论文浅尝 | 常识用于回答生成式多跳问题

链接:https://arxiv.org/pdf/1809.06309.pdf
AnsweringTasks
多跳问题一般需要模型可以推理、聚合、同步上下文中不同的信息。就需要理解那些人类通过背景知识可以理解的限制关系。本文提出了一个很强的baseline模型(multi-attention + pointer-generator decoder);引入了一个评分函数评价从ConceptNet知识库中抽取多跳知识(pointwise mutual information + term-frequency );并有效的利用提取的常识信息填补上下文的推理中( selectivelygated attentionmechanism)。
介绍
Machine Reading Comprehension: MRC 长期以来一直是评估模型理解和推理语言能力的任务。
Commonsense/Background Knowledge: 将常识知识作为外部数据库中的关系三元组或特征添加。
Incorporation of External Knowledge: 尝试使用外部知识来提高任务模型性能。
模型
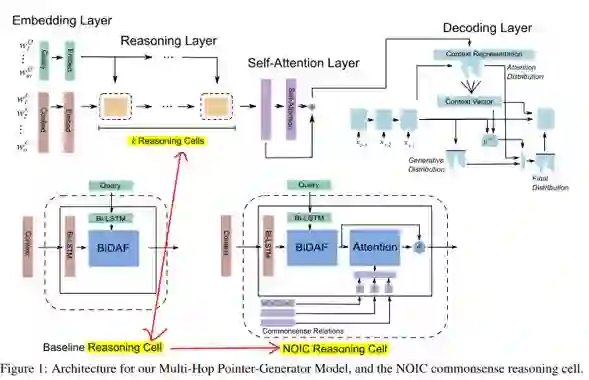
Embedding Layer: ELMo(Peters et al., 2018)).
Reasoning Layer: context embedding 通过k个 resoning cell 模拟一步推理。每一步都通过query的 BiDAF attention(Seo et al., 2017)更新 context representation。
Self-Attention Layer: self-attention (Cheng et al., 2016) 解决 long-term dependencies and co-reference within the context.
Pointer-Generator Decoding Layer: (See et al.,2017) 生成答案。
引入常识
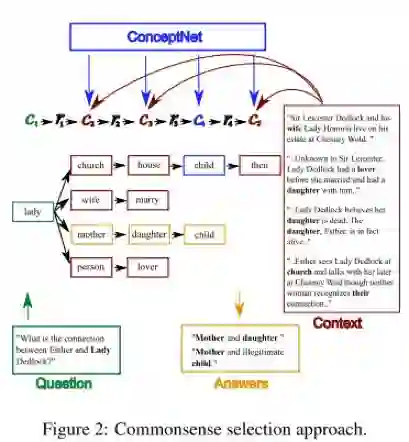
这部分是关键,主要分为两步:
a. 在常识知识库中找出多跳动候选路径, 形成树结构.
· C1是问句中的常识词.
· C2是C1通过一跳可以达到而且出现在 context 中. [Direct]
· C3是C2通过一跳可以到达而且出现在 context 中. [Multi-Hop]
· C4是C3的邻居,不必出现在 context. [OutsideKnowledge 获取更多信息]
· C5是C4的邻居,需要出现在 context中. [Context-Grounding. 确保信息有用]
b. 给候选路径打分筛选
· 节点初始分
1. C1\C2\C3重要的概念总是经常在上下文中出现,利用术语在上下文中的频率近似它概念的重要性.

|C|是上下文的长度\\count(c)是单词c出现的次数。
2. C4 不在上下文中,但在启发式的方法下,重要的概念经常在不同的路径里重复出现。
利用 Pointwise Mutual Information (PMI):
PMI(c4, c1−3) = log( P (c4, c1−3)/ P (c4) P(c1−3))


3. 不同分支、不同层级的节点不存在竞争,所以最后可以求一个标准化:
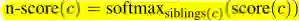
· 节点累计分
因为添加的常识信息包括多跳,所以计算评分的时候不止需要当前节点的得分,还要考虑其树的后代。
自底向上计算:其中f是这个节点得分最高的两个子节点平均得分。
c-score(cl) =n-score(cl) + f(cl)
· 路径选择
· 自顶向下选择每个节点得分最高的两个。最多有2^4=16条路径。
实验
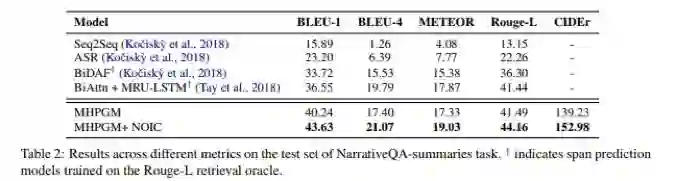
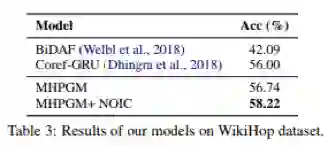
本文中在generative NarrativeQA (Kocisk ˇ y` et al., 2018) (summary subtask) 和 extractive QAngaroo WikiHop 这两个数据集上进行了实验,实验结果显示本文机制能够较大的提高模型的性能。
论文笔记整理:张晶尧,东南大学硕士生,研究方向为问答系统中复杂问题理解。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



