Combine SAC with RNN (part1)
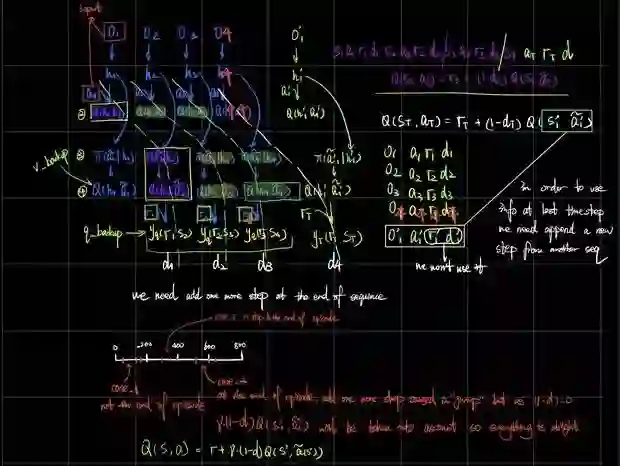
With the combination of sac and rnn. we can solve POMDP problem theoretically, but in practice, we face a lot problem.
One of the most important problem is what kind of structure should we use? There are batch of valid choice, for example we can use the full length episode to feed rnn, or we can use a fixed length.
With some investigate in this area, we choose a fixed length rnn. Another crutial problem is how to deal with different length of episodes. Me choice is discard any invalid sequence.
We will release more implement details, stay tuned.

class ReplayBuffer:"""A simple FIFO experience replay buffer for SAC agents."""def __init__(self, obs_dim, act_dim, size, h_size, seq_length, flag="single"):self.flag = flagself.sequence_length = seq_lengthself.ptr, self.size, self.max_size = 0, 0, sizeself.obs_dim = obs_dimsize += seq_length # in case index is out of rangeself.obs1_buf = np.zeros([size, obs_dim], dtype=np.float32)self.hidden_buf = np.zeros([size, h_size], dtype=np.float32)self.acts_buf = np.zeros([size, act_dim], dtype=np.float32)self.rews_buf = np.zeros([size, 1], dtype=np.float32)self.done_buf = np.zeros([size, 1], dtype=np.float32)self.target_done_ratio = 0def store(self, obs, s_t_0, act, rew, done):self.obs1_buf[self.ptr] = obsself.hidden_buf[self.ptr] = s_t_0self.acts_buf[self.ptr] = actself.rews_buf[self.ptr] = rewself.done_buf[self.ptr] = doneself.ptr = (self.ptr + 1) % self.max_size # 1%20=1 2%20=2 21%20=1self.size = min(self.size + 1, self.max_size) # use self.size to control sample rangeself.target_done_ratio = np.sum(self.done_buf) / self.sizedef sample_batch(self, batch_size=32):""":param batch_size::return: s a r s' d"""idxs_c = np.empty([batch_size, self.sequence_length]) # N T+1for i in range(batch_size):end = Falsewhile not end:ind = np.random.randint(0, self.size - 5) # random sample a starting point in current bufferidxs = np.arange(ind, ind + self.sequence_length) # extend seq from starting pointis_valid_pos = True if sum(self.done_buf[idxs]) == 0 else (self.sequence_length -np.where(self.done_buf[idxs] == 1)[0][0]) == 2end = True if is_valid_pos else Falseidxs_c[i] = idxsnp.random.shuffle(idxs_c)idxs = idxs_c.astype(int)# print(self.target_done_ratio, np.sum(self.done_buf[idxs]) / batch_size)data = dict(obs1=self.obs1_buf[idxs],s_t_0=self.hidden_buf[idxs][:, 0, :], # slide N T H to N Hacts=self.acts_buf[idxs],rews=self.rews_buf[idxs],done=self.done_buf[idxs])return data
登录查看更多
相关内容

SAC:Selected Areas in Cryptography。
Explanation:密码术的选择区。
Publisher:Springer。
SIT:http://dblp.uni-trier.de/db/conf/sacrypt/
Arxiv
6+阅读 · 2018年4月7日
Arxiv
8+阅读 · 2017年11月22日





相关VIP内容
相关资讯