浅谈混合精度训练imagenet

极市导读
本文作者通过自己实验得出了一些关于使用混合精度训练的结论,附有相关代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
零、序
本文没有任何的原理和解读,只有一些实验的结论,对于想使用混合精度训练的同学可以直接参考结论白嫖,或者直接拿github上的代码(文末放送)。
一、引言
以前做项目的时候出现过一个问题,使用FP16训练的时候,只要BatchSize增加(LR也对应增加)的时候训练,一段时间后就会出现loss异常,同时val对应的明显降低,甚至直接NAN的情况出现,图示如下:
-
这种是比较正常的损失和acc的情况,因为项目的数据非常长尾。
-
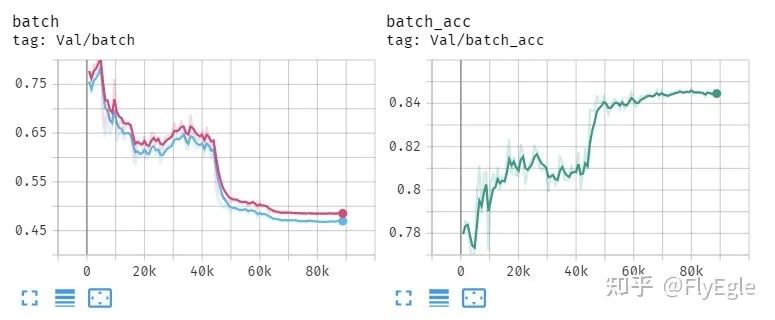
这种就是不正常的训练情况, val的损失不下降反而上升,acc不升反而降。
-
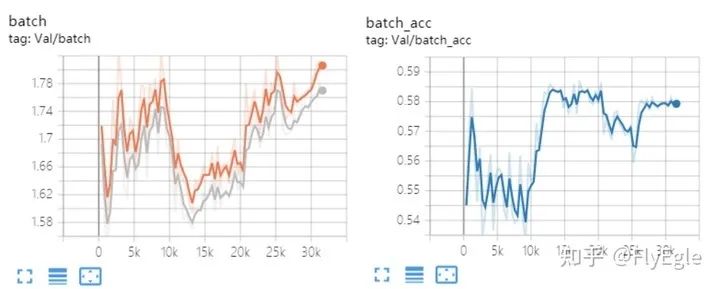
还有一种情况,就是训练十几个epoch以后,loss上升到非常大,acc为nan,后续训练都是nan,tensorboard显示有点问题,只好看ckpt的结果了。

由于以前每周都会跑很多模型,问题也不是经常出现,所以以为是偶然出现,不过最近恰好最近要做一些transformer的实验,在跑imagenet baseline(R50)的时候,出现了类似的问题,由于FP16训练的时候,出现了溢出的情况所导致的。简单的做了一些实验,整理如下。
二、混合精度训练
混合精度训练,以pytorch 1.6版本为基础的话,大致是有3种方案,依次介绍如下:
-
模型和输入输出直接half,如果有BN,那么BN计算需要转为FP32精度,我上面的问题就是基于此来训练的,代码如下:
if args.FP16:model = model.half()for bn in get_bn_modules(model):bn.float()...for data in dataloader:if args.FP16:image, label = data[0].half()output = model(image)losses = criterion(output, label)optimizer.zero_grad()losses.backward()optimizer.step()
-
使用NVIDIA的Apex库,这里有O1,O2,O3三种训练模式,代码如下:
try:from apex import ampfrom apex.parallel import convert_syncbn_modelfrom apex.parallel import DistributedDataParallel as DDPexcept Exception as e:print("amp have not been import !!!")if args.apex:model = convert_syncbn_model(model)if args.apex:model, optimizer = amp.initialize(model, optimizer, opt_level=args.mode)model = DDP(model, delay_allreduce=True)...for data in dataloader:image, label = data[0], data[1]batch_output = model(image)losses = criterion(batch_output, label)optimizer.zero_grad()if args.apex:with amp.scale_loss(losses, optimizer) as scaled_loss:scaled_loss.backward()optimizer.step()
-
pytorch1.6版本以后把apex并入到了自身的库里面,代码如下:
from torch.cuda.amp import autocast as autocastfrom torch.nn.parallel import DistributedDataParallel as DataParallelmodel = DataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True)if args.amp:scaler = torch.cuda.amp.GradScaler()for data in dataloader:label = data[0], data[1]if args.amp:with autocast():batch_output = model(image)losses = criterion(batch_output, label)if args.amp:scaler.scale(losses).backward()scaler.step(optimizer)scaler.update()
三、pytorch不同的分布式训练速度对比
-
环境配置如下:
CPU Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
GPU 8XV100 32G
cuda 10.2
pytorch 1.7.1
pytorch分布式有两种不同的启动方法,一种是单机多卡启动,一种是多机多卡启动。ps: DataParallel不是分布式训练。
-
多机启动
cd$FOLDER;CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -W ignore -m torch.distributed.launch --nproc_per_node 8 train_lanuch.py \...
-
单机启动
cd$FOLDER;CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -W ignore test.py \--dist-url 'tcp://127.0.0.1:9966' \--dist-backend 'nccl' \--multiprocessing-distributed=1 \--world-size=1 \--rank=0 \...
详细代码看文末的github链接。
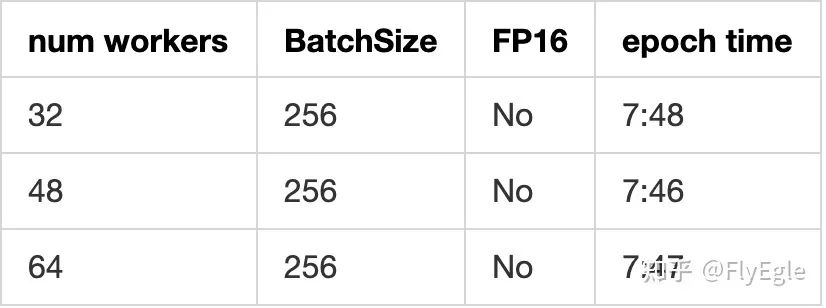
实验一、num workers对于速度的影响
我的服务器是48个物理核心,96个逻辑核心,所以48的情况下,效果最好,不过增加和减少对于模型的影响不大,基本上按照CPU的物理核心个数来设置就可以。
numworkers
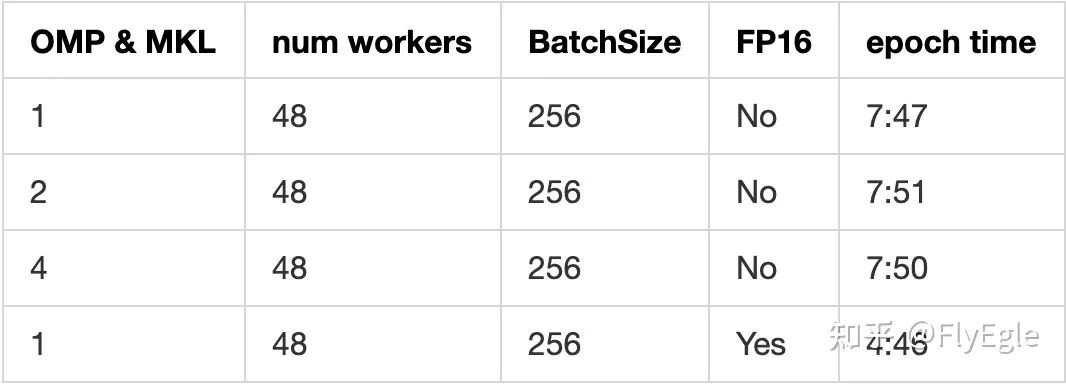
实验二、OMP和MKL对于速度的影响
OMP和MKL对于多机模式下的速度有轻微的影响,如果不想每个都去试,直接经验设置为1最合理。FP16大幅度提升模型的训练速度,可以节省2/5的时间。
omp&mkl
实验三、单机和多机启动速度差异
单机和多机启动,对于模型的前向基本是没有影响的, 主要的差异是在loader开始执行的速度,多机比起单机启动要快2倍-5倍左右的时间。
四、不同混合精度训练方法对比
实验均在ResNet50和imagenet下面进行的,LR随着BS变换和线性增长,公式如下
-
实验结果
模型FP16+BNFP32实验记录
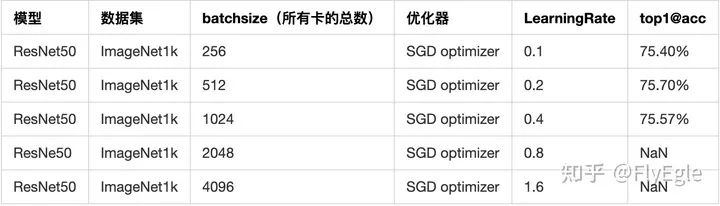
fp16
很明显可以发现,单存使用FP16进行训练,但是没有loss缩放的情况下,当BS和LR都增大的时候,训练是无法进行的,直接原因就是因为LR过大,导致模型更新的时候数值范围溢出了,同理loss也就直接为NAN了,我尝试把LR调小后发现,模型是可以正常训练的,只是精度略有所下降。
Apex混合精度实验记录

apex
Apex O3模式下的训练情况和上面FP16的结论是一致的,存FP16训练,不管是否有loss缩放都会导致训练NaN,O2和O1是没有任何问题的,O2的精度略低于O1的精度。
AMP实验记录

amp
AMP自动把模型需要用FP32计算的层或者op直接转换,不需要显著性指定。精度比apex高,同时训练时间更少。
2-bit训练,ACTNN
简单的尝试了一下2bit训练,1k的bs是可以跑的,不过速度相比FP16跑,慢了太多,基本可以pass掉了。
附上一个比较合理的收敛情况
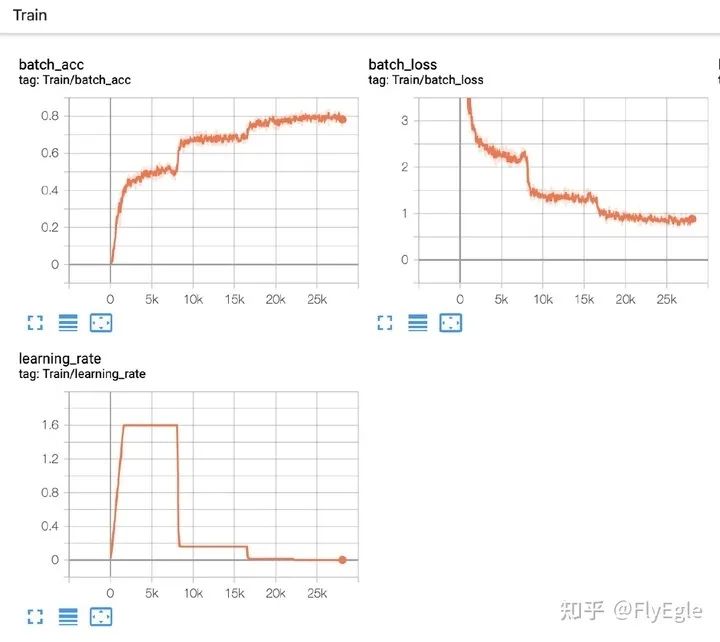
train
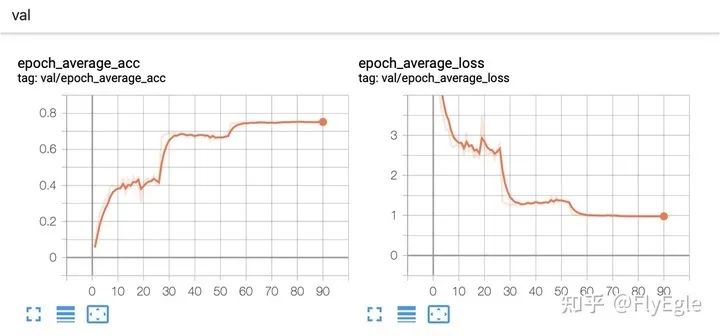
val
五、结论
-
如果使用分布式训练,使用pytorch 多机模式启动,收益比较高,如果你不希望所有卡都用的话,那么建议使用单机多卡的模式。 -
如果使用FP16方式计算的话,那么无脑pytorch amp就可以了,速度和精度都比较有优势,代码量也不多。 -
我的增强只用了随机裁剪,水平翻转,跑了90个epoch,原版的resnet50是跑了120个epoch,还有color jitter,imagenet上one crop的结果0.76012,和我的结果相差无几,所以分类任务(基本上最后是求概率的问题,图像,视频都work,已经验证过)上FP16很明显完全可以替代FP32。我跑了一个120epoch的版本,结果是0.767,吊打原版本结果了QAQ。 -
如果跑小的bs,第一种FP16的方法完全是ok的,对于大的bs来说,使用AMP会使得模型的收敛更加稳定。 -
如果显存足够大,用大的BS会获得更好的训练收益。 -
代码自行取用。
FlyEgle/imageclassificationgithub.com
公众号后台回复“目标检测综述”获取目标检测二十年综述下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




