评测任务实战:中文文本分类技术实践与分享 - PaperWeekly 第49期
作者丨陆晨昱
单位丨义语智能科技(上海)有限公司
联系方式丨chenyu@deepbrain.ai
1. 引言
随着人工智能的大热,人机对话技术也受到了各界广泛的关注。在第六届全国社会媒体处理大会(SMP 2017)上,专委会举办了一场中文人机对话技术评测(ECDT)。评测包含两个任务,任务一为用户意图领域分类;任务二为特定域任务型人机对话在线评测。笔者代表我司参加了其中的任务一:意图分类。该任务的内容是根据用户请求的文本(通常为一个句子的长度)进行意图的分类,因而笔者就将其理解为文本分类了。
在整个人机对话系统中,意图分类是非常重要的一环,其性能好坏直接影响后续功能模块的执行,进而影响整个系统的表现。传统的文本分类算法很大程度上依赖于精心挑选的特征和设置的规则,依靠人为加入的对某一特定语言的先验知识来实现分类。
随着深度学习的兴起,各种基于深度神经网络的分类模型在图像、语音等领域都取得了令人瞩目的成绩。近年来,深度学习也被广泛应用于自然语言处理领域,文本分类便是其中一个热门课题。
文本分类是一个典型的序列分类问题。根据给定的字符序列,我们需要输出其对应的类别标签。常见的用于文本分类的深度学习模型有卷积神经网络、循环神经网络、注意力机制等。由于深度学习最大程度上简化了特征工程和预处理,模型结构与训练方法的选择是影响结果好坏的重要因素。
在本次测评中,我司基于深度学习的文本分类模型在封闭与开放测试中均取得了第二名的成绩[1]。这里说句题外话,本来任务一设置开放与封闭测试两个子任务的初衷是允许参赛方在开放测试中可以使用额外的标注数据来训练模型。奈何我司人手不足,获取标注数据一事只好作罢。最终我司提交开放与封闭测试的是同一个模型,都只使用了封闭测试的标注数据。细心的读者可能会发现,我司在开放与封闭测试中的成绩是相同的。
言归正传,下面笔者就与大家分享在此次评测中收获的一些实践心得。
2. 模型结构
卷积神经网络[2]在序列分类任务中有着出色的表现。针对本次评测中意图分类任务的特点,模型无需具有长跨度的记忆能力。同时,相比循环神经网络,卷积神经网络有着更好的并行性能。因此在该任务中卷积网络是一个合理的选择。
由于自然语言处理中的输入是离散且稀疏的,建模能力较强的模型在文本分类任务上很容易发生过拟合。所以通常我们在模型的选取上偏向小而简单的模型,例如较少层数的卷积网络,甚至是一个简单的线性分类器往往反而效果更好。在实践过程中笔者发现,在文本分类任务上,简单的增加网络层数反而会引起模型的性能下降。
为了解决这个问题,使得在文本分类任务上应用更深更复杂的卷积网络成为可能,笔者进一步尝试了残差网络[3]。残差卷积网络的思想是通过在模块的输入输出之间引入跳跃连接,来让中间的卷积层学习一个残差函数。经过实验后发现,残差网络的加入确实能给多层卷积网络模型的效果带来显著的改善。
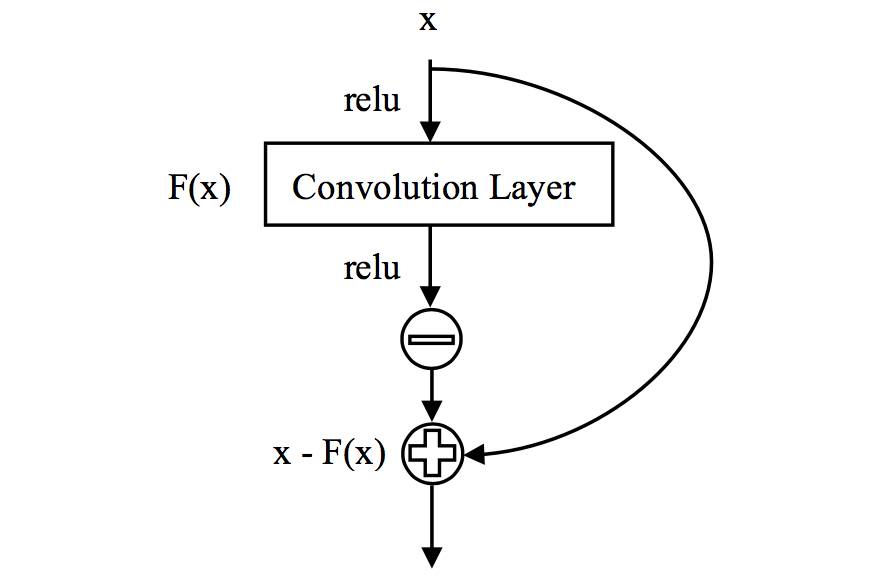
△ Figure 1:自抑制残差卷积模块结构
那么,有没有比传统的残差网络模块更优的结构呢?带着这个问题,笔者实验了不同结构的残差模块,提出了如图1所示的自抑制残差卷积模块(Self-Inhibiting Residual Convolution Block)。
与一般残差模块不同的是,我们将卷积操作的输出通过修正线性单元(relu)激活函数,然后取其负值与该模块的输入相加。由于 relu 函数非负的特性,在经过这样一个模块的处理后,输出相对输入是“被抑制”的。实验结果表明,该自抑制残差卷积模块相比传统的残差模块有更强的泛化能力,效果更好。
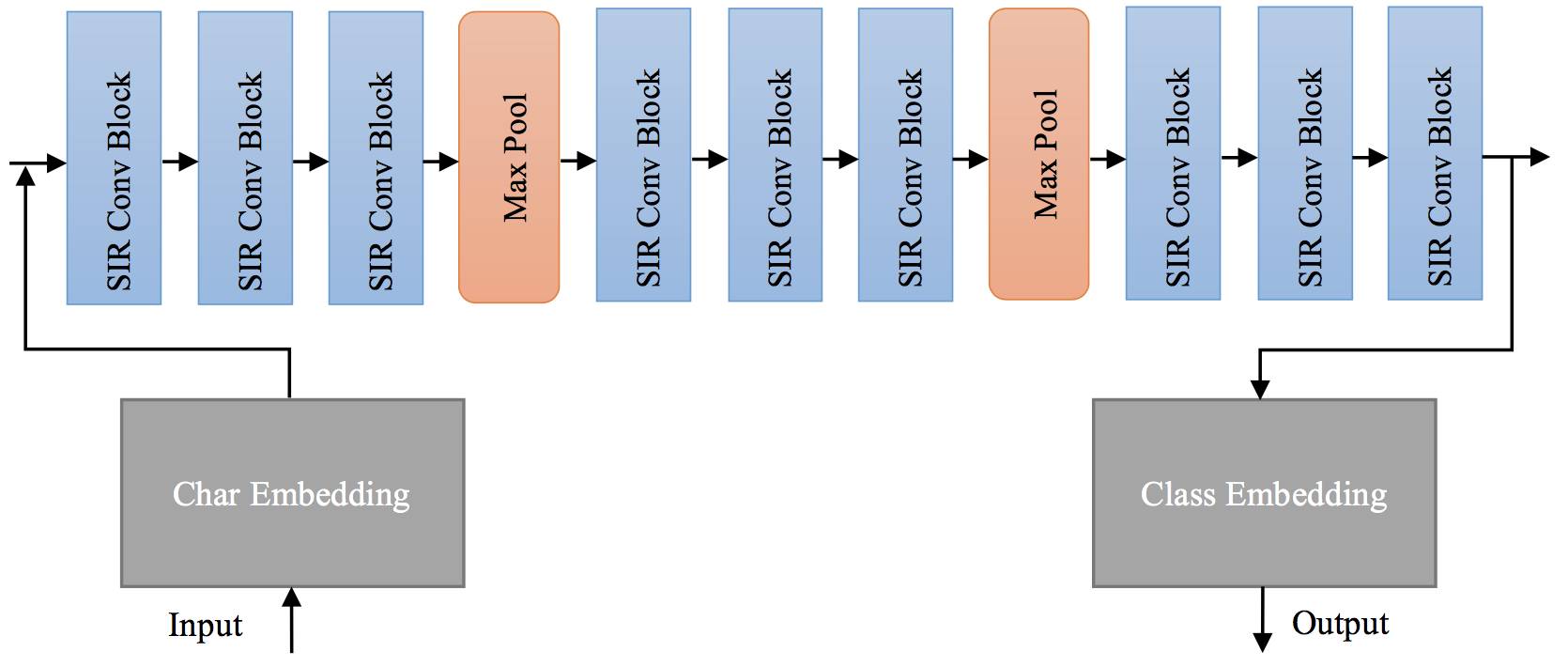
△ Figure 2:文本分类模型结构
最终的模型结构如图2所示,整个文本分类模型由多个串联的自抑制残差卷积模块与最大池化层交替构成。
其中,卷积与最大池化均为一维操作,作用于输入序列的“时间”轴上。在整个模型中,卷积核的大小统一为 3,最大池化的窗长统一为 2。模型的隐层大小与字嵌入、类嵌入维数均为 512。另外,残差网络要求模块的输入与输出大小匹配,因此在卷积与最大池化操作中,我们用 0 值填充输入序列的两端,使得这两种操作的输出与输入有相同的形状。
3. 训练流程
字向量预训练
与传统方法不同的是,基于深度学习的文本分类模型是数据驱动的。给定训练样本及标签,模型会学习到对分类任务有用的特征及规则。由于整个模型的参数是随机初始化的,且我们没有人为的引入任何语言的先验知识,在数据较少的情况下训练得到的模型可能泛化能力不足。
我们的模型中采用字作为输入单元,因此为了让模型对输入的字有一个初步的“认识”,可以采用无监督训练的方式对字向量做预训练。笔者采用的方法是用无标签的短文本语料训练一个变分自编码器[4],而后取其中的字嵌入矩阵作为分类模型中字向量的初始值。当然,在后续的有监督训练中,经过预训练的字向量同分类模型中的其它随机初始化的参数一样进行更新迭代,进一步调优。
具体而言,在预训练阶段,我们准备了 6 亿量级的无标签短文本语料,构建了一个变分自编码器,将输入文本映射到连续的语义空间后,再用一个生成器重现原句子。同时,我们用一个标准的高斯分布作为先验来约束句子的语义表征。训练后的模型可用来采样生成短句子。当然,我们需要的只是这个模型中训练得到的字嵌入矩阵。
数据预处理
接下来是文本分类训练数据的预处理。由于我们采用字作为输入单元,因而无需对文本做分词。在预处理中,笔者仅做了去除标点符号这一操作。加入这一步骤的原因有二:其一是对数据进行检视后,我们认为标点符号并不包含对文本分类有用的信息;另外,我们用于预训练的无标签文本是不包含标点符号的,因此预训练得到的字向量中也不包含标点符号。
交叉熵训练
准备好训练数据后,我们采用传统的监督学习方式训练文本分类模型。训练的损失函数为输出分布与真实标签的交叉熵。训练中,笔者使用 adam 优化器[5]来做迭代优化,这也是当前主流的一个优化器。参数方面,学习率设定为 0.001,批(batch)大小设为 64,训练时长固定为 500 步。同时,为了减少训练时间,我们对不同长度的训练文本做了分组(bucketing)。
考虑到训练集中各类别样本的数量可能存在不均衡的情况,笔者在训练中调整了采样的策略:首先将不同类别标签的样本分组,采样时先随机挑选类别组,再从选中的类别组中选出一条样本。这样做可以保证最终每个批中不同类别的样本出现的概率是均等的。
集成学习
实验中,笔者进行了多次重复的训练过程,得到的模型在测试中的表现有小幅浮动。进一步检视模型分类错误的句子,笔者发现每个模型在出错的句子上不尽相同。为了进一步提升模型的性能,我们引入了集成学习[6]。在集成学习中,我们综合多个模型的决策来生成最终的结果。该方法可以避免单个模型的不足,显著提升整个系统的鲁棒性。
我们采用的是同构集成。训练中,我们构建了 32 个相同结构的分类模型并随机初始化以不同的参数。所有模型的字向量则统一加载由预训练得到的字嵌入矩阵。训练中的每一步我们都随机采样得到 32 个不同的批,分别输入不同模型进行并行训练。在测试阶段,我们将所有模型输出的概率分布的平均值作为最终的输出,并取其中的最大值所在类作为输出类别。
4. 结果分析
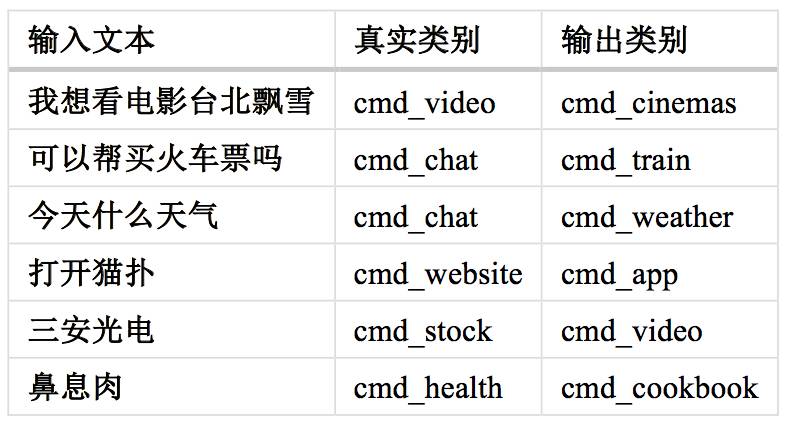
△ Table 1:模型分类错误的部分样本
通过对模型分类错误的句子的分析,我们可以提出一些可能带来改进的工作方向。由于评测中我们无法接触测试集,笔者用验证集作为测试集来测试模型。表1中列出了部分具有代表性的分类错误的样本。笔者粗略的将这些出错样本分为三类,并且认为这三类错误是在现有的解决方案框架下难以纠正的:
1) 其中像是“可以帮买火车票吗”、“今天什么天气”应该属于样本有误。结合训练数据与类别含义来看,模型输出的类别更准确一些。
2) “我想看电影台北飘雪”、“打开猫扑”这两个样本则是可能属于多个类别。如用户是想在线播放,则前一句应属于 cmd_video;若是想去电影院看,则应属于 cmd_cinemas。同理,猫扑可以是指网站,也可以是手机上的 app。在这种情况下,仅根据文本的信息无法做出可靠的正确分类。我们认为在实际产品中,需结合额外的场景信息或用户的上下文信息来做出判断。如信息缺失,则可以通过询问用户的方式来进一步确认。
3) 由于训练样本数量较少,而某些类别包含大量的领域相关词汇的,是给定的训练样本远远无法覆盖的。这种情况导致了模型无法分清“三安光电”是股票还是视频,错认为“鼻息肉”是某一种菜名。针对这类错误,提升训练样本的数量可能可以带来一些改善。我们认为更好的办法是引入领域相关知识,例如构建股票名与常见病症名的数据库来做检索等。
深度学习是一类强力的工具。然而在解决实际问题中,笔者认为仅依赖深度学习是远远不够的。基于对问题的深刻理解,将深度学习与传统方法、与业务、场景相结合,才能产出让用户满意的效果。
5. 参考文献
[1] http://ir.hit.edu.cn/SMP2017-ECDT-RANK
[2] X. Zhang, J. Zhao, and Y. LeCun, “Character-level Convolutional Networks for Text Classification,” 2015 Conference on Neural Information Processing Systems, pp. 3057–3061, 2015.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778, 2016.
[4] D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” arXiv:1312.6114, 2013.
[5] D. P. Kingma and J. L. Ba, “Adam: a Method for Stochastic Optimization,” 2015 International Conference on Learning Representations, pp. 1–15, 2015.
[6] L. K. Hansen and P. Salamon, “Neural Network Ensembles,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 12, no. 10, pp. 993–1001, 1990.
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。