SMP2019中文人机对话技术评测(ECDT)报名开始啦
欢迎
欢迎来到SMP2019中文人机对话技术评测(The Evaluation of Chinese Human-Computer Dialogue Technology,SMP2019-ECDT)。
在本届SMP会议上,我们继续举办中文人机对话技术评测(ECDT)。近年来,人机对话技术受到了学术界和产业界的广泛关注。学术上,人机对话是人机交互最自然的方式之一,其发展影响及推动着语音识别与合成、自然语言理解、对话管理以及自然语言生成等研究的进展;产业上,众多产业界巨头相继推出了人机对话技术相关产品,如个人事务助理、虚拟情感陪护机器人、娱乐型聊天机器人等等,并将人机对话技术作为其公司的重点研发方向。以上极大地推动了人机对话技术在学术界和产业界的发展。
本届中文人机对话技术评测由中国中文信息学会社会媒体处理专委会主办,哈尔滨工业大学、科大讯飞股份有限公司、清华大学承办,华为公司提供奖金。旨在促进中文人机对话系统相关研究的发展,为人机对话技术相关的学术研究人员和产业界从业人员提供一个良好的沟通平台。在此,评测会务组诚邀各个单位参加本次人机对话技术评测活动!
评测内容
评测任务概述
本届人机对话技术评测主要包括两个任务,参赛者可以选择参加任意一个任务或全部任务。
任务1:自然语言理解评测
【背景介绍】
任务型对话系统是指以人机对话的形式提供信息或服务的系统。通常情况下是为了满足带有明确目的的用户,例如查流量、查话费、订餐、订票、咨询等任务型场景。鉴于其广泛的应用前景,任务型对话系统近年来受到学术界和工业界的越来越多的关注。
任务型对话系统核心模块主要包括三部分:
自然语言理解模块 —— Natural Language Understanding (NLU)
对话管理模块 —— Dialog Management (DM)
自然语言生成模块 —— Natural Language Generation (NLG)
本评测任务针对自然语言理解模块,其主要包括下面三个子任务:领域分类、意图识别和语义槽填充。与去年评测中只进行领域分类不同,本次我们同时进行三项任务的评测,以更好的评测各个参赛系统的自然语言理解能力。
【任务描述】
本次评测包括领域分类、意图识别和语义槽填充三项子任务,例如给定一个用户的表达句子“我想订上海飞往北京的航班”。则该句的
领域为:“机票”
意图为:“订机票”
语义槽为:
departCity:上海
arriveCity:北京
关于领域、意图和语义槽的详细定义以及数据集的规模我们后续将提供。
【评测说明】
本次评测包括单轮对话用户意图的领域分类、意图识别和语义槽填充任务,多轮对话整体意图的理解不在此次评测范围之内。
【评测方式】
参赛者报名后,可以获取主办方提供的评测数据(包括训练及开发数据)。评测时,参赛者在线提交评测系统,主办方在测试集上运行评测系统并得出评测结果,参赛者可以多次提交评测系统,评测结果实时更新并公开排名。
【评价指标】
对于领域分类和意图识别:采取准确率(acc)来进行评价。
对于语义槽填充:采用准确率(P)、召回率(R)及F值评价。
为了综合考虑模型的能力,我们最终采用句准确率(sentence acc)来衡量一句话领域分类、意图识别和语义槽填充的综合能力,即以上三项结果全部正确时候才算正确,其余均算错误。本次评测最终以sentence acc作为最后评价指标。
任务2:个性化对话竞赛
【背景介绍】
在人机对话系统领域,赋予对话机器人特定的个性化特征是一项极具挑战性的任务。如在所生成的回复中体现特定的性别,地域和爱好特征。有效地解决这一任务可以极大地提升人机对话系统的智能化程度,从而带来更好的用户体验。
【任务描述】
在对话场景下,已知对话上下文和所有对话参与者的个性化属性,要求生成符合给定个性化特性与上下文逻辑的回复R。
所谓个性化属性由一系列键值对(如<性别, 男>, <年龄, 90后>)描述:
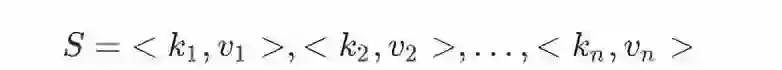
所生成的回复R需要足够流畅、与对话上下文语义相关并且符合所指定的发话人个性化特征。
【数据介绍】
本竞赛所准备的数据被分为三部分:训练集、开发集与测试集,其中训练集和开发集开放给各参赛队。测试集在竞赛结束前不会开放给参赛队。
训练集
训练集中包含约5百万轮次的对话,以及参与这些对话的发话人的个性化信息。训练集中既包含单轮对话又包含多轮对话。发话人的个性化数据包括性别、年龄、兴趣爱好标签和所属地域。
开发集
开发集由两部分组成:
随机部分,这一部分中包含1万轮对话,这些对话是随机采样得到的。
有偏部分,这一部分中包含约400轮对话,这些对话是人工筛选得到的,其涵盖了更多的个性化信息相关话题。人工筛选过程中会挑选显著体现发话人个性化特征的对话。在这些对话语境中,拥有不同个性化信息的用户有可能会产生不同的回复。
3. 测试集
测试集的构造方法与开发集相同。事实上,开发集与测试集中所包含的对话是同时构建的,这些对话被随机分成两份,分别形成了开发集与测试集。
【数据实例】
-----------------------------------------
s1 这么敬业,老板应该给你加工资。
s2 下个月涨工资,我们社长人还不错
s1 恭喜,请我吃饭。
s2 好啊,来深圳撒
s1 要得,明天就到。
s2 最好多带个帅哥来啊
s1 好的,我带个班过来。[雷锋]
s1:(性别:男, 年龄:80后, 地域:'辽宁', 爱好标签:'重口味')
s2:(性别:女, 年龄:90后, 地域:'湖南 长沙', 爱好标签'长沙生活;美食;服装控;看书;宅女一枚;吃货')
-----------------------------------------
s1 半斤白酒已下肚
s2 能赏我口饭吃吗
s1 好啊,问题是………… 你过得来吗
s2 你可以开灰机来接我吗
s1 白机中不?
s2 是飞机吗
s1 那也得等姐有money 了
s2 蚂蚁老多了
s1 弟弟,咱俩私聊去
s2 不,弟弟没空,忙着呢
s1:(性别:女, 年龄:80后, 地域:'河南 商丘', 兴趣标签:'育儿百科')
s2:(性别:男, 年龄:00后, 地域:'上海 黄浦区', 兴趣标签:'快乐大本营;开朗;旅游;娱乐')
-----------------------------------------
s1 居然可以钓鱼
s2 呃。。。当然咯
s1 随便钓的吗?不用收费?
s2 是河里啊,孩子,我们家乡这边基本无污染,河里好多鱼的,干嘛要收费?
s1 我以为是去钓鱼场。我没见过有鱼的河。
s2 你们那污染也太严重了吧
s1 中国发展太快了。
s2 呵呵,失去了一些本该拥有的美好东西
s1 好想在河边钓鱼
s2 哈哈,会有机会的,全国很多地方的河里还是有鱼的
s1 我不懂钓鱼...
s2 呃,其实不是很难的,要是在华工,体育还有钓鱼这门课的
s1 我们学校似乎没有
s2 自己学咯,其实我们是从小玩到大的,不会难的
s1 嗯 有机会一定学
s1:(性别:男, 年龄:90后, 地域:'广东 广州', 兴趣标签:'怀旧派;摄影旅游;心理学爱好者')
s2:(性别:女, 年龄:90后, 地域:'海外 其他', 兴趣标签:'美食;麦霸;90后')
【评价规则】
自动评价
初赛阶段采用自动评价指标,参赛队需提交自己的模型。模型在测试集上的性能将会作为排名依据。
自动评测所使用的指标包括:
BLEU:评估输出回复相对于标准回复的n-gram重合度。
Perplexity:评估模型所输出结果的流畅性。
Distinct:评估输出回复的多样性。
我们会分别计算各个模型在以上三个指标上的排名,并以每个模型的最低排名作为排行榜的排序依据。
人工评价
决赛阶段选取排行榜中排名前10的对话系统进入人工评估。人工评估过程中会在测试集的随机部分和有偏部分分别选取200轮对话。并使用众包的方式对各参赛队所生成的回复在如下三个方面进行评价:
Fluency:生成回复的表达是否流畅,无语法错误。
Personality:生成回复是否符合所给定的发话人个性化特征。
Appropriateness:生成回复是否符合人们的日常交流习惯。
最终排名以人工评估结果为依据。
任务1、2评测方式
本次评测将主要采用CodaLab平台作为评测方式,数据及CodaLab平台将于2019年5月15日上线
注册报名
有意向参加的单位机构请直接填写在线报名表。
扫描二维码进入在线报名表填写。

报名存在任何问题,请联系评测会务组:smp2019ecdt@163.com
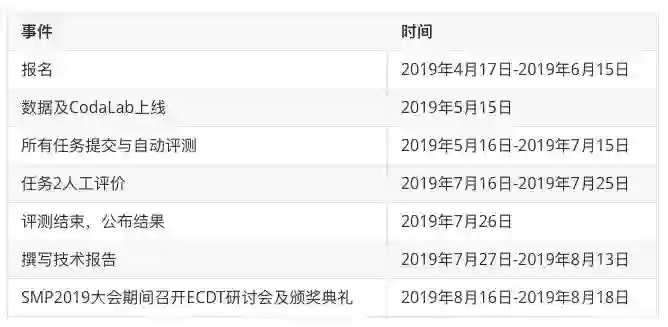
重要日期
以下所有时间点为北京时间(GMT+8)11:59 PM。
(除报名时间以外,其他时间点可能会有变动,请注册参加者密切关注本网站以及邮件通知。)
奖励
任务1:第一名 12000 元, 第二名 8000 元, 第三名 5000 元。
任务2:第一名 12000 元, 第二名 8000 元, 第三名 5000 元。
评测委员会
主席:张伟男(哈尔滨工业大学)
副主席:陈志刚(科大讯飞)、车万翔(哈尔滨工业大学)、黄民烈(清华大学)、张轶博(华为公司)
评测委员会成员:朱才海(哈尔滨工业大学)、覃立波(哈尔滨工业大学)、郑银河(清华大学)
联系方式
如果有任何与本次评测相关的问题,请随时联系会务组。
评测会务组邮箱:smp2019ecdt@163.com
致谢
主办方:中国中文信息学会社会媒体处理专业委员会(CIPS-SMP)
承办方:哈尔滨工业大学社会计算与信息检索研究中心(哈工大SCIR)、科大讯飞股份有限公司(iFLYTEK)、清华大学(CoAI)
赞助方:华为公司
本期责任编辑:丁 效
本期编辑:孙卓
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。