SMP2018中文人机对话技术评测
声明:本文转载自公众号 DI数据智能,已经获得授权。
An Evaluation of Chinese Human-Computer Dialogue Technology
作者:赵正宇,张伟男,车万翔,陈志刚,张轶博
供稿:赵正宇
论文摘要
近些年来,人机对话技术作为人工智能领域的一个重要研究领域,受到了学术界和工业界的广泛关注。但是目前大型的中文人机对话评测仍十分欠缺。本文的重点聚焦于用户意图的识别和响应问题,以科大讯飞股份有限公司提供的数据集为基础,分别开展用户意图领域分类(任务一)和特定领域任务型人机对话在线评测(任务二)。本文介绍了评测任务以及评测数据集,并对评测结果和目前中文人机对话所存在的问题做出了简析。
评测介绍
在任务型人机对话系统中,有两个重要的研究方向。一个是聊天用户的意图领域分类,其目的在于区分用户的聊天意图,比如任务型垂类(订票、查询公交、查询电影信息等)、知识问答和闲聊等,是组成复杂人机对话系统的一个重要步骤。经过意图分类可以将用户输入交给相应的模块处理并返回合适的回复;另一个是特定域任务型人机对话,完善的人机对话系统应该具有理解用户要完成的任务并协助用户完成某项特定域任务的能力。
从以上两个研究方向出发,我们在第七届全国社会媒体处理大会(SMP2018)期间举办了第二届中文人机对话技术评测。本次评测分为两个任务:
1) 用户意图领域分类。包含闲聊和垂类两大类,其中垂类又细分为30个垂直领域,参赛系统需要判定用户的输入所属的类别。
2) 特定域任务型人机对话在线评测。参赛系统通过与测试人员实时在线对话完成相应的预定或查询任务,完成测试人员的特定域需求。
本次评测与SMP2017人机对话技术评测相比,有以下特点:
我们分别为两个任务加入了新的数据集,新加入的数据集都是由专业数据标注人员标注的,并且我们在测试集中加入了大量的干扰数据用于保证评测数据的隐蔽性。
本次评测任务一取消了封闭域的评测,只进行开放域评测,区别是用户不仅可以使用我们提供的训练数据,还可以自行收集数据。
我们在任务二的评价指标上做出了优化,更新了未完成任务对话轮数的计算方式,从而使统计出的平均对话轮数更加合理。
任务介绍
接下来将简要介绍两个评测任务。
任务一 用户意图领域分类
任务一具体描述如下:构建一个系统,使其能够尽可能正确地将用户输入分类到相应的闲聊类或任务垂类共计31个类别中。
示例如表1所示,

其中任务型垂类共30个类别。本次评测任务一仅考虑单轮对话,无需考虑多轮任务型对话的整体意图。另外,我们为参赛者们提供了一套系统搭建模板以便于统一接口。
对于任务一,我们根据精确率P、召回率R调和平均得到的F值对系统进行评价。其中对于精确率P和召回率R的计算,我们对31个类别构建混淆矩阵分别计算每个类别的P和R,对于所有类别计算平均值,最终取分数为,将此得分作为排名依据。
任务二 特定域任务型人机对话在线评测
任务二具体任务描述如下:对于一个查询并预定机票、火车票或酒店的一个意图或多个意图的混合任务,根据给定的数据库数据构建系统引导用户完成相应的任务。本次评测我们仍采用人工在线评测的方式,一个完整意图描述为:“预定明天从北京去上海的上午或者中午出发的机票”,其订机票过程如表2所示:
表2 定机票人机对话流程示例
U |
查询明天从北京去上海的机票 |
R |
请问您需要订票吗? |
U |
是的 |
R |
请问您要明天什么时候出发呢? |
U |
上午或中午吧 |
R |
帮您查询了明天从北京到上海的机票,没有上午出发的航班,中午12:10出发是否可以?7.3折,910元 |
U |
也行,就订这个吧 |
R |
已经帮您预订该航班机票,将跳转至付款页面 |
这里的“U”和“R”指的是用户与系统的回应。为了保证任务型对话系统各方面的主观和客观性能,本次评测采用了以下指标:
任务完成率:每一个测试对话看做是一个任务,测试过程中完成的任务数占任务总数的比率。
平均话轮数:完成一个任务所产生的对话句子(utterance)数,在完成任务的前提下越少越好。
用户满意度:评测员对系统的主观打分,包含5个取值{-2,-1,0,1,2}
回复流畅度:主观打分,包含3个取值{-1,0,1}
未覆盖数据引导能力:主观打分,包含2个取值{0,1}
数据集介绍
本次评测任务一的数据集来自科大讯飞股份有限公司,全部由专业数据标注人员手写生成。具体的数据集数据如表3所示:
表3 任务一数据集统计
训练集 |
开发集 |
测试集 |
|
数量 |
2299 |
770 |
1550 |
数据集的部分样例如表4所示,共有31个类别这样的人工手写的数据。与SMP2017评测数据集不同的是,本次评测只有开放型评测,用户可以自行收集各个类别的训练数据。

任务二的数据库数据仍来自科大讯飞股份有限公司,该数据集包括自系统日期起一个月的机票、火车票以及各地酒店信息,此外,我们人工写了若干个测试任务,包含订机票、订火车票、订宾馆三种简单意图任务或多意图任务。
详细数据集介绍及下载链接参见原文中的“EVALUATION OF DATA SETS”一节。
评测结果
在本节中,我们将会介绍两个任务参赛队伍评测结果,同时对结果进行分析,并对每个任务常见的问题作出总结。
任务一评测结果:
本次评测任务一我们共收到提交的系统21份,评测结果如图1所示。

图1 任务一评测结果
在提交的系统中,我们发现今年参赛系统前五名的平均F值(0.8079)要比去年(0.9268)低,经过我们分析,主要原因是今年的测试集是全新的,与发布的训练集和开发集不在同一分布,而去年的测试集是从训练集中抽出来的,所以今年综合的评分要比去年低很多。
任务二评测结果:
由于任务二比任务一难度大了很多,所以提交的队伍也相应较少,本次评测任务二共收到提交的系统10份,主要参考指标是任务完成率和平均话轮数,其中平均话轮数越小代表系统越好,在此任务中34.29为理论上的最大话论数,是任务完成率为0的情况下做出的最大惩罚。
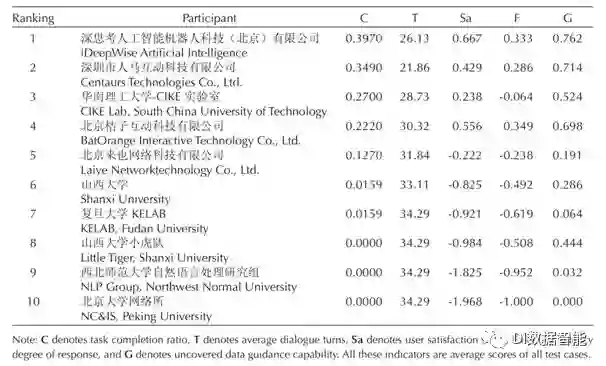
图2 任务二评测结果
图2中的结果是优先根据任务完成率指标,然后再考虑平均话轮数给出的综合排名,其中任务完成率C、用户满意度Sa、回复流畅度F和未覆盖数据应道能力G为人工完成标注,每个系统都有三位评测员针对21个特定任务进行评测打分,最终的任务完成率为三位评测员打分的均值。
总结
本文介绍了SMP2018中文人机对话技术评测,针对2017年首届人机对话评测中存在的问题进行了一些调整和改进。文章首先分别介绍了本次评测的任务一和任务二,并解释两个任务更新后的指标及其计算方法。此外,我们还简单介绍了两个任务的数据集。最后,我们给出了完整的评测结果并分析了本次评测中存在的问题。

赵正宇,哈尔滨工业大学计算机学院研究生。2018年毕业于哈尔滨工业大学,获学士学位。他的研究兴趣包括人机对话,省略恢复等。

张伟男博士,哈尔滨工业大学计算机学院副教授,中国中文信息学会信息检索专委会委员,青年工作委员会委员。他的研究方向包括开放域人机对话系统,自然语言处理和信息检索。

车万翔博士,哈尔滨工业大学计算机学院教授。他的主要研究领域是自然语言处理(NLP),承担了多个由国家自然科学基金和中国国家重点基础研究计划(973计划)资助的项目。

陈志刚博士,于2003年加入科大讯飞(iFLYTEK)公司,现任科大讯飞人工智能研究所副院长。他主要负责认知智能研究和产品化。

张轶博博士,于2004年获得北京邮电大学博士学位。他目前是华为消费者事业部智能工程部的首席科学家。在加入华为之前,他曾于2004年至2011年间在IBM中国研究实验室工作,2011年至2015年期间在诺亚方舟实验室工作,并于2015年至2018年间在微软亚洲搜索技术中心工作。他最近的重点领域包括意图理解,任务完成和对话管理。
本期责任编辑:张伟男
本期编辑:蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。