论文动态 | 基于知识图谱的问答系统关键技术研究 #04
本文转载自公众号 PaperWeekly。
作者丨崔万云
学校丨复旦大学博士
研究方向丨问答系统,知识图谱
领域问答的基础在于领域知识图谱。对于特定领域,其高质量、结构化的知识往往是不存在,或者是极少的。本章希望从一般文本描述中抽取富含知识的句子,并将其结构化,作为问答系统的知识源。特别的,对于不同的领域,其“知识”的含义是不一样的。有些数据对于某一领域是关键知识,而对于另一领域则可能毫无意义。传统的知识提取方法没有考虑具体领域特征。
本章提出了领域相关的富含知识的句子提取方法,DAKSE。DAKSE 从领域问答语料库和特定领域的纯文本文档中学习富含知识的句子表示。本章在真实数据上的实验验证了 DAKSE 可以以很高的准确率和召回率提取出富含知识的句子。本章还进一步将 DAKSE 的结果应用于领域信息提取,以自动提取结构化的领域知识。
当我们在阅读文档搜索目标信息时,人类并不会以稳定的速度来浏览所有的词语。相反,人的眼睛会四处移动,定位文本的有意义部分,并建立一个整体的感知。扫视的能力能帮助人类跳过大量无用的信息,并专注于富含知识的句子。这引发了一个问题:机器如何像人类一样提取富含知识的句子?这个问题在本文中被称为富含知识句子的抽取问题。
例如,当阅读示例 7.1 中的斯坦福大学的语料库时,AI 研究者会认为句子 s1 富含更多的信息,给予更多的关注。相比之下,大学生可能跳过 s1,但会关注 s2。因此,一个句子是否富含知识对于不同的用户是不同的。富含知识的句子提取系统需要为 AI 研究人员提取 s1,为大学生提取 s2。

从纯文本抽取知识的问题已经作为开放信息抽取(Open IE),关系抽取和句子抽取被进行了研究。开放信息抽取从纯文本中提取所有的结构化关系。关系抽取只提取指定的关系(例如来自知识库的谓词)。句子抽取提取有意义的句子,通常用于文档概括问题。富含知识的句子提取与这三个问题的专注点不同。
与开放信息抽取相比,富含知识的句子抽取着重于抽取句子。如示例 7.1 所示, 一个句子是否富含知识取决于不同用户的需求。一个统一的开放信息抽取框架是不知道不同用户的需求的。在示例 7.1 中,开放信息抽取系统不能为不同的用户分别提取 s1 和 s2。因此,开放信息抽取不能直接用于富含知识的句子抽取。
与关系抽取相比,富含知识的句子提取是无监督的。关系提取仅识别指定的关系, 而不同的用户关注不同的关系。在例子 7.1,通过知道“学费”对于在校大学生是富含 知识的关系,关系抽取系统可以从 s2 中为大学生抽取相应的知识。然而,对于不同的不同用户,他们有多样的需求,并且对于特定需求的一个定义良好的模式标注数据是不存在的。在大多数情况下,一个领域往往没有预定义模式和大量的标签数据。这使得对于来自不同用户的多种需求,关系提取是不适用的。
与句子提取相比,富含信息的句子提取可以满足用户不同的兴趣。但是一个句子在句子抽取中是否“有意义”是和用户无关的。
富含知识的句子抽取的关键是连接句子的知识和用户的需求。然而,这种需求对于不同的用户是不同的。而通常没有足够的数据来完全描绘一个人的特定需求。如示例 7.1 中所建议的,领域是自定义需求的关键特征。只有当抽取系统确定 s1 属于 AI 领域, 它才会将其识别对于AI研究者的富含知识的句子。本文的目的是识别领域相关的富含知识的句子(DKS)。
为了使抽取方法能够处理领域需求,本章使用了领域问答语料库。在给定领域的 QA 语料库中,答案句子对于该领域肯定是富含知识的。系统学习答案句子的表示方法。如果某个句子具有类似的表示,它将被识别为 DKS。
在学习一个领域的句子表示的时候,传统的模型包括 主题模型和语言模型。 但是它们不能直接用于富含知识句子的提取。富含知识句子的抽取问题和它们主要有两个区别:(1)QA 语料库的答案和句子在纯文本格式的表示不一样。一些元素通常在 答案中会被省略。比如在示例 7.1 中,答案中省略了实验室的名称。因此,直接学习答案的表示通常会导致纯文本中的句子识别的更多错误。(2)当从纯文本学习句子表示时,其上下文是重要的特征。传统模型的着重于表示句子本身,而没有考虑它的上下文。
本文提出了一种数据驱动方法 DAKSE,它包含无监督的种子 DKS 标记和有监督的 DKS 分类。DAKSE 首先通过匹配纯文本句子和回答语句来标记种子 DKS。这样就弥合了它们之间的差距。然后系统进一步使用神经网络来学习 DKS 分类器。该网络包含用于对候选语句和其上下文句子建模的三个并行的 LSTM。
应用:富含知识的句子抽取的结果不止可以判定一个句子对于用户是否是富含知识的,对以下几个 NLP 任务也是有益的:
领域信息抽取 开放信息抽取从给定语料库中提取所有结构化三元组。因此,如果开放信息抽取使用富含知识句子抽取系统抽取的句子,那么它就可以提取特定领域的三元组。
问答系统 QA 系统依赖大量的问答语料对进行训练。但现有的问答语料对是有限的。因此,从纯文本自动生成问答语料对可以丰富 QA 语料库。而富含知识的句子实际上就是问题的答案。自动问题生成技术可以被进一步用来生成完整的 QA 对。
自动摘要 文档摘要可以使用富含知识的句子提取作为预处理步骤,来识别有意义的句子。对领域知识的识别可以使得自动摘要更加定制化。
贡献 下面总结本章工作的贡献:
本章提出了富含知识的句子抽取的问题,并且分析了它的领域相关性。
本章提出了一种数据驱动方法 DAKSE,用于富含知识的句子抽取问题。本章使用 QA 语料库中的答案为给定领域生成种子 DKS。
本章在真实数据集上评估了 DAKSE 提取出的句子的效果,包括客户服务领域(中国移动客户服务)和百科全书领域(百度百科)。本章还将结果应用于领域信息的提取。
本章结构 本章的其余部分组织如下:首先概述了 DAKSE 的系统架构。接着,本章描述了 DAKSE 如何在预处理步骤中使用领域 QA 语料库来标记训练数据。然后详细阐述用于 DKS 分类的神经网络模型。最后展示了两个领域的实验结果,并将结果应用于领域信息提取。
本章中的工作涉及几个相关主题,包括开放信息抽取,知识库中的关系抽取和句子抽取。
开放信息抽取 开放信息抽取系统使用自由关系而不是预定义的模式从自然语言文本中抽取结构化信息。结果以(Beijing, is the capital of, China)的三元组形式展示。 现在已经出现了许多经典的开放信息抽取系统。TextRunner 首先引入了开放信息抽取问题。Reverb 揭示了 TextRunner 的两个典型问题:不相关信息抽取和非信息抽取。 Reverb 通过添加句法约束来解决 TextRunner 的这两个典型错误。Stanford open IE 进一步利用句子的语言结构来解决了长程依赖问题。这些开放信息抽取系统在很少监督的情况下提取知识。但用户往往只关注一些特定的主题或领域。这些系统会给具有特定需求的用户带来很多无用的元组。
关系抽取 关系抽取问题是指从自然语言文本中学习实体关系。它们通常以有监督的方式学习,需要很多带标记的样本用于训练模型。使用关系的自然语言模式从文本中提取新的关系。该方法的学习过程是迭代式的,在每次迭代中学习新的模式和新的关系。使用强化学习来生成新查询,同时更新提取的值。在关系提取中,这些关系是预定义的(比如来自知识库)。但在本章的问题中,对每个用户的有意义的关系是未知的。
句子抽取 专注于从文档中提取“有意义的”句子。该方法主要用于文档摘要任务。首先使用一个简单的贝叶斯分类器来提取句子和汇总文档。他们使用许多统计特征,如固定短语特征,大写字母特征来表示句子。自从那以后,很多方法被提出来解决这个问题,包括 TF-IDF 方法,基于图的方法,基于神经网络的方法。 这些句子提取方法从静态的角度考虑一个句子是否具有意义,“有意义”意味着一个句子可以总结文档。相反,本章认为某个句子是否有意义是动态的,它的意义取决于特定用户。也就是说,他们的方法没有考虑“领域”作为句子提取的特征。
图 7.1 展示了 DAKSE 的系统架构。在种子 DKS 标注模块中,系统利用 QA 语料库标记种子 DKS 来进行进一步训练。通过使用这些种子 DKS 作为训练数据,系统构建了一个深层神经网络(DKS 分类器)来学习这些种子 DKS 的表示。通过使用 DKS 分类器,DAKSE 在纯文本语料库中提取更多的 DKS。本节接下来会给出更多细节,同时给出一 个示例(例 7.2),展示 DAKSE 是如何工作的。
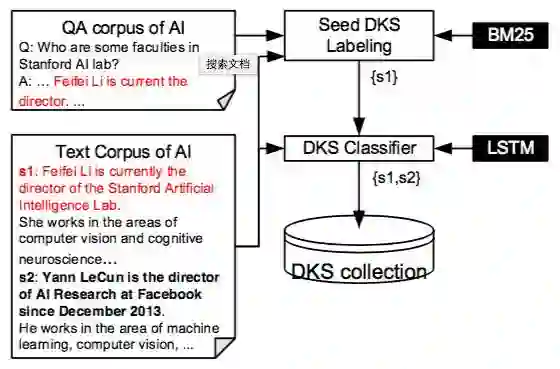
▲ 图 7.1:DAKSE 的系统架构
种子 DKS 标注是 DAKSE 识别种子 DKS 的预处理步骤。需要注意的是,在特定领域的 QA 语料库中的答案,对于该领域用户是富含知识的。但是由于答案和纯文本之间的差距,DAKSE 不直接使用这些答案作为种子 DKS。因为答案通常会省略元素,这使得它们的表示不同于纯文本的表示。这里系统认为如果纯文本语料库中的某个句子与至少一个 QA 语料库中的答案具有高相似性,那么它就是 DKS。通过这种方式,DAKSE 通过 QA 语料库来标记种子 DKS。然后在 DKS 分类器中学习这些种子 DKS 的表示。
DKS 分类器通过使用种子 DKS 作为训练数据,DAKSE 从纯文本中抽取的 DKS 学习一个深层神经网络。该模型将句子及其上下文句子视为特征。
例 7.2. 在图 7.1,DAKSE 试图从文本语料库中提取 AI 领域的 DKS。首先,在种子 DKS 标记模块中,系统产生种子 DKS。需要注意的是,直接使用答案作为种子 DKS 在这种情况下效果不好。因为 s2 与答案完全不同,很难根据答案将 s2 分类为 DKS。 DAKSE 首先计算纯文本语句和答案之间的相似性。它通过识别出 s1 与答案具有高相似性,将 s1 标记为种子 DKS。然后 DAKSE 学习 s1 的分类器,并使用分类器在文本语料库中提取新的 DKS。由于 s1 和 s2 非常相似,s2 也被归类为 DKS。注意这里上下文特征也有助于分类。
本节详细介绍种子 DKS 标注模块。该模块将纯文本语料库中的一些句子标记为种子 DKS。这些种子 DKS 会进一步用于训练 DKS 分类器。
为了确定一个句子是否是 DKS,DAKSE 利用领域 QA 语料库。如前文所述,领域 QA 语料库中的答案是富含知识的。如果一个纯文本句子与至少一个领域 QA 语料库中的答案具有高相似性,DAKSE 就认为它是种子 DKS。这里相似度使用 BM25 计算。
用 BM25 计算相似度给定一个纯文本语句 s1,一个回答语句 s2,和单词集合 w1 , ..., wn , 它们的 BM25 分数为:
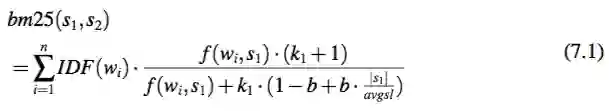
这里 IDF(wi) 是 wi 的逆文档频率权重(与该单词在 QA 语料中出现的文档个数有关),f (wi, s1) 是 wi’s 在 s1 中的词频,|s1| 是 s1 的长度 , avgsl 是纯文本语料库的平均句子长度。k1 和 b 是超参数。它们分别被设置为常用值:1.5 和 0.75。
如果存在一个答案语句 s2,使得 bm25 (s1,s2) > δ,那么系统标记这个纯文本语句 s1 为一个种子 DKS。根据前人经验,这篇论文设置 δ = 0.4。
本节详细说明 DKS 分类器。 DKS 分类器判断一个纯文本语料中的句子是否是一 个 DKS。它将种子 DKS 视为正确标准并从中学习。分类器考虑目标语句本身和其两个上下文语句作为分类的特征。系统为三个句子构建三个具有类似结构的三个并行网络(一个嵌入层和一个 LSTM 层)。然后系统在输出层中聚合它们的输出来生成目标句子的总得分。
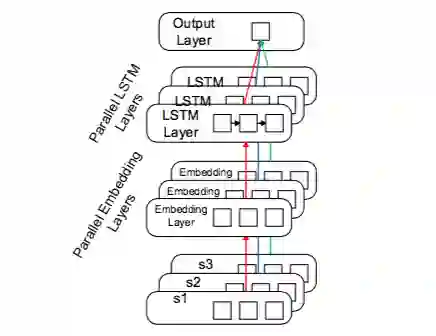
▲ 图 7.2:为 DKS 分类器构建的神经网络
词向量层为分别为每个句子使用单独的嵌入矩阵。更正式的说,对于一个有前驱句子 s2 和后继句子 s3 的目标句子 s1,句子 si 中的单词 w 使用词向量矩阵 Mi 来做向量化:

这里 r(w) ∈ {0, 1}|V| 是 w 的 one-hot 表示,|V| 是词汇表大小。
LSTM层 词向量层的结果被传递到 LSTM 层,LSTM 层用于对词序列的长依赖性进行建模。LSTM 层由存储器单元序列组成,每个单元从嵌入层和前驱单元获得输入。存储器单元具有四个基本元件:输入门,忘记门,状态存储单元和输出门。首先,忘记门接收来自嵌入层和前驱单元的输入,并且决定丢弃哪个值。然后输入门决定更新哪个值。状态存储单元存储更新的值。最后,输出门决定要输出什么。
这里使用的LSTM版本来自于论文 [108]。该模型记忆单元有如下复合函数:
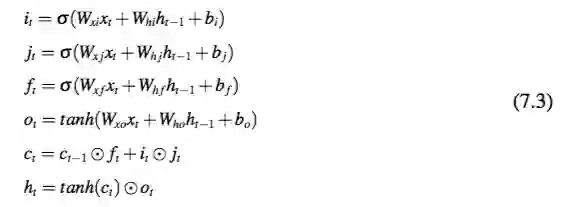
这里 σ 函数是一个 sigmoid 函数,i,f,o,c 分别是输入门,忘记门,输出门,单元激活向量,j 用于计算新的 c 值,W,b 是 LSTM 层的参数。
输出层:该层连接 LSTM 的结果,并使用 sigmoid 函数来确定目标语句的得分,来判断目标语句是否为 DKS。
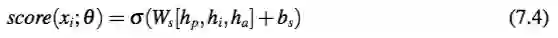
这里 hp、hi、ha 是 LSTM 层的三个输出,σ 是 sigmoid 函数,Ws、bs 是该层的参数。
模型训练 训练过程使用种子 DKS 标记模块标记出的种子 DKS 作为正样本训练数 据。模型将无意义的句子作为负样本训练数据。这些句子随机采样自中文小说。训练数据的更多细节可以在实验部分找到。模型使用二元交叉熵作为损失函数。令 X = {x1,...,xn} 为训练数据,这样每个 xi 包括目标语句和它的上一句语句和下一句语句,Y = {y1,y2,...,yn} 是它们对应的标签(0 或者 1)。对于参数 θ,xi 在输出层对应的输出分数为 score (xi;θ)。如果 score(xi;θ)≥0.5,模型预测 xi 的标签 fˆ(xi;θ)=1,否则为 0。对于参数 θ , 对应的目标函数为:
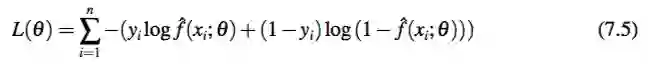
至于详细的实现,在训练过程使用随机参数初始化,利用反向传播算法来训练参数,使用 mini-batched AdaGrad 算法进行非凸优化,相应的学习率为 0.001,词向量的维度设置为 128,每个 LSTM 层包含 128 个单元。
6.1. 实验设置
所有的实验在一个双路 Intel CPU E5-2620 v2 @ 2.10GHz,128GB 内存,GeForce GTX 980 GPU 的机器上运行。
数据集:实验在两个领域应用 DAKSE:中国移动客户服务和百度百科。对于每个领域,实验首先通过种子 DKS 标记模块来标记种子 DKS。这些 DKS 被认为是正样本。然后实验添加相等数量的非 DKS 作为负样本。这些非 DKS 是从中文小说中随机选择的句子,小说中的句子通常来说不包含知识。

▲ 表 7.1:中国移动客服的前五 5DKSs
中国移动客户服务包含中国移动公司的服务文档。纯文本语料库包含 363354 个句子。 QA 语料库包含 9570 个 QA 对,它们是来自中国移动呼叫中心的常见问题及其答案。
百度百科是最大的中文百科。本实验从百度百科上抓取了 2074116 个句子。实验使用百度知道作为 QA 语料库,从中随机选取了 500000 个中的 QA 对。很多百度知道中的问题是和百度百科中的知识相关的。
基准实验:实验使用两个基础的方法来和 DAKSE 做对比。
主题模型+SVM 实验使用 LDA 来计算每个句子的主题分布。这些主题分布之后会被当作该句子的特征,用于 SVM 分类。实验将种子 DKS 标注模块得到的句子作为正样本,加入小说中的句子作为负样本。
语言模型 实验在种子 DKS 上训练出一个语言模型,对于一个新的句子,如果它的困惑度(Perplexity)小于一个给定的阈值,该模型认为它是一个 DKS。
6.2. 中国移动客户服务
本小节评估 DAKSE 在中国移动客户服务语料上的效果。首先,实验给出提取的 DKS 的直观感受,然后评估抽取出来的 DKS 的有效性。
DKS 概览:DAKSE 从纯文本语料库提取总共 63543 个 DKS。为了给出 DKS 的直观感受,表格 7.1 中列出了前 5 的 DKS(由 DKS 输出层中的分数排序,该分数表现了分类的置信度)。实验发现了一些有趣的结果如下:
DAKSE 提取出了领域富含知识的句子。所有这些 DKS 都是客户服务领域的信息。
DAKSE 提取了一些非常复杂的知识。例如 dks2 包含消息提醒关系中的不同角色:发送者(XXT 平台)、信息(服务将很快收费)、接受者等等。
抽取出来的 DKS 覆盖多种类型。
实验结果的有效性:实验通过两种方式来评估 DAKSE 是否可以很好地区分 DKS 和非 DKS。首先,通过假设种子 DKS 是正确的,实验评估 DKS 分类器是否很好地提取出了 DKS。实验选择 80% 的样本进行训练,其余的用于测试。训练过程从小说中添加相等数量的负样本。结果表示在表 7.2 中。
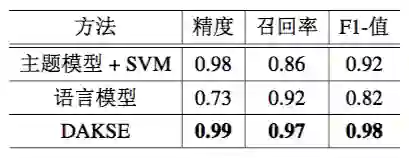
▲ 表 7.2:中国移动客户服务结果评估
同时使用手工标注来评估 DKS 的有效性。实验随机选择 100 个 DKS。并邀请来自相关领域的志愿者标记 DKS 是否包含目标领域的有效知识。所有 DKS 被手动分成三种类型:(1) 正确 如果 DKS 是目标领域的有效知识;(2) 不相关 如果 DKS 包含知识,但与目标领域不相关;(3) 不正确 如果 DKS 没有包含知识信息。结果展示在表 7.3 中。
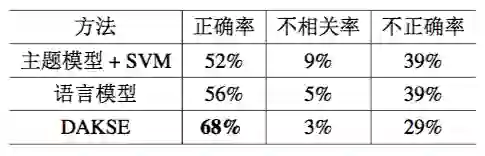
▲ 表 7.3:中国移动客户服务人工标签结果
表 7.2 和表 7.3 中的结果验证了 DAKSE 能够以很高的准确率和召回率抽取出 DKS。 这里手工标注的正确率略小于精度,因为表 7.2 中的正确标准中包含一些噪声(即一些标注为种子 DKS 的实际上是非 DKS)。
6.3. 百度百科
本节评估 DAKSE 在中文百度百科上的效果。与中国移动的客户服务相比,百科领域更为宽泛。实验使用该语料库来展示 DAKSE 在更一般领域的有效性。
DKS概览:DAKSE 抽取共 1806239 个 DKS。表 7.4 列出了前 5 个 DKS,用来对抽取结果提供一些直观的展示。实验发现 DAKSE 为百度百科领域提取出了有效的 DKS。

▲ 表 7.4:百度百科前 5 的 DKS
实验结果的有效性:类似于中国移动客户服务中的度量方法,假设种子 DKS 是正确的。评估结果展示在表 7.5 中。表 7.6 中展示了手动标记的结果,该结果验证了本章方法的有效性。
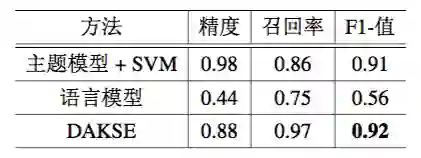
▲ 表 7.5:百度百科的评估结果
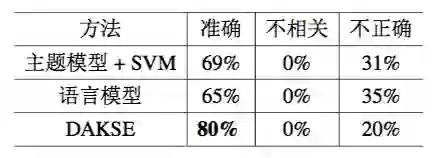
▲ 表 7.6:百度百科的人工标注结果
6.4. 特征贡献
DAKSE 将目标语句本身(Inner)和其上下文语句(Context)视为特征。 实验评估了这些特征在百度百科上做 DKS 分类的贡献,结果展示在图 7.3 中。这里 “Inner”指模型只使用目标句子作为特征。“Context”指模型只使用上下文作为特 征。“Inner+Context”是本章提出的模型。
这些模型的召回率几乎是一样的,然而通过添加上下文特征,精度有所提高。该结果验证了这两个特征的贡献。
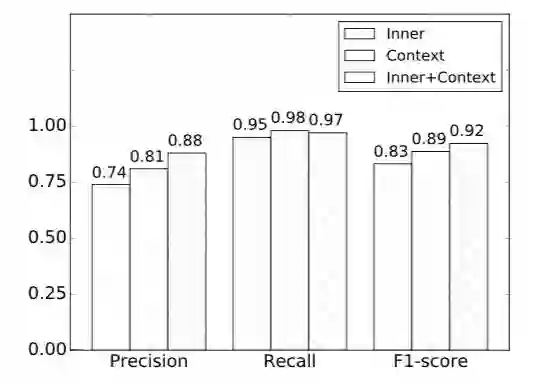
▲ 图 7.3:特征贡献
6.5. 应用:领域信息抽取
开放信息提取系统是从自然语言语料库提取所有结构化元组。因此,通过使用 DKS 作为语料库,可以实现特定领域的信息提取,所有提取的元组都属于该特定领域。
实验使用 Stanford Open IE 进行信息提取。由人手工来评估提取的元组是否正确。中国移动客户服务语料上抽取的元组精度为 74%。百度百科语料上抽取的元组精度为 62%。
为了给出提取的元组的直观描述,表格 7.7 展示了来自中国移动客户服务语料库的 DKS 的元组中频率前 10 的关系,并将结果与原始文本语料库中抽取出的关系进行比较。结果表明,根据 DKS 抽取出的元组中的关系更加清晰。这些关系直接指向用户的需求(例如 can visit link for)。相比之下,直接从原始语料库中抽取出的关系更模糊。

▲ 表 7.7:中国移动客服服务语料中的前 10 关系
提取的前几个 DKS 的元组展示在表 7.8 中。可以看出,这些元组具有很高的质量并且与相应的领域相关。这些元组将是构建特定领域结构化知识库的良好数据源。这也验证了 DAKSE 有益于领域信息提取。
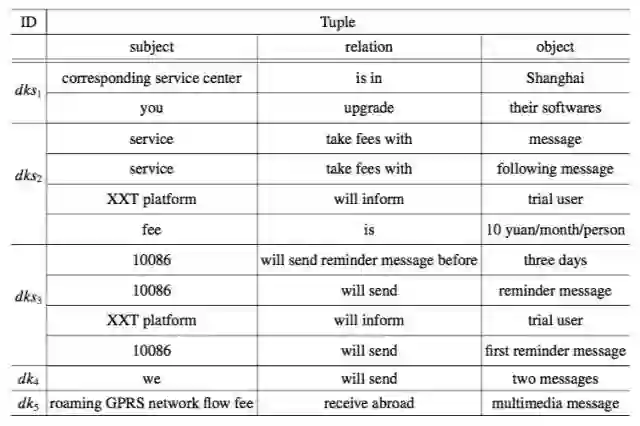
▲ 表 7.8:中国移动客服语料抽取出的信息
本章研究了针对特定领域的富含知识的句子提取的问题。在没有给定领域的预定义模式的情况下,本章利用领域 QA 语料库标记种子 DKS,构建了 DAKSE 系统,实现了文本语料库中的 DKS 的自动识别。
本章在两个不同的领域进行了充分的实验,结果验证 DAKSE 能够有效地识别 DKS。实验还将抽取出的结果应用于开放信息抽取技术上,提取出了特定领域的结构化的知识。
文末福利
在 PaperWeekly 微信公众号后台回复「完整论文」
即可获取作者完整版博士论文下载链接
关于PaperWeekly
PaperWeekly是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事AI领域,欢迎在公众号后台点击「交流群」,小助手将把你带入PaperWeekly的交流群里

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




