ECCV 2022 | SmoothNet:用神经网络代替平滑滤波器,不用重新训练才配叫“即插即用”

极市导读
本文针对姿态估计模型遇到的图像抖动问题,提出了用一个非常轻量的神经网络来代替传统滤波器的解决方法。这个基于深度学习的模型对时间维度进行建模,有着非常强的跨模型、跨数据集迁移性,真正做到了“即插即用”。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文地址:https://arxiv.org/pdf/2112.13715v2.pdf
0. 前言
姿态估计模型在实际工程部署中,大家经常会遇见的一个问题是:模型在单张图片上表现得好好的,但到了视频或摄像头上预测结果就会开始出现抖动,这显然不是我们希望看到的。过去我们常用的处理方法一般是对预测结果进行滤波,比如我之前介绍过的指数滑动平均滤波和卡尔曼滤波:https://zhuanlan.zhihu.com/p/433571477 和 https://zhuanlan.zhihu.com/p/442177476。
之前我看到过这样一种说法,卡尔曼滤波是优秀算法工程师的护城河,足以说明其难度和重要性。但实际上,这些滤波器都需要仔细调校滤波强度,而过强的不可避免地会造成输出结果的滞后,在一些对实时性要求高的场景下不够适用。
本文提出了一种基于深度学习的解决方法,用一个非常轻量的神经网络来代替传统滤波器,而且最难能可贵的一点在于,这个模型与输入端的耦合度非常低,可以任意地插入到崭新的姿态估计模型、数据集、模态信息中,而不需要进行finetune,真正做到了“即插即用”。
1. 简介
对于视频姿态估计任务中的预测抖动,近年来的解决方案大致可以分为两派:learning-based模型和低通滤波器。learning-based方法一般是利用一个时空模型同时优化每帧的预测精度和时间维度上的预测稳定性,比较常见的有TCN和RNN,不过性能一直不能得到很好的保证。低通滤波器方案,如指数滑动平均滤波和卡尔曼滤波,尽管理论和工程实现上都非常成熟了,但由于姿态估计模型的抖动是不均匀的,在一些场景下抖动会非常严重,而其他场景抖动又不太强,所以滤波器的参数很难调节,常常面临艰难的trade-off,而且一旦滤波强度太高还会导致输出结果存在延迟,无法保证实时性。
本文通过对抖动问题进行分析,总结出比较剧烈的抖动通常会连续性地出现在低画质、遮挡、罕见姿态(缺少数据)的情况,并提出了一个简单的全连接网络来建模时间维度上的长距离关系。与时空模型不同之处在于,这是一个纯时间维度建模的模型,而且有着非常强的跨模型、跨数据集迁移性。
2. 问题分析
本文对问题的拆分、定义和分析我觉得相当精彩,值得学习。本文首先根据持续时间将抖动问题分成了两类,瞬间抖动和长期抖动,用图像可以很清晰地表示出来:
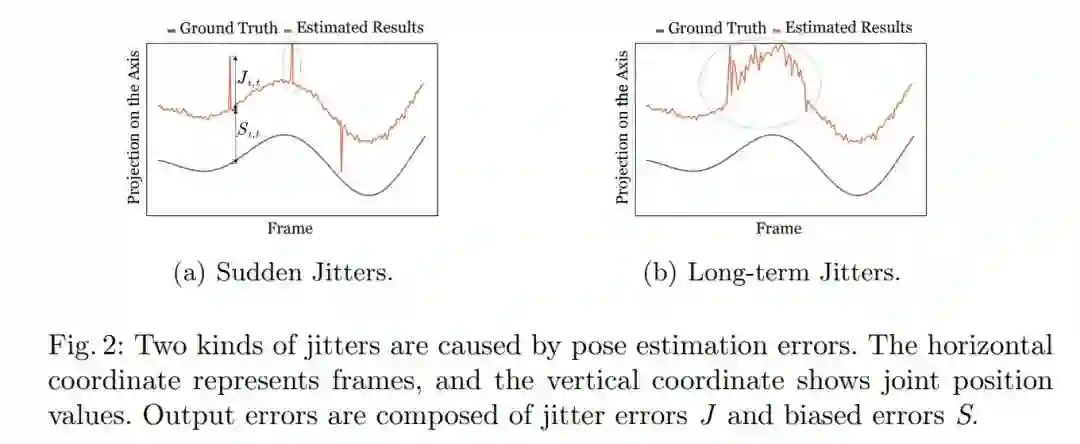
这种抖动由于偏离了ground truth,因此也是一种误差,于是我们可以按照性质把它们分为两部分:
-
相邻帧之间的 抖动误差J -
ground truth跟平滑后的姿态之间的 偏离误差S
用我的话来总结,可以理解为预测得“稳”和预测得“准”两个方面的问题。我们的终极目标实际上是希望这两种误差都降到最小。而根据抖动的程度,我们又可以分为:
-
轻微抖动:由不可避免的预测小误差和不连续的数据标注导致 -
剧烈抖动:由低质量图片、罕见姿态或严重遮挡导致
本文用姿态估计任务上性能很好的RLE模型进行了实验,分析了RLE在一段连续视频上的误差表现:
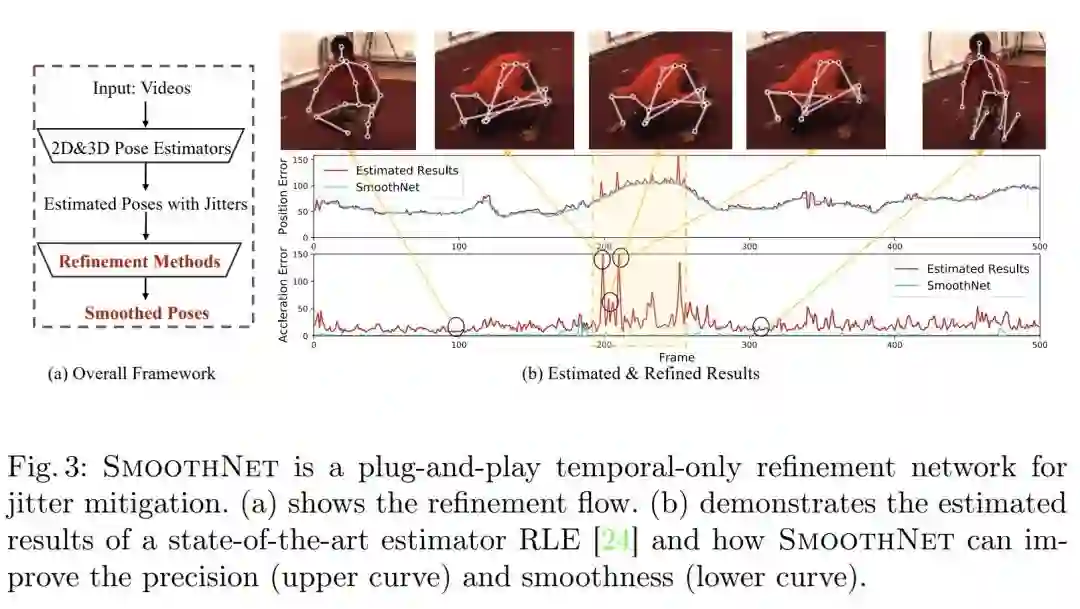
通过误差曲线可以看到,其实在大部分的场景中,当前的模型已经可以取得相对稳定且不错的姿态估计结果了,但在有些场景,误差出现了连续的较大的波动,这通常是姿态比较复杂,训练数据比较少导致的。瞬间抖动往往很容易被低通滤波器消除,但长期抖动由于本身准确性低,实际上是误差J和误差S共同作用的结果。
而learning-based方案,模型实际上是在同时优化这两个问题,本文实验显示,时空模型的确可以一定程度上降低误差J,只是降低的程度有限;如果设计专门的损失函数来引导模型优化误差J,又会导致误差S增大。这种现象在多任务学习中很常见,因为同时优化两个任务必然会使得两个任务存在竞争。正是因为存在这种问题,本文才提出了一个纯时间维度的姿态平滑方案,将任务进行了简化,模型只需要关注时间维度上的预测稳定性,换句话说,降低误差J。
3. 方法
Basic SmoothNet
关于为什么采用全连接层构建的模型,本文其实也分析了一下时空模型的几种方案,如TCN、Transformer等,各自罗列了一下它们的问题,但其实Transformer的部分不是很能说服我:本文说Transformer更关注提取长距离上两个元素的语义相关性,而这里需要的是建模每个关键点运动的连续性,是跨越了一段连续动作序列的,而不是点对点的相关性。但我觉得Transformer各种意义上接近于一个全面增强版的全连接网络,要说全连接网络比Transformer更强我是不太服气的,还不如说全连接网络轻量容易部署,或者攻击Transformer难训练之类的问题。
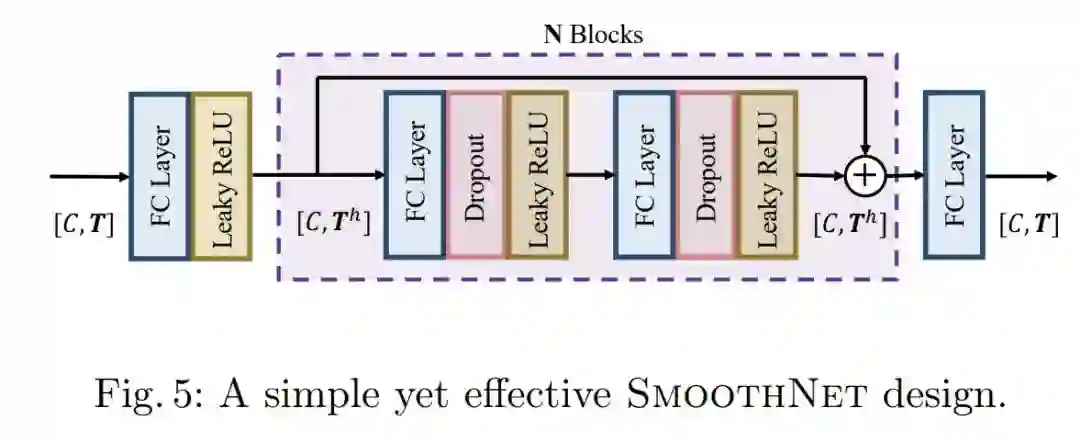
基础模型的设计也非常简单,就是一个带残差路径的MLP,这里我不得不说的是,Transformer里不也是这样的结构么。通过一个滑动窗口策略,我们就可以将连续的姿态估计结果送入本文提出的模型中进行平滑了。
Motion-aware SmoothNet
由于输入是连续的,根据相邻帧之间的关键点位置变化我们可以计算出位置、速度、加速度三个值,根据误差J的定义,这种相邻的抖动可以概括为一种加速度误差。其中速度和加速度这两个量跟运动的连续性是息息相关的,于是本文对基础模型进行了升级,让它同时建模这三个量,这一步的设计我觉得也很精彩:
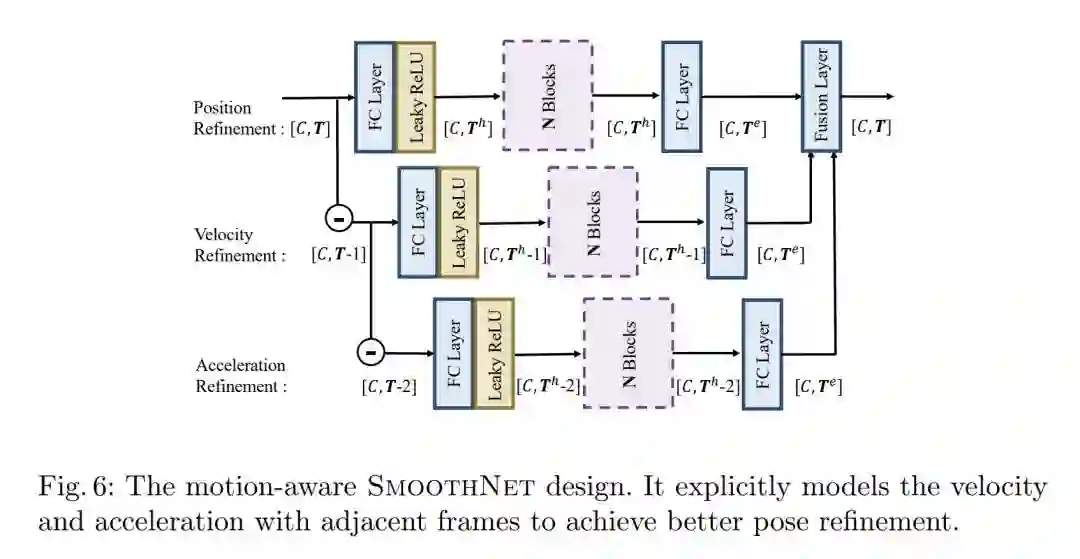
最终的模型参数量只有0.33M,在CPU上推理速度达到了1.3K FPS,在A100 GPU上为46.8K FPS,这种亚毫秒级的推理速度是完全不逊色于传统低通滤波器的。
Loss Function
根据上面的分析,损失函数的设计已经呼之欲出了,同时监督关键点位置误差和加速度误差就行:

4. 实验
作为一个平滑器,适用的场景和模型应该是非常广阔的,因此本文的实验也覆盖了2D、3D、SMPL模型,在大量的模型结构、任务和数据集上进行了实验,以验证该模型的通用性。本文的实验扎实到让人震撼的地步,很佩服作者团队严谨的态度。
对比低通滤波器
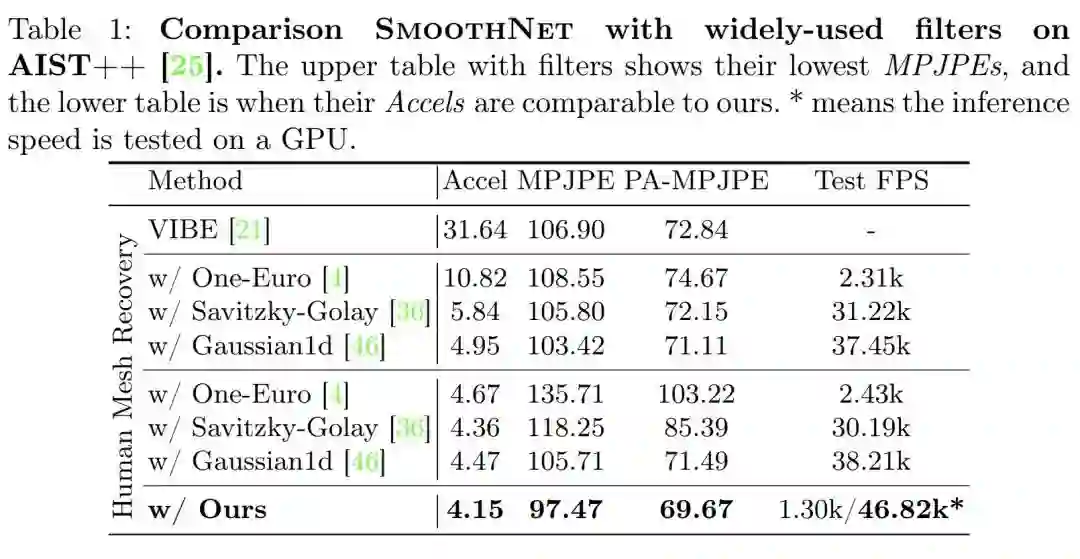
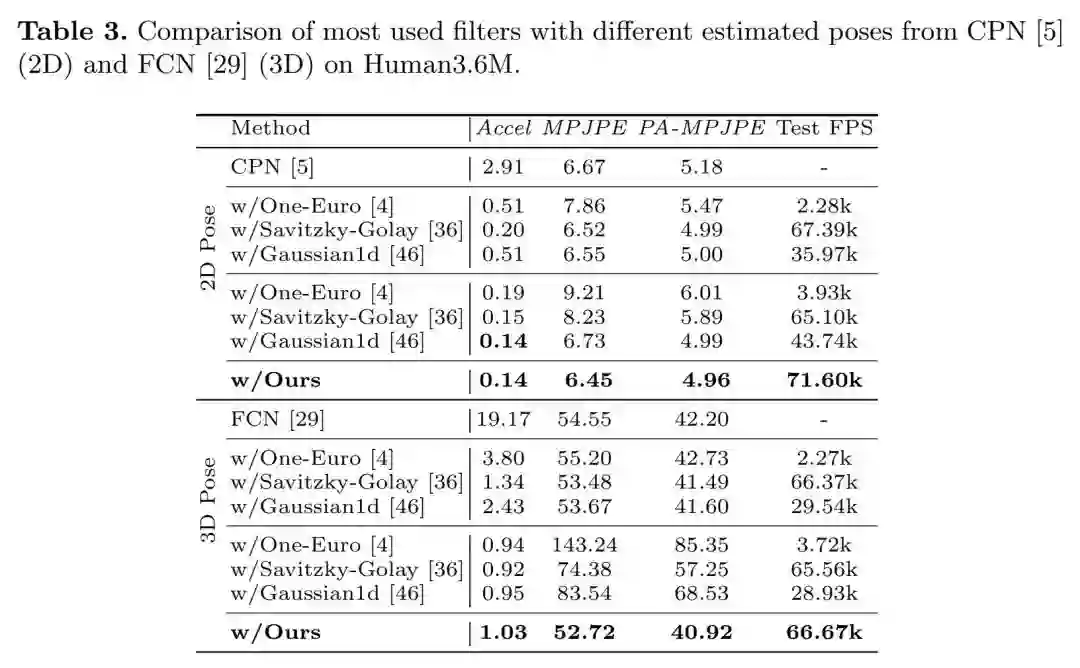
由于低通滤波器存在很大的调参空间,本表格上半部分展示了低通滤波器上MPJPEs最低的情况(即,准确度优先),下半部分展示了Accels加速度误差持平的情况(即,稳定性优先),可以看到SmoothNet不论是稳定性还是准确性都是最优的,而且神经网络模型可以很容易地迁移到GPU上运行,获得巨大的推理加速。
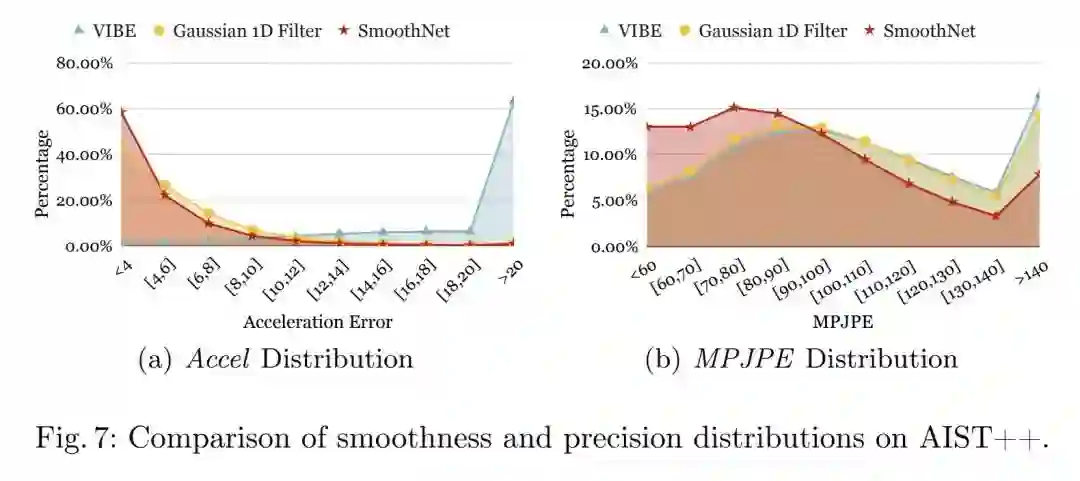
本文同样分析了准确性和稳定性误差的分布,可以看到原始VIBE的结果中,98.7%的加速度误差是在以上的,低通高斯滤波器和SmoothNet都能有效地将加速度误差分布压缩在一个相对低的范围内(56.5%和41.6%),但是SmoothNet更加出色,而在平滑后的姿态准确性上SmoothNet有比较明显的优势,而低通滤波器对预测准确性并无提升。更多对比实验:
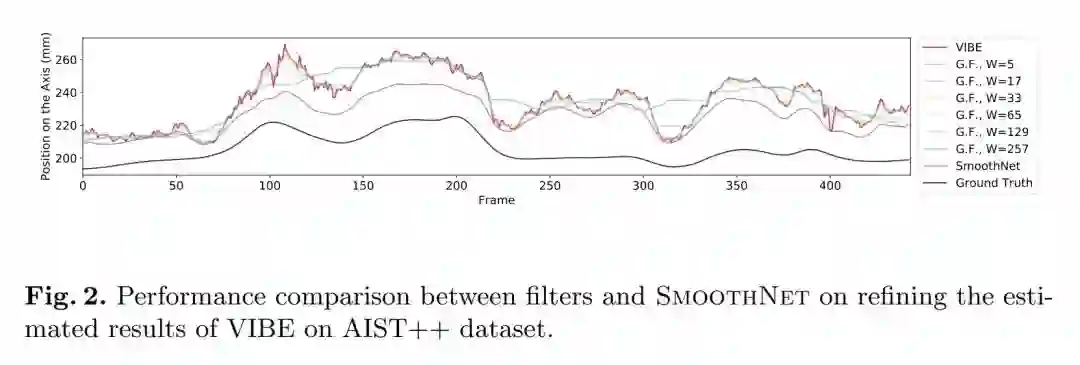
对比时空模型
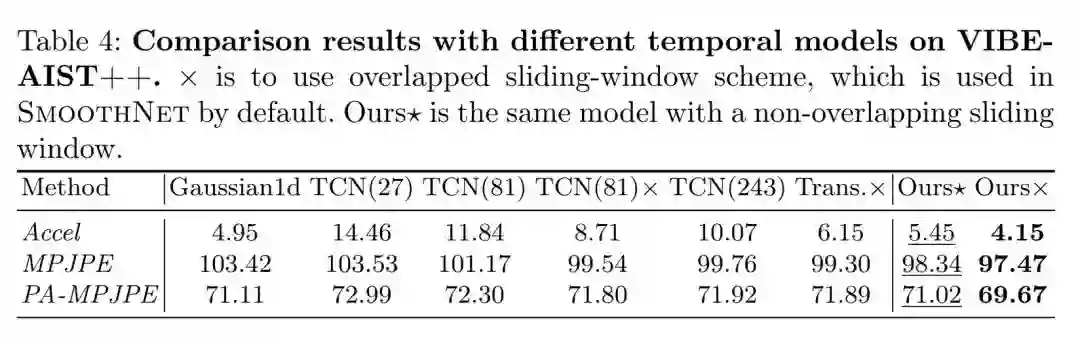
跟现有的时空模型对比,SmoothNet在稳定性和准确性上都进行了超越,而且关键是它很轻量。
与现有模型联合使用
作为一个即插即用的网络,SmoothNet可以跟任意的2D和3D姿态估计网络进行组合:
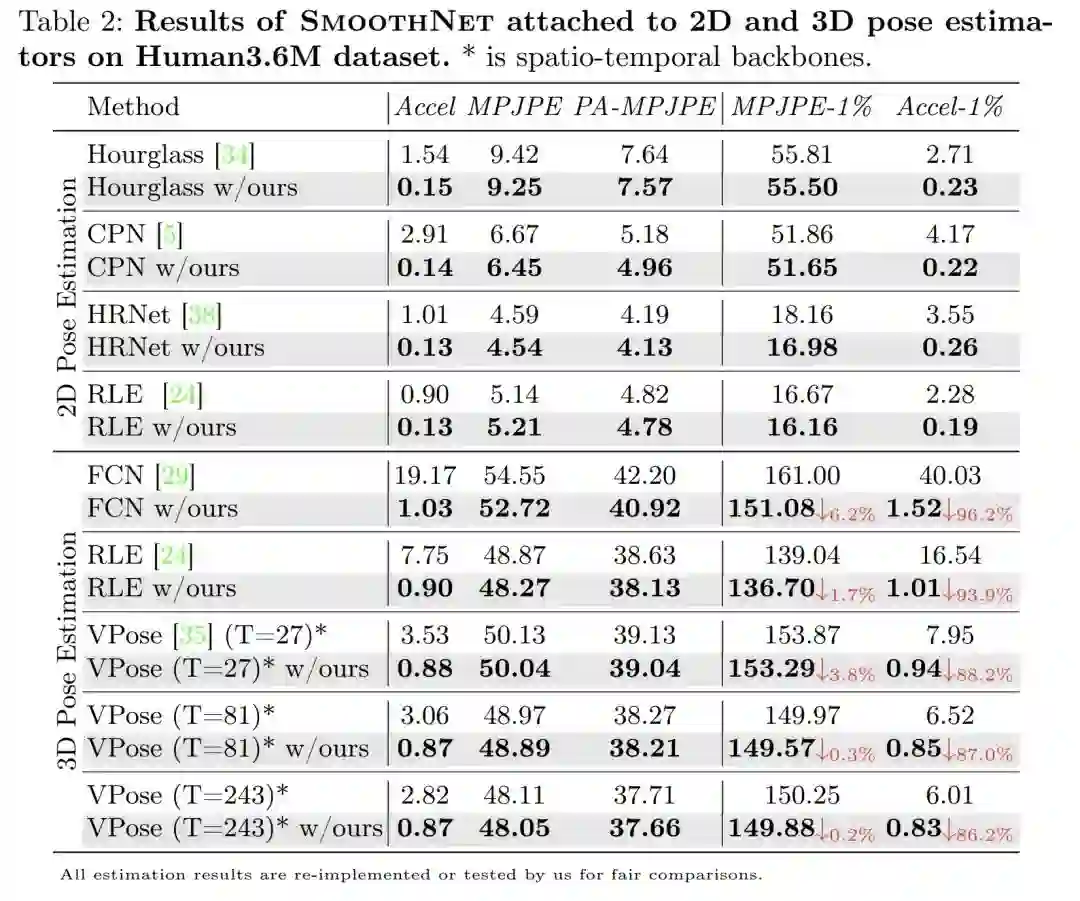
可以看到均可把加速度误差修正到一个非常低的水准,平均提升水平在90%,这意味着非常的稳,对关键点预测的准确性也能产生一定程度的修正,这属于是额外的收获了。更多实验:
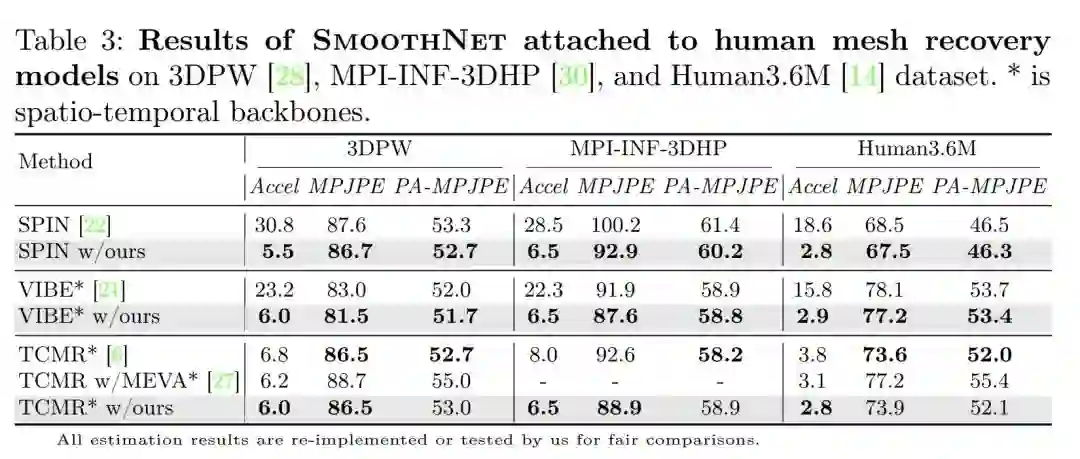
在人体网格重建任务上表现也同样优秀:
对最坏情况的改善
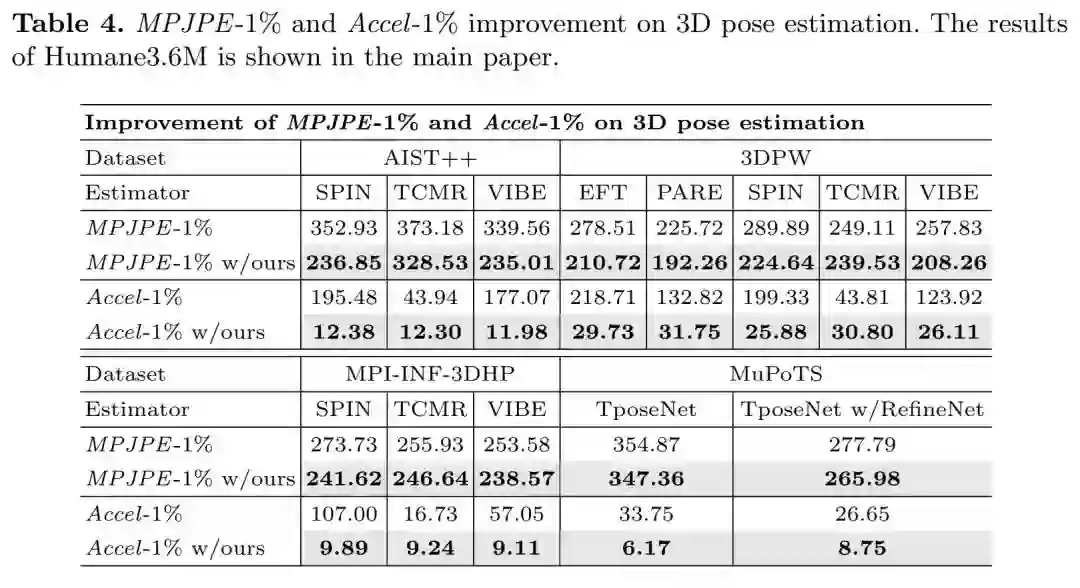
本文计算了准确性和稳定误差的最坏的1%值,来展现模型最差的情况,以此来分析SmoothNet对最差情况的改善:
泛化能力
本文做了海量的实验来验证模型的泛化能力,这其实一定程度上能反映出数据集之间的数据分布的距离。跨模态:
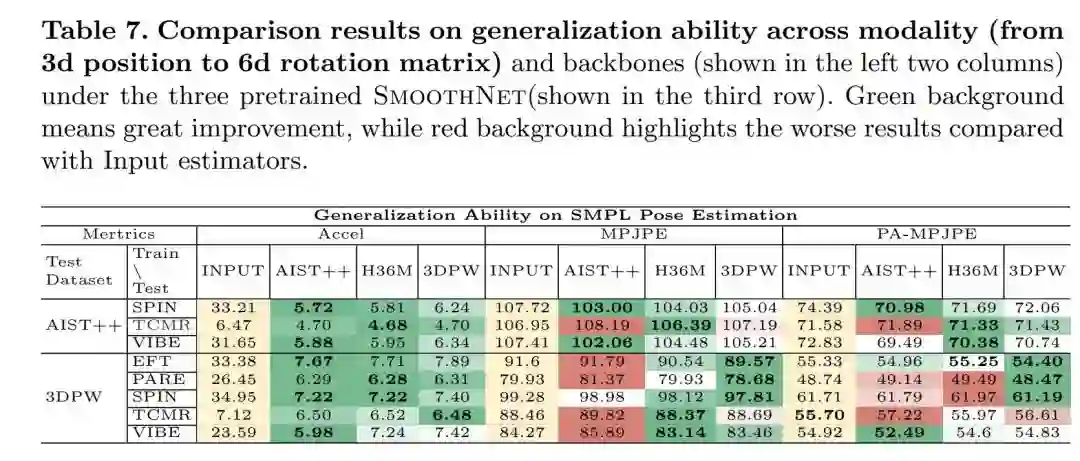
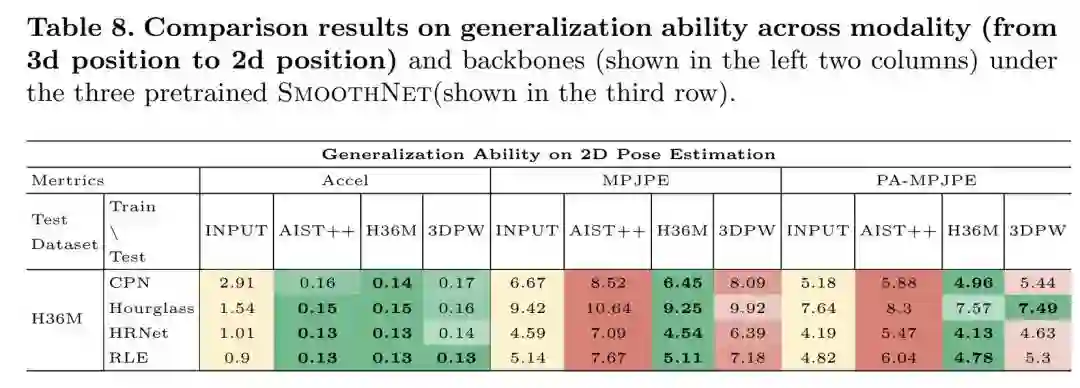
跨骨干网络:

对抗高斯噪声:
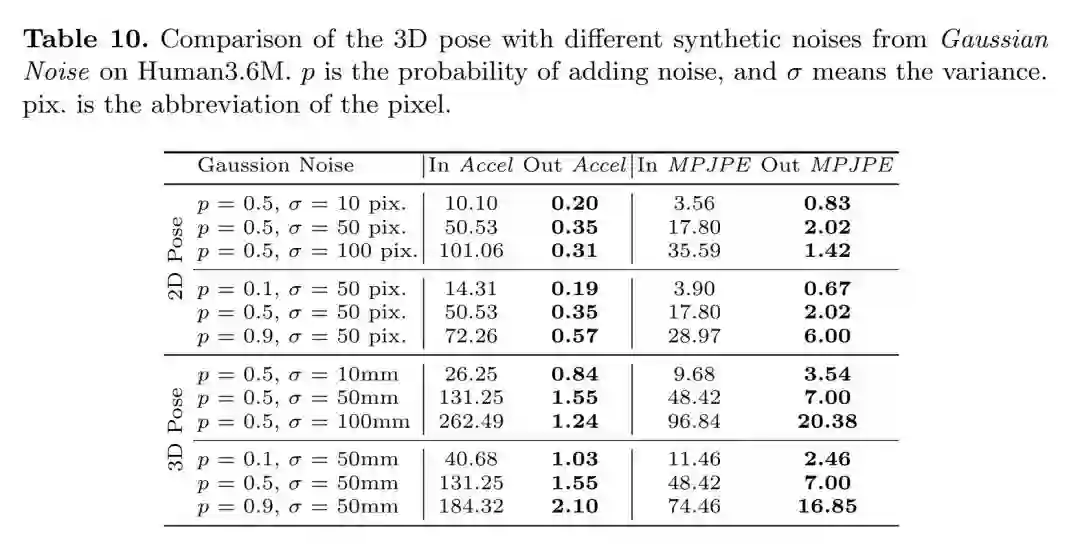
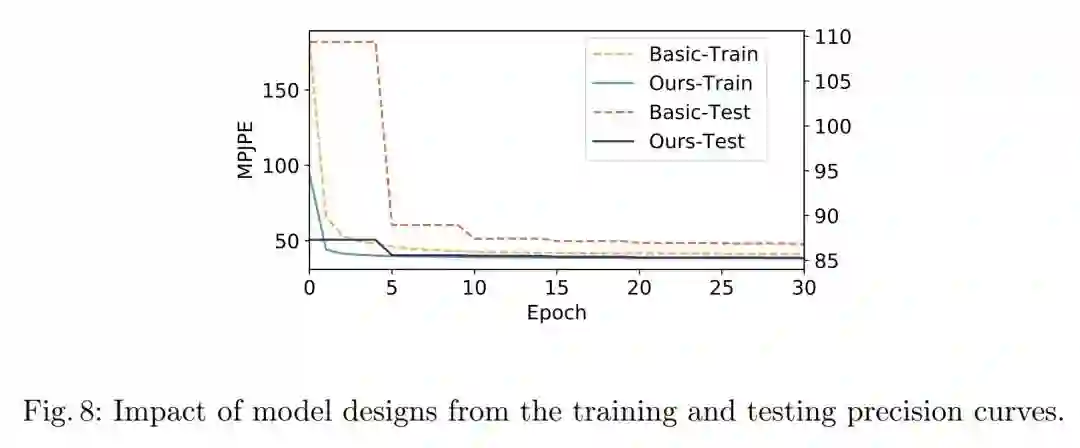
Baisc和Motion-aware模型对比
对速度和加速度这两个运动相关的物理量进行建模是非常棒的设计,最终取得的提升也很明显:
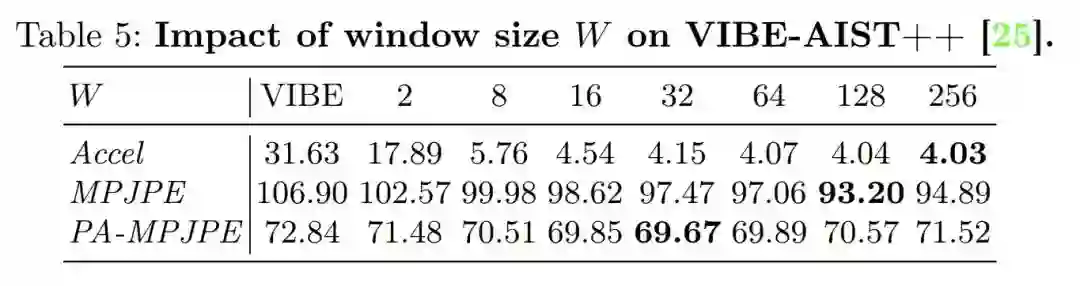
滑动窗口尺寸
滑动窗口策略在实际工程中也很常见,但也几乎一定会跟延迟、内存占用等问题绑定,因为你需要维护的帧数越多资源消耗越大,但本文的方法由于是基于关键点结果的,这方面的问题大大降低(相对于维护图片或者特征图而言),但还是需要根据需求来调整,根据实验来看,64是一个比较均衡的选择。
5. 结论
本文的补充材料里实验非常扎实,我上面展示的还只是一部分而已,更多的内容如果有小伙伴感兴趣可以自行查阅原文,我就不在这里一一分析了。我觉得本文对问题的分析思路非常清晰,每一步都有理有据,同时用海量的对比实验作为支撑,尤其是从多个角度对问题进行分类的研究方法很值得我学习。在结论部分本文也提到,目前的方法是基于滑动窗口的,而目前很多的低通滤波器实际上已经设计成基于递归的形式了,即只保存上一帧的结果即可,不需要维护一个很长的队列,这是本文之后可以继续做的一个方向。
公众号后台回复“ECCV2022”获取论文分类资源下载~

“
点击阅读原文进入CV社区
收获更多技术干货