[机器学习] 用KNN识别MNIST手写字符实战

Hi, 好久不见,粉丝涨了不少,我要再不更新,估计要掉粉了,今天有时间把最近做的一些工作做个总结,我用KNN来识别MNIST手写字符,主要是代码部分,全部纯手写,没有借助机器学习的框架,希望对大家理解KNN有帮助。
https://github.com/Alvin2580du/KNN_mnist
-------------------------------------------------
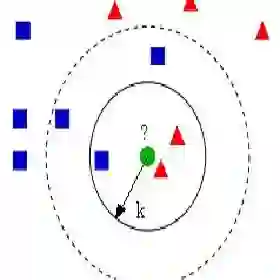
首先介绍一些KNN的原理,KNN也叫K近邻分类算法,说到底它也是用来做分类任务的,所以我们只要明白它分类的依据是什么就差不多了。换句话说,给定一个样本,他是怎么(原理)把这个样本分到第一类还是第二类的,以此类推。K近邻里面的K是一个可调的参数,一般取正整数,比如K=3,4,5,6,...。我们举个栗子,比如当K=10的时候,即选择距离待分类样本距离最近的10个样本,这10个样本里面有3个第一类,7个第二类,那么就把这个待分类样本划分到第二类。是不是很简单?
然后介绍下数据,MNIST数据集是一个比较著名的数据了,做机器学习的应该都知道,只是我们今天用的数据稍微有点特殊,他是把MNIST数据集图像二值化以后得到的,即黑色的地方取0,白色的地方取1。原始数据是训练集,测试集,和预测集在三个文件中,首先把这三个数据集拆开,每个样本独立一个文件中,这样做的目的是为了便于后续的读取,其应该不分开也可以做,只是这样看起来更清楚一点吧。
import os
import math
from functools import reduce
import numpy as np
from collections import Counter
import pandas as pd
from datetime import datetime
def applyfuns(inputs):
if len(inputs) > 10:
return "data"
else:
return inputs.strip()
def split_datasets(filename="./datasets/knn/digit-training.txt"):
# 将原始数据分拆开,一个样本保存到一个文件中
dir_name = filename.split("/")[-1].split(".")[0].split("-")[1]
save_path = './datasets/knn/{}'.format(dir_name)
if not os.path.exists(save_path):
os.makedirs(save_path)
data = pd.read_csv(filename, header=None)
datacopy = data.copy()
datacopy['labels'] = data[0].apply(applyfuns)
label = datacopy[~datacopy['labels'].isin(['data'])]
label.columns = ['0', '1']
train = datacopy[datacopy['labels'].isin(['data'])][0]
k = 0
index = 0
limit = 32
save = []
for y in train:
save.append(y)
k += 1
if k >= limit:
df = pd.DataFrame(save)
df.to_csv("./datasets/knn/{}/{}_{}.txt".
format(dir_name, index, label['1'].values[index]),
index=None,
header=None)
save = []
k = 0
index += 1
就得到了下面这样的数据,我截图示例:

这样一个数据就代表了一个样本,然后训练集我们有942个,测试集有195个,最后留下8个样本用来预测。下面使我们的数据的目录结构。

下面直接开始上代码
首先我们需要有一个方法,来实现对一个样本数据变成一个矩阵向量,即
def img2vectorV1(filename):
# get data
rows = 32
cols = 32
imgVector = []
fileIn = open(filename)
for row in range(rows):
lineStr = fileIn.readline()
for col in range(cols):
imgVector.append(int(lineStr[col]))
return imgVector
首先打开文件,按行去读取,然后遍历每一行,并把字符型转换为整型。
def vector_subtract(v, w):
# 向量相减
return [v_i - w_i for v_i, w_i in zip(v, w)]
def distance(v, w):
# 计算距离函数
s = vector_subtract(v, w)
return math.sqrt(sum_of_squares(s))
def get_dict_min(lis, k):
# 找到距离最近的k个样本,然后找到出现次数最多的那一类样本
gifts = lis[:k]
save = []
for g in gifts:
res = g[1]
save.append(res)
return Counter(save).most_common(1)[0][0]
def knnclassifiy(k=3):
# 用来统计训练集中没类样本总数
k0, k1, k2, k3, k4, k5, k6, k7, k8, k9 = 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
hwLabels = []
trainingFileList = os.listdir(dataSetDir + "training") # load training data
m = len(trainingFileList)
trainingMat = np.zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('.')[0].split("_")[1])
if classNumStr == 0:
k0 += 1
elif classNumStr == 1:
k1 += 1
elif classNumStr == 2:
k2 += 1
elif classNumStr == 3:
k3 += 1
elif classNumStr == 4:
k4 += 1
elif classNumStr == 5:
k5 += 1
elif classNumStr == 6:
k6 += 1
elif classNumStr == 7:
k7 += 1
elif classNumStr == 8:
k8 += 1
else: # 9
k9 += 1
hwLabels.append(classNumStr)
trainingMat[i, :] = img2vectorV1(dataSetDir + 'training/%s' % fileNameStr)
testFileList = os.listdir(dataSetDir + 'testing')
# 用来统计测试集的样本总数
tkp0, tkp1, tkp2, tkp3, tkp4, tkp5, tkp6, tkp7, tkp8, tkp9 = 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
# 用来统计分类正确的样本数
tk0, tk1, tk2, tk3, tk4, tk5, tk6, tk7, tk8, tk9 = 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
C = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
TestclassNumStr = int(fileStr.split('.')[0].split("_")[1])
if TestclassNumStr == 0:
tkp0 += 1
elif TestclassNumStr == 1:
tkp1 += 1
elif TestclassNumStr == 2:
tkp2 += 1
elif TestclassNumStr == 3:
tkp3 += 1
elif TestclassNumStr == 4:
tkp4 += 1
elif TestclassNumStr == 5:
tkp5 += 1
elif TestclassNumStr == 6:
tkp6 += 1
elif TestclassNumStr == 7:
tkp7 += 1
elif TestclassNumStr == 8:
tkp8 += 1
else: # 9
tkp9 += 1
data_file_name = dataSetDir + 'testing/%s' % fileNameStr
vectorUnderTest = img2vectorV1(data_file_name)
distaces_list = {}
for j in range(m):
distaces = distance(vectorUnderTest, trainingMat[j]) # 计算距离
distaces_list[distaces] = hwLabels[j]
sorted_distance_list = sorted(distaces_list.items(),
key=lambda e: e[0],
reverse=False)
# 对距离进行排序
gifts = get_dict_min(sorted_distance_list, k)
# 获得距离最近的K个样本中,出现次数最多的那个样本
if TestclassNumStr == gifts:
C += 1
if gifts == 0:
tk0 += 1
elif gifts == 1:
tk1 += 1
elif gifts == 2:
tk2 += 1
elif gifts == 3:
tk3 += 1
elif gifts == 4:
tk4 += 1
elif gifts == 5:
tk5 += 1
elif gifts == 6:
tk6 += 1
elif gifts == 7:
tk7 += 1
elif gifts == 8:
tk8 += 1
else: # 9
tk9 += 1
print("- " * 20)
print(' Training info ')
print(" {} = {}".format("0", k0))
print(" {} = {} ".format("1", k1))
print(" {} = {} ".format("2", k2))
print(" {} = {} ".format("3", k3))
print(" {} = {} ".format("4", k4))
print(" {} = {} ".format("5", k5))
print(" {} = {} ".format("6", k6))
print(" {} = {} ".format("7", k7))
print(" {} = {} ".format("8", k8))
print(" {} = {} ".format("9", k9))
print("- " * 20)
print(" Total Sample = {} ".format(m))
print()
print("- " * 20)
print(' Testing info ')
print("- " * 20)
print(" {} = {}, {}, {:0.2f}% ".
format("0", tkp0, abs(tkp0 - tk0), 1-abs(tkp0 - tk0)/tkp0))
print(" {} = {}, {}, {:0.2f}% ".
format("1", tkp1, abs(tkp1 - tk1), 1-abs(tkp1 - tk1)/tkp1))
print(" {} = {}, {}, {:0.2f}% ".
format("2", tkp2, abs(tkp2 - tk2), 1-abs(tkp2 - tk2)/tkp2))
print(" {} = {}, {}, {:0.2f}% ".
format("3", tkp3, abs(tkp3 - tk3), 1-abs(tkp3 - tk3)/tkp3))
print(" {} = {}, {}, {:0.2f}% ".
format("4", tkp4, abs(tkp4 - tk4), 1-abs(tkp4 - tk4)/tkp4))
print(" {} = {}, {}, {:0.2f}% ".
format("5", tkp5, abs(tkp5 - tk5), 1-abs(tkp5 - tk5)/tkp5))
print(" {} = {}, {}, {:0.2f}% ".
format("6", tkp6, abs(tkp6 - tk6), 1-abs(tkp6 - tk6)/tkp6))
print(" {} = {}, {}, {:0.2f}% ".
format("7", tkp7, abs(tkp7 - tk7), 1-abs(tkp7 - tk7)/tkp7))
print(" {} = {}, {}, {:0.2f}% ".
format("8", tkp8, abs(tkp8 - tk8), 1-abs(tkp8 - tk8)/tkp8))
print(" {} = {}, {}, {:0.2f}% ".
format("9", tkp9, abs(tkp9 - tk9), 1-abs(tkp9 - tk9)/tkp9))
print("- " * 20)
print(" Accuracy = {:0.2f}%".format(C / float(mTest)))
print("Correct/Total = {}/{}".format(int(C), mTest))
print(" End of Training @ {} ".
format(datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
def build_knnclassifier():
# 这里对不同的k进行分类,找到最合适的K。
ks = [3, 5, 7, 9]
for k in ks:
print(" Beginning of Training @ {} ".
format(datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
knnclassifiy(k)
print()
最后是根据上一步训练找到最合适的K,然后进行预测。
def buildPredict(k=7):
hwLabels = []
trainingFileList = os.listdir(dataSetDir + "training") # 加载测试数据
m = len(trainingFileList)
trainingMat = np.zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('.')[0].split("_")[1]) # return 1
hwLabels.append(classNumStr)
trainingMat[i, :] = img2vectorV1(dataSetDir + 'training/%s' % fileNameStr)
predictFileList = os.listdir(dataSetDir + 'predict') # load the testing set
mTest = len(predictFileList)
for i in range(mTest):
fileNameStr = predictFileList[i]
data_file_name = dataSetDir + 'predict/%s' % fileNameStr
vectorUnderTest = img2vectorV1(data_file_name)
distaces_list = {}
for j in range(m):
distaces = distance(vectorUnderTest, trainingMat[j])
distaces_list[distaces] = hwLabels[j]
sorted_distance_list = sorted(distaces_list.items(),
key=lambda e: e[0],
reverse=False)
gifts = get_dict_min(sorted_distance_list, k)
print(gifts)
最后执行 上面的代码, 这里只要修改 method 的值,执行下面的对应的方法就可以了。
if __name__ == '__main__':
method = 'build_knnclassifier'
if method == 'split_datasets':
dataname = ['./datasets/knn/digit-training.txt', './datasets/knn/digit-testing.txt',
'./datasets/knn/digit-predict.txt']
for n in dataname:
split_datasets(n)
if method == 'build_knnclassifier':
build_knnclassifier()
if method == 'buildPredict':
buildPredict(k=7)
下面是我得到的实验结果,准确率达到了95%,这个准确率其实也不算高 。
TRAINING
Beginning of Training @ 2018-05-06 23:08:16
- - - - - - - - - - - - - - - - - - - -
Training info
0 = 100
1 = 94
2 = 93
3 = 105
4 = 87
5 = 81
6 = 95
7 = 90
8 = 109
9 = 89
- - - - - - - - - - - - - - - - - - - -
Total Sample = 943
- - - - - - - - - - - - - - - - - - - -
TESTING
- - - - - - - - - - - - - - - - - - - -
Testing info
- - - - - - - - - - - - - - - - - - - -
0 = 20, 1, 0.95%
1 = 20, 2, 0.90%
2 = 25, 0, 1.00%
3 = 18, 1, 0.94%
4 = 25, 2, 0.92%
5 = 16, 0, 1.00%
6 = 16, 1, 0.94%
7 = 19, 0, 1.00%
8 = 17, 1, 0.94%
9 = 20, 2, 0.90%
- - - - - - - - - - - - - - - - - - - -
Accuracy = 0.95%
Correct/Total = 187.0/196
Endof Training @ 2018-05-06 23:09:48
TRAINING
Beginning of Training @ 2018-05-06 23:09:48
- - - - - - - - - - - - - - - - - - - -
Training info
0 = 100
1 = 94
2 = 93
3 = 105
4 = 87
5 = 81
6 = 95
7 = 90
8 = 109
9 = 89
- - - - - - - - - - - - - - - - - - - -
Total Sample = 943
- - - - - - - - - - - - - - - - - - - -
TESTING
- - - - - - - - - - - - - - - - - - - -
Testing info
- - - - - - - - - - - - - - - - - - - -
0 = 20, 1, 0.95%
1 = 20, 4, 0.80%
2 = 25, 0, 1.00%
3 = 18, 1, 0.94%
4 = 25, 5, 0.80%
5 = 16, 0, 1.00%
6 = 16, 1, 0.94%
7 = 19, 0, 1.00%
8 = 17, 3, 0.82%
9 = 20, 5, 0.75%
- - - - - - - - - - - - - - - - - - - -
Accuracy = 0.94%
Correct/Total = 185.0/196
Endof Training @ 2018-05-06 23:11:20
TRAINING
Beginning of Training @ 2018-05-06 23:11:20
- - - - - - - - - - - - - - - - - - - -
Training info
0 = 100
1 = 94
2 = 93
3 = 105
4 = 87
5 = 81
6 = 95
7 = 90
8 = 109
9 = 89
- - - - - - - - - - - - - - - - - - - -
Total Sample = 943
- - - - - - - - - - - - - - - - - - - -
TESTING
- - - - - - - - - - - - - - - - - - - -
Testing info
- - - - - - - - - - - - - - - - - - - -
0 = 20, 1, 0.95%
1 = 20, 4, 0.80%
2 = 25, 0, 1.00%
3 = 18, 0, 1.00%
4 = 25, 4, 0.84%
5 = 16, 0, 1.00%
6 = 16, 1, 0.94%
7 = 19, 0, 1.00%
8 = 17, 3, 0.82%
9 = 20, 3, 0.85%
- - - - - - - - - - - - - - - - - - - -
Accuracy = 0.95%
Correct/Total = 187.0/196
Endof Training @ 2018-05-06 23:12:45
TRAINING
Beginning of Training @ 2018-05-06 23:12:45
- - - - - - - - - - - - - - - - - - - -
Training info
0 = 100
1 = 94
2 = 93
3 = 105
4 = 87
5 = 81
6 = 95
7 = 90
8 = 109
9 = 89
- - - - - - - - - - - - - - - - - - - -
Total Sample = 943
TESTING
- - - - - - - - - - - - - - - - - - - -
Testing info
- - - - - - - - - - - - - - - - - - - -
0 = 20, 1, 0.95%
1 = 20, 4, 0.80%
2 = 25, 0, 1.00%
3 = 18, 0, 1.00%
4 = 25, 4, 0.84%
5 = 16, 0, 1.00%
6 = 16, 1, 0.94%
7 = 19, 0, 1.00%
8 = 17, 3, 0.82%
9 = 20, 3, 0.85%
- - - - - - - - - - - - - - - - - - - -
Accuracy = 0.94%
Correct/Total = 185.0/196
Endof Training @ 2018-05-06 23:14:10
PREDICTION
5
2
1
8
2
9
9
5