到连续的向量空间中,本文考虑的问题是如何将知识库的分布式表示和逻辑规则结合起来,并提出了一个新的表示学习方法 RUGE (Rule-Guided Embedding)。
贡献
1. 本文提出了一种新的知识图谱表示学习方法 RUGE,RUGE 在向量表示 (embeddings) 的学习过程中迭代地而非一次性地加入了逻辑规则的约束;
2. 本文使用的是已有算法自动挖掘的规则,RUGE 的有效性证明了算法自动挖掘的规则的有效性;
3. 本文提出的方法 RUGE 具有很好的通用型,对于不同的逻辑规则和不同置信度的规则的鲁棒性较好。
方法 RUGE
RUGE 方法的输入有三个部分:
已标记的三原组:知识库中已有三元组;
未标记的三元组:知识库中不存在的三元组。在这篇论文中未标记的三元组只考虑了能够由逻辑规则推导出的三元组;
概率逻辑规则:本文主要考虑了一阶谓词逻辑规则,每一个逻辑规则都标有一个成立的概率值。实验中使用的概率规则来自于规则自动挖掘系统 AMIE+。
模型核心想法如下:

三元组表示:
本文采用了 ComplEx 作为基础的知识库分布式表示学习的模型,在 ComplEx中,每一个实体和关系都被表示为一个复数向量,一个三元组 (e_i,r_k,e_j) 的得分函数设计如下:
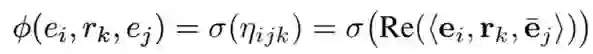
其中 Re<x> 表示取 x 实部的值,bar{e}_j 为 e_j 的共轭向量。正确的三元组得分函数值会较高而不正确的三元组得分函数的值会较低。
逻辑规则的表示:
本文借鉴了模糊逻辑的核心思想,将规则的真值看作其组成部件真值的组合。例如一个已经实例化的规则 (e_u, e_s,e_v) =(e_u, e_t,e_v) 的真值将由 (e_u, e_s,e_v) 和 (e_u, e_t,e_v) 的真值决定。根据(Guo et al. 2016)的工作,不同逻辑算子的真值计算如下:
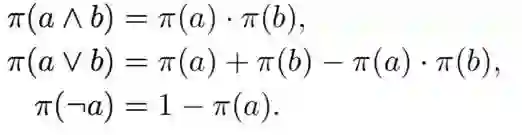
由上三式可推出规则真值计算公式:
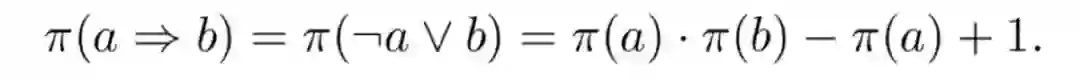
此规则计算公式是后面规则应用的一个重要依据。
未标记三元组标签预测:
这一步是整个方法的核心,目的在于对未标记三元组的标签进行预测,并将这些三元组添加到知识图谱中,再次进行知识图谱的分布式表示学习训练,修正向量结果。
标签预测的过程主要有两个目标:
目标一:预测的标签值要尽可能接近其真实的真值。由于预测的三元组都是未标记的,本文将由当前表示学习的向量结果按照得分函数计算出的结果当作其真实的真值。
目标二:预测的真值要符合对应逻辑规则的约束,即通过规则公式计算出的真值要大于一定的值。其中应用的规则计算公式如下:
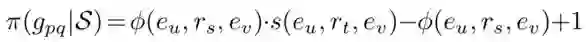
其中 φ(e_u, e_s,e_v) 是当前向量表示计算的结果,s(e_u, e_t,e_v) 是要预测的真值。真值预测的训练目标如下:
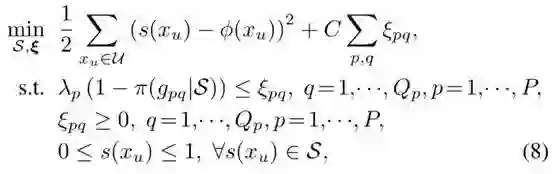
通过对上式对求 s(x_u) 导等于 0 可得到 s(x_u) 的计算公式:

向量表示结果的修正:
将预测了标签的三元组添加到知识图谱中,和已由的三元组一起进行训练,来修正向量学习,优化的损失函数目标如下:
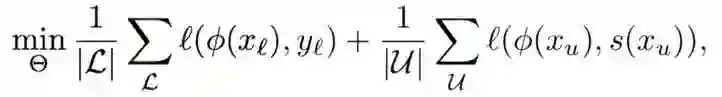
上式前半部分是对知识图谱中真实存在的三元组的约束,后半部分为对预测了标签的三元组的约束。
以上步骤在模型训练过程中迭代进行。
实验
链接预测:
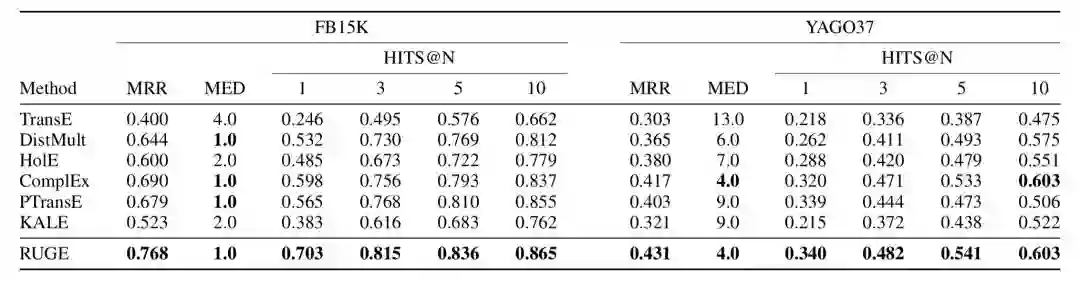
从实验结果可以看出,规则的应用提升了表示学习的结果。
EMNLP 2017

■ 链接 | https://www.paperweekly.site/papers/713
■ 解读 | 刘兵,东南大学在读博士,研究方向为自然语言处理
动机
近年来基于深度学习方法的远程监督模型取得了不错的效果,但是现有研究大多使用较浅的 CNN 模型,通常一个卷基层加一个全连接层,更深的 CNN 模型是否能够更好地解决以有噪声的标注数据为输入的远程监督模型没有被探索。
为了探索更深的 CNN 模型对远程监督模型的影响,本文设计了基于残差网络的深层 CNN 模型。实验结果表明,较深的 CNN 模型比传统方法中只使用一层卷积的简单 CNN 模型具有较大的提升。
方法
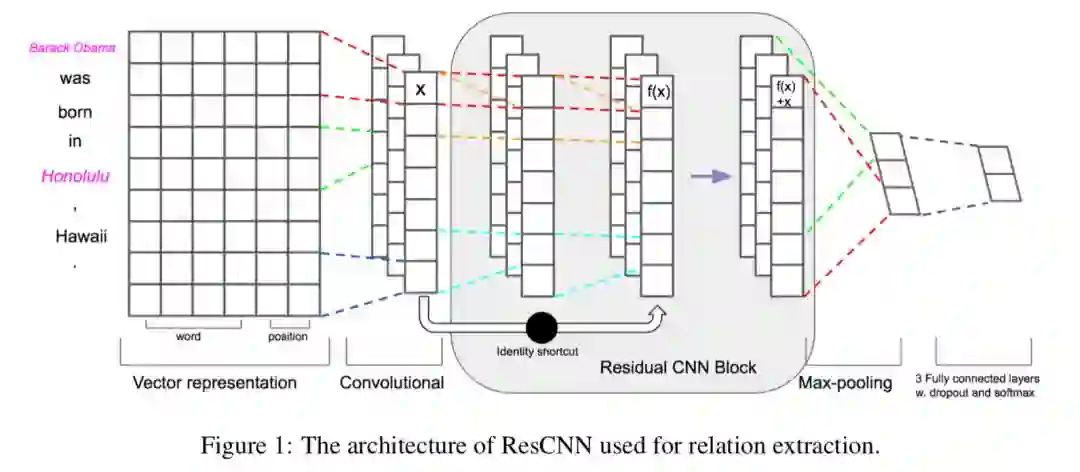
本方法的模型结构如下图所示:
输入层:每个单词使用词向量和位置向量联合表示;
卷基层:为了得到句子更高级的表示,采用多个卷基层堆叠在一起。为了解决训练时梯度消失的问题,在低层和高层的卷基层之间建立捷径连接;
池化层和 softmax 输出层。
实验
实验在远程监督常用的数据集 NYT-Freebase 上进行。实验结果表明:
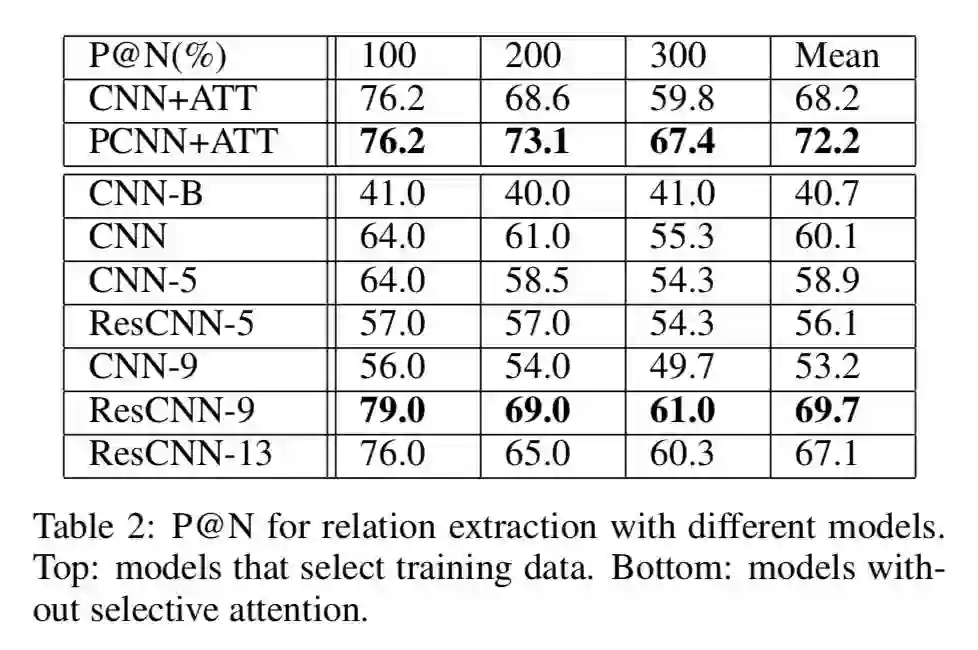
本文提出的方法采用 9 个卷基层时达到最好的效果,这时不适用注意力机制和 piecewise pooling 性能也接近了使用注意力和 piecewise pooling 的方法。结果如下表所示。
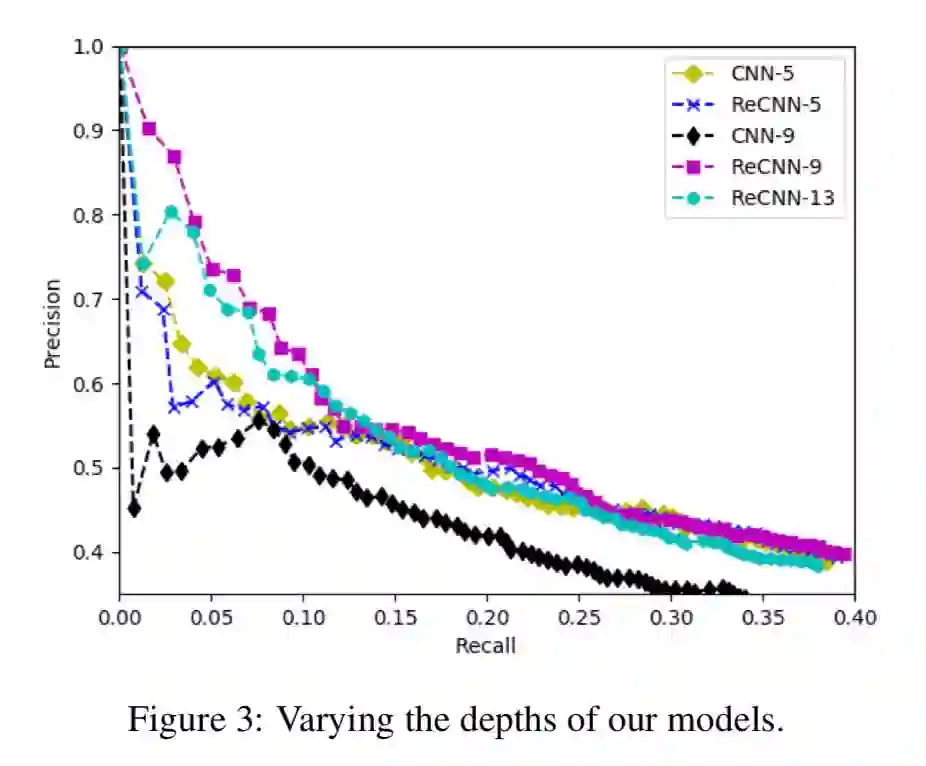
不使用残差网络的深层 CNN 模型,当层数较深时效果变差。使用残差网络可以解决其无法传播的问题,效果改善很多;结果如下图所示。
EMNLP 2017

■ 链接 | https://www.paperweekly.site/papers/1960
■ 源码 | http://github.com/LiyuanLucasLiu/ReHession
■ 解读 | 刘兵,东南大学博士,研究方向为自然语言处理
动机
现有的关系抽取方法严重依赖于人工标注的数据,为了克服这个问题,本文提出基于异种信息源的标注开展关系抽取模型学习的方法,例如知识库、领域知识。
这种标注称作异源监督(heterogeneous supervision),其存在的问题是标注冲突问题,即对于同一个关系描述,不同来源的信息标注的结果不同。这种方法带来的挑战是如何从有噪声的标注中推理出正确的标签,以及利用标注推理结果训练模型。
例如下面的句子,知识库中如果存在 <Gofraid,born_in, Dal Riata> 这个三元组,则将下面的句子标注为 born_in 关系;而如果使用人工模板“* killed in*”进行匹配,则会将该句子标注为 kill_in 关系。
Gofraid(e1) died in989, said to be killed in Dal Riata(e2).
为了解决这个问题,本文提出使用表示学习的方法实现为关系抽取提供异源监督。
创新点
本文首次提出使用表示学习的方法为关系抽取提供异源监督,这种使用表示学习得到的高质量的上下文表示是真实标签发现和关系抽取的基础。
方法
文章方法框架如下:
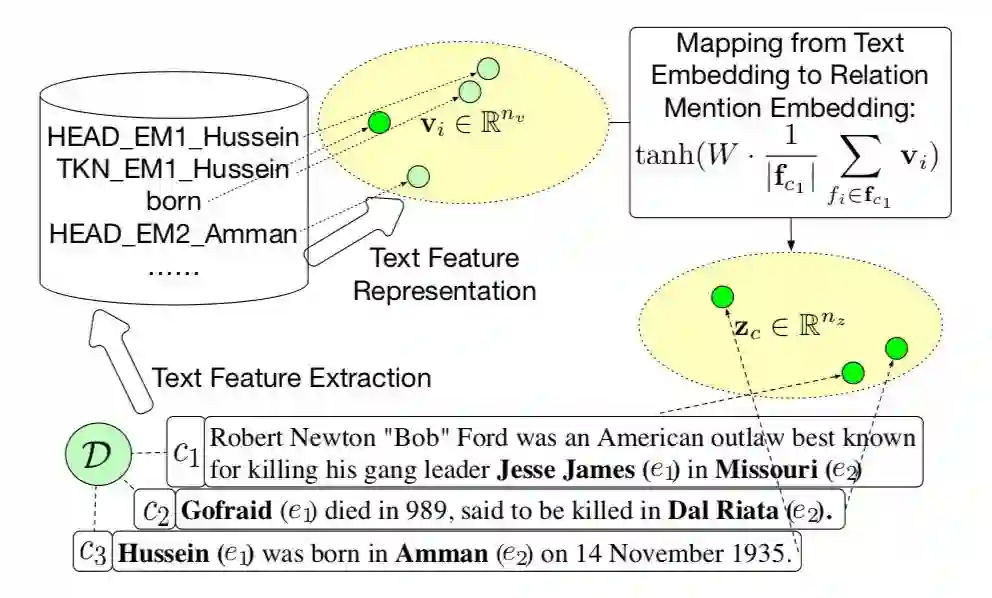
▲ 关系描述表示方法
1. 文本特征的向量表示。从文本上下文中抽取出文本特征(基于pattern得到),简单的one-hot方法会得到维度非常大的向量表示,且存在稀疏的问题。为了得到更好的泛化能力,本文采用表示学习的方法,将这些特征表示成低维的连续实值向量;
2. 关系描述的向量表示。在得到文本特征的表示之后,关系描述文本依据这些向量的表示生成关系描述的向量表示。这里采用对文本特征向量进行矩阵变换、非线性变换的方式实现;
3. 真实标签发现。由于关系描述文本存在多个可能冲突的标注,因此发现真实标签是一大挑战。此处将每个标注来源视为一个标注函数,这些标注函数均有其“擅长”的部分,即一个标注正确率高的语料子集。本方法将得到每种标注函数擅长的语料子集的表示,并以此计算标注函数相对于每个关系描述的可信度,最后综合各标注函数的标注结果和可信度,得到最终的标注结果;
4. 关系抽取模型训练。在推断了关系描述的真实标签后,将使用标注的语料训练关系抽取器。
值得指出的是,在本方法中,每个环节不是各自独立的,真实标签发现与关系抽取模型训练会相互影响,得到关系上下文整体最优的表示方法。
实验结果
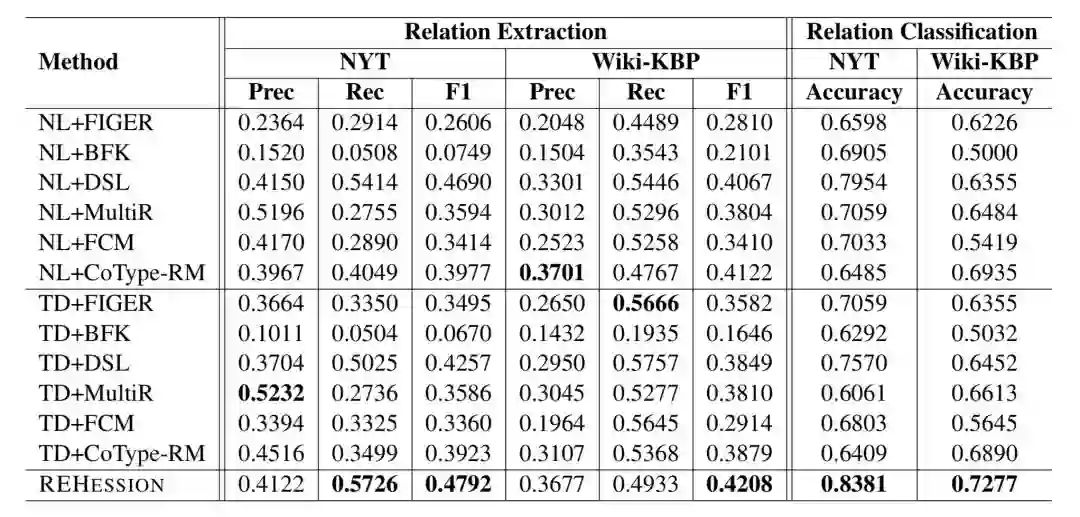
本文使用 NYT 和 Wiki-KBP 两个数据集进行了实验,标注来源一方面是知识库,另一方面是人工构造的模板。每组数据集进行了包含 None 类型的关系抽取,和不包含 None 类型的关系分类。
结果如下表所示,可见本文的方法相比于其他方法,在两个数据集的四组实验中均有较明显的性能提升。
ACL 2017

■ 链接 | https://www.paperweekly.site/papers/1961
■ 源码 | https://github.com/stanfordnlp/cocoa
■ 解读 | 王旦龙,浙江大学硕士,研究方向为自然语言处理
本文研究了对称合作对话(symmetric collaborative dialogue)任务,任务中,两个代理有着各自的先验知识,并通过有策略的交流来达到最终的目标。本文还产生了一个 11k 大小的对话数据集。
为了对结构化的知识和非结构化的对话文本进行建模,本文提出了一个神经网络模型,模型在对话过程中对知识库的向量表示进行动态地修改。
任务
在对称合作对话任务中,存在两个 agent,每个代理有其私有的知识库,知识库由一系列的项(属性和值)组成。两个代理中共享一个相同的项,两个代理的目标是通过对话找到这个相同的项。
数据集
本文建立了一个对称合作对话任务数据集,数据集中知识库对应的 schema 中包含 3000 个实体,7 种属性。数据集的统计信息如下所示:

模型
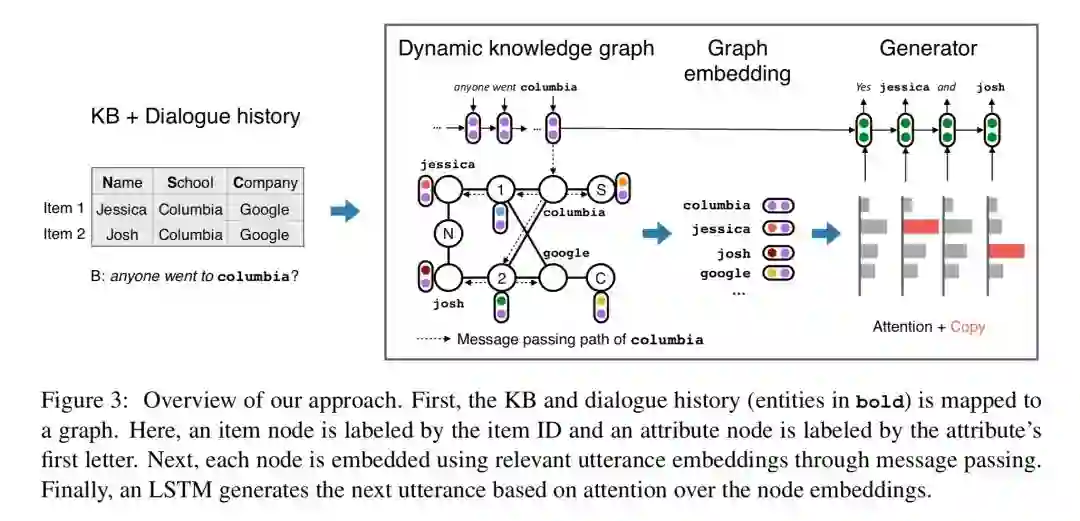
针对对称合作对话任务,本文提出了 DynoNet (Dynamic Knowledge GraphNetwork),模型结构如下所示:
Knowledge Graph
图谱中包含三种节点:item 节点,attribute 节点,entity 节点。图谱根据对话中的信息进行相应的更新。
Graph Embedding
t 时刻知识图谱中每个节点的向量表示为 V_t(v),向量表示中包含了以下来源的信息:代理私有知识库的信息,共享的对话中的信息,来自知识库中相邻节点的信息。
Node Features
这个特征表示了知识库中的一些简单信息,如节点的度(degree),节点的类型。这个特征是一个 one-hot 编码。
Mention Vectors
Mentions vector M_t(v) 表示在 t 时刻的对话中与节点 v 相关的上下文信息。对话的表示 u_t 由个 LSTM 络计算得到(后文会提到),为了区分 agent 自身产生的对话语句和另一个代理产生的对话语句,对话语句表示为:
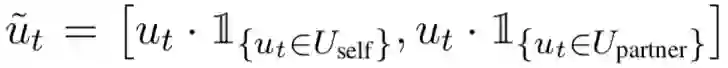
Mentions Vector 通过以下公式进行更新:
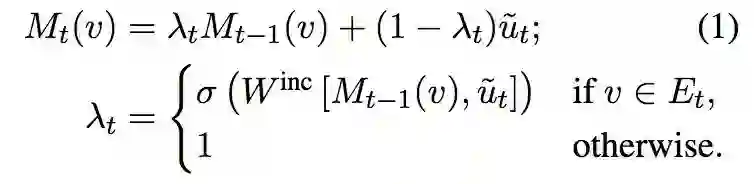
Recursive Node Embeddings
一个节点对应的向量表示也会受到相邻其他节点的影响:
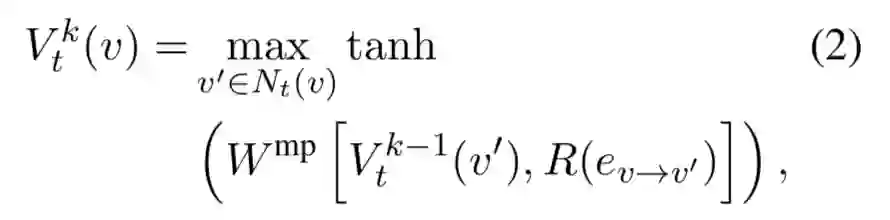
其中 k 表示深度为 k 的节点,R 表示边对应的关系的向量表示。
最后节点的向量表示为一系列深度的值的连接结果。
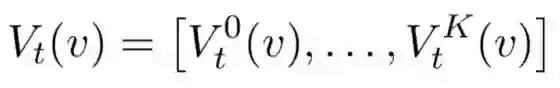
本文中使用了:
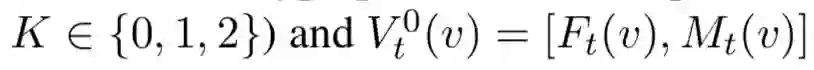
Utterance Embedding
对话的向量表示 u_t 由一个 LSTM 网络计算得到。
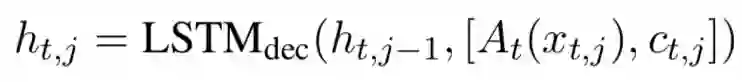
其中 A_t 为实体抽象函数,若输入为实体,则通过以下公式计算:
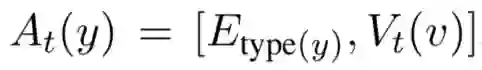
若不为实体,则为文本对应的向量表示进行 zero padding 的结果(保证长度一致)。
使用一个 LSTM 进行对话语句的生成:
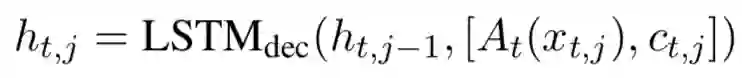
输出包含字典中的词语以及知识库中的实体:
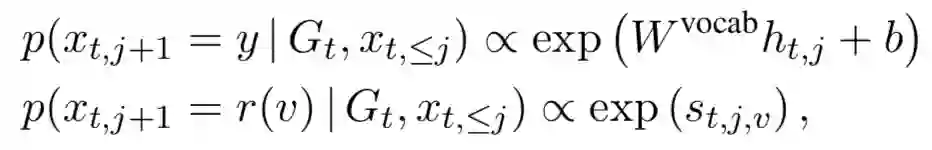
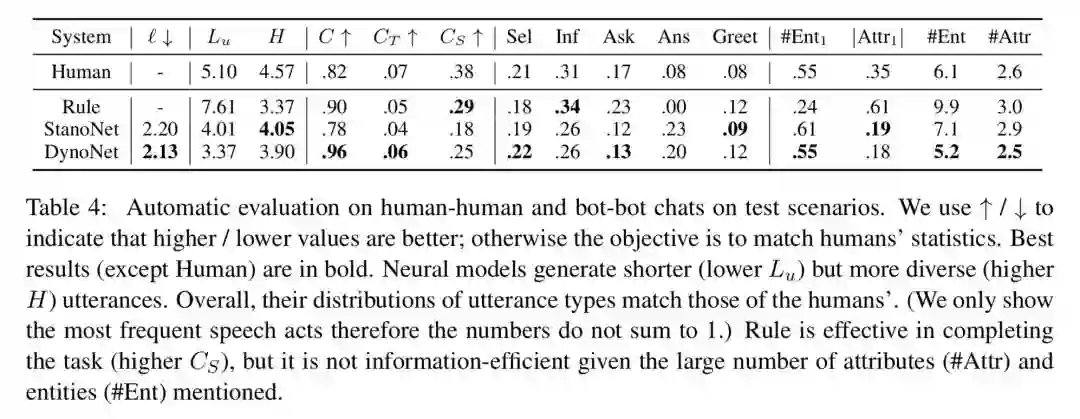
实验结果

点击以下标题查看更多相关文章:

▲ 戳我查看招募详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





