干货 | 自从学了这个方法,深度学习再也不愁没钱买数据集了

深度学习大牛吴恩达曾经说过:做AI研究就像造宇宙飞船,除了充足的燃料之外,强劲的引擎也是必不可少的。假如燃料不足,则飞船就无法进入预定轨道。而引擎不够强劲,飞船甚至不能升空。类比于AI,深度学习模型就好像引擎,海量的训练数据就好像燃料,这两者对于AI而言同样缺一不可。
在深度学习中,当数据量不大时可能会导致过拟合,使得训练误差很小,但测试误差却特别大。怎么办呢,你又没钱买数据?显然最好的办法(之一)就是自己“造”数据——人工增加训练集的大小,也就是Data Augmentation Transformation。
不同的任务背景下,通常我们可以通过图像的几何变换,使用例如剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。例如假如你的数据集只有10张256*256的图片,那么通过剪切你可以在每张图片上得到32*32=1024张224*224的图片,然后再做一次水平翻转,那么你的数据集就扩大了2048倍,也就是说你现在有了一个20480张图片的数据集。看起来很诱人。那么它的效果如何呢?
AI科技评论注: 几何变换不改变像素值, 而是改变像素所在的位置. 通过Data Augmentation方法扩张了数据集的范围, 作为输入时, 以期待网络学习到更多的图像不变性特征。
近期加拿大多伦多大学的Salehinejad等人在论文(arXiv:1708.04347v1)中提出了另外一种不同于上面几种的数据增强变换——极坐标变换,方法极为简单,完全可以作为数据增强变换一个案例来介绍。
方 法
所谓极坐标变换,就是像素由原来(x, y)的表示通过极坐标变换得到(r, θ)的表示,然后把它表示成一个二维图片。数学知识只涉及这两个高中的数学公式:


用图来表示就是:

例如在一张256*256的图片上,选择圆心任意、半径为256且等分为256条像素辐条(角度变化为2*pi/256)的圆盘来覆盖图片,那么覆盖到像素都将对应一个(r, θ)对,放到二维直角坐标系中就生成了一幅新图。由于极坐标在靠近圆心位置像素粒度较大,而远离圆心位置的像素粒度较小,所以改变圆心位置,将得到不同的图片。

实 验
作者选择了两个数据集来进行试验。其中一个是MNIST数据集,共10个类,每个类分别为0-9的手写体数字。(RT为极坐标变换后的对应图片)

另一个是多模医学影像数据集(Multimodal medical dataset),作者共选了9个类。
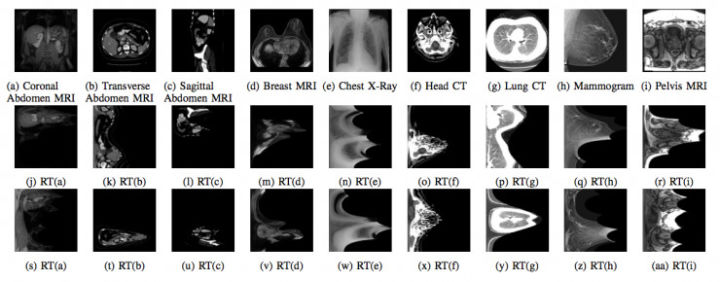
在实验中作者每个类只有20张图片。也即在数据增强变换之前(original)MNIST-OR数据集有200张图片,MMD-OR有180张图片。作者通过极坐标变换把数据增大了100倍,MNIST-RT有20000张图片,MMD-RT有18000张图片。
随后作者分别选用AlexNet和GoogLeNet两个深度学习模型对以上四个数据集进行训练,其结果则非常喜人。
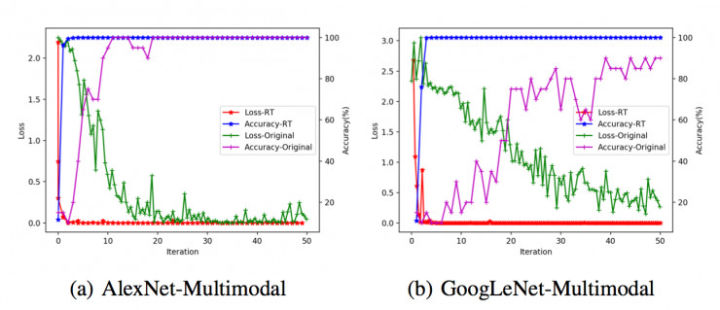

结 果
对比有四:
1、在数据量较小时,AlexNet的表现要比GoogLeNet好;
2、通过数据增强变换后的数据集能够更迅速地收敛,且精度较高;
3、通过数据增强变换后的数据集收敛时涨落较小。
4、对比MNIST数据和多模医学影像数据集,MNIST的两个数据集(OR和RT)精度之间的差别更明显。这可能是因为多模医学影像数据集的图像之间有关联,例如横向腹部磁共振成像和矢状面腹部磁共振成像之间有一定的关联性。
很明显喽,极坐标变换的数据增强变换方式也是很有效的。所以吧,没钱买数据了,不妨试试各种数据增强的变换方法,也可以将各种变换组合使用,那你的数据量将成n次方地增加。
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————




