在注意力中重新思考Softmax:分解非线性,这个线性transformer变体实现多项SOTA

极市导读
来自商汤、上海人工智能实验室等机构的研究者用线性 COSFORMER 来取代 transformer 中的 softmax 注意力机制,在多项任务上达到最优。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Transformer 在自然语言处理、计算机视觉和音频处理方面取得了巨大的成功。作为其核心组件之一,softmax 注意力有助于捕获长程依赖关系,但由于序列长度的二次空间和时间复杂度而禁止其扩展。研究者通常采用核(Kernel)方法通过逼近 softmax 算子来降低复杂度。然而,由于近似误差,它们的性能在不同的任务 / 语料库中有所不同,与普通的 softmax 注意力相比,其性能会下降。
研究者认为 softmax 算子是主要障碍,而对 softmax 高效而准确的逼近很难实现,因此很自然地提出一个问题:我们能否用线性函数代替 softmax 算子,同时保持其关键属性?
通过对 softmax 注意力的深入研究,研究发现了影响其经验性能的两个关键性质:
(i) 注意力矩阵的非负性;
(ii) 一种非线性重重加权方案,可以聚集注意力矩阵分布。
这些发现揭示了当前方法的一些新见解。例如,线性 transformer 使用指数线性单元激活函数来实现属性 (i)。然而,由于缺乏重重加权(re-weighting )方案,表现不佳。
本文中,来自商汤、上海人工智能实验室等机构的研究者提出了一种称为 COSFORMER 的线性 transformer,它能同时满足上述两个特性。具体来说,在计算相似度分数之前,该研究将特征传递给 ReLU 激活函数来强制执行非负属性。通过这种方式使得模型避免聚合负相关的上下文信息。此外,该研究还基于余弦距离重加权机制来稳定注意力权值。这有助于模型放大局部相关性,而局部相关性通常包含更多自然语言任务的相关信息。
在语言建模和文本理解任务的大量实验证明 COSFORMER 方法的有效性,并且在长序列 Long-Range Arena 基准上实现了 SOTA 性能,这一结果很好地证明了 COSFORMER 在建模长序列输入方面的强大能力。

论文地址:https://arxiv.org/pdf/2202.08791.pdf
方法
研究者表示,COSFORMER 的关键思路在于将不可分解非线性 softmax 操作替换为具有可分解非线性重加权机制的线性操作。该模型适用于随机注意力和交叉注意力,并且输入序列长度具有线性时间和空间复杂度,从而在建模长程依赖中显示出强大的能力。
一般而言,我们可以选择任意相似度函数来计算注意力矩阵,如下公式(2)所示
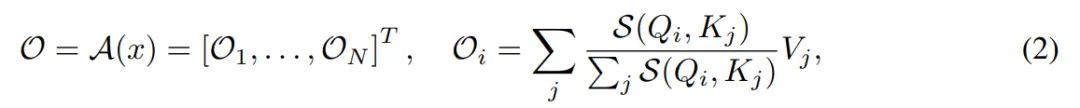
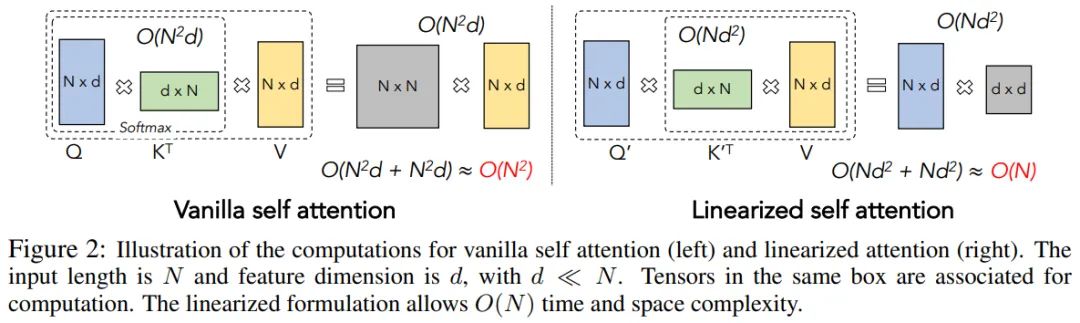
下图 2 为原始自注意力(左)与线性注意力(右)的计算示意图。
大多数现有线性 transformers 想要找到针对 softmax 注意力的无偏估计。然而,研究者实证发现,这些方法对采样率的选择非常敏感,一旦采样率过高,则会变得不稳定。并且,考虑到近期偏差,门机制可以用来更好地探索较新的上下文。另一类工作则试图直接用线性操作替换 softmax。
研究者提出了 softmax 的一种新替换,不仅可以在一系列任务中实现与 softmax 相当甚至更好的性能,而且具有线性空间和时间复杂度。
研究者经过实证确认了 softmax 操作的两种可能在性能表现中发挥重要作用的关键特性,其一是确保注意力矩阵 A 中的所有值是非负的,其二是提供一种非线性重加权机制来聚集注意力连接的分布并稳定训练。为了验证这些假设,研究者设计了如下表 1 中的初步研究。
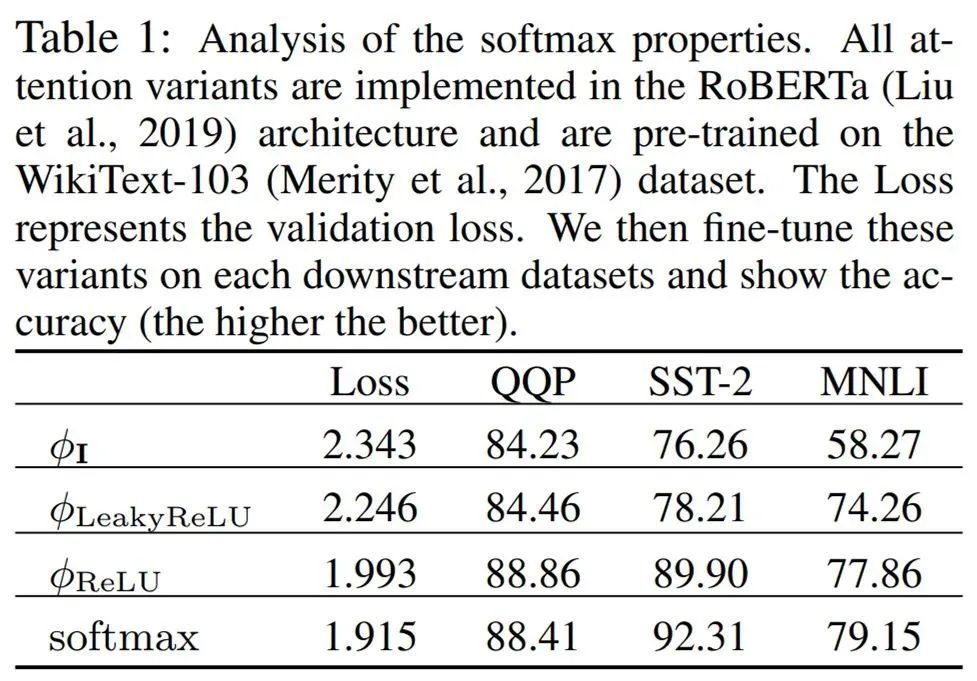
通过将 的结果与 softmax 相比较,研究者发现,具有 softmax 重加权的模型收敛速度更快,到下游任务的泛化表现更好。
COSFORMER
基于以上发现, 研究者提出了模型 COSFORMER, 它完全丢弃了 softmax 归一化, 同时具有非负 性和重加权机制。COSFORMER 包含两个主要的组件, 分别为线性投影核 linear 和 cos-Based 重加权机制。
首先来看线性投影核 linear 。基于上文公式 2 中注意力的通用格式, 研究者将线性相似度定义如 下公式 (6) 所示。
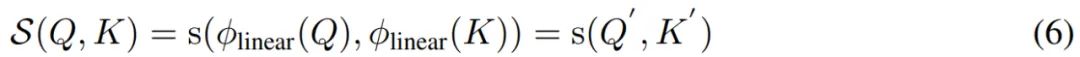
具体地,为了确保全正(full positive)的注意力矩阵 A 并避免聚合负相关的信息,研究者将 ReLU(·) 用作转换函数,从而可以有效地消除负值,如下公式(7)所示。

研究者还重新调整了点积(dot-product)的顺序,并得到了线性复杂度中所提注意力的公式(9)。
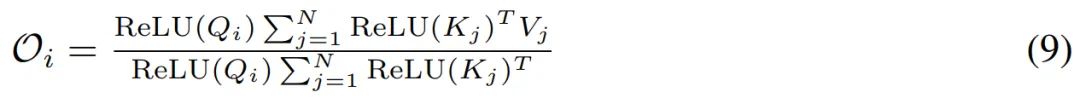
在 softmax 注意力中引入非线性重加权机制可以聚集注意力权重的分布,因而稳定训练过程。研究者还通过实证发现,这种做法可以惩罚远距离连接,并在某些情况下加强局部性。实际上,这类局部性偏差,也即是一大部分上下文依赖来自邻近 token,通常可以在下游 NLP 任务上发现,如下图(3)所示。
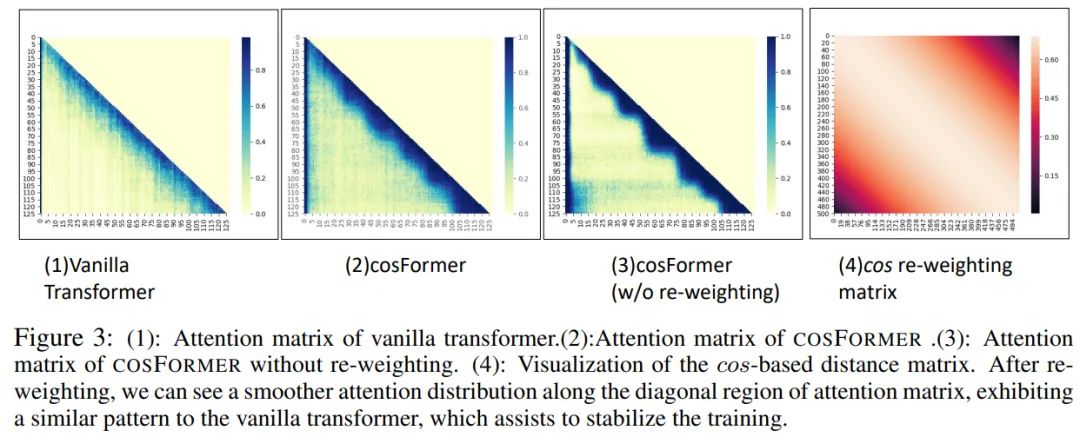
基于上述假设,要满足 softmax 的第二种特性需要一种可分解的重加权机制,该机制可以将近期偏差引入到注意力矩阵。研究者提出了一种能够完美满足目标的 cos-based 重加权机制。通过上图 3(2)和(3)中比较注意力矩阵,可以看到,COSFORMER 能够比不具有重加权机制的 COSFORMER 执行更多的局部性。
具有余弦重加权机制的模型可以定义如下公式(10)所示。
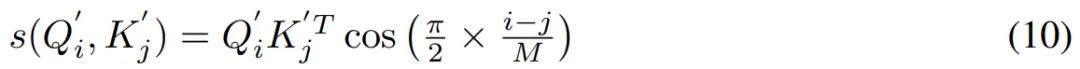
同时,COSFORMER 还可以看作一种将相对位置偏差引入到高效 transformer 中的新方法。
实验
实验验证了 COSFORMER 在多种设置中的有效性。
首先,该研究使用 WikiText-103,通过自回归和双向语言模型(bidirectional)设置验证了 COSFORMER 在语言建模中的能力。通过这种方式,该研究验证了所提出的线性注意力模块在因果和非因果情况下的有效性。
自回归建模语言:该研究采用 (Baevski & Auli, 2018) 作为基线模型,并用所提出的线性注意力模块替换自注意力模块,在 8 个 Nvidia Tesla A100 GPU 上进行训练,表 2 中报告了结果。
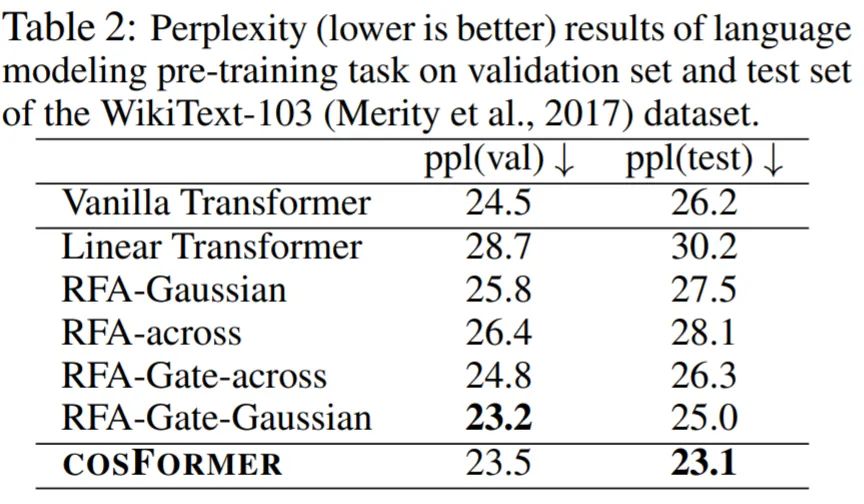
由结果可得,尽管基线模型是一个性能强大的标准 transformer,但它需要二次计算复杂度,但 COSFORMER 在线性计算复杂度方面明显优于基线模型。此外,该研究在验证集上实现了与其他方法相当的困惑度(perplexity),并且在测试集上明显优于其他方法,这进一步证明了 COSFORMER 的有效性。
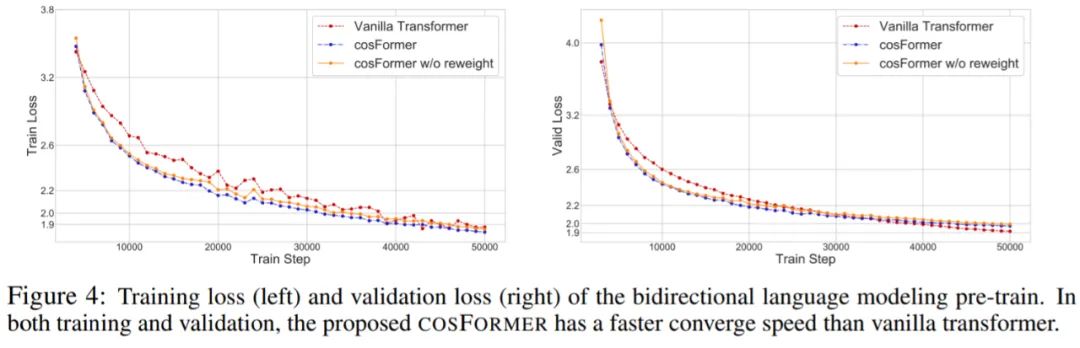
双向语言模型:对于双向语言建模,该研究采用 RoBERTa (Liu et al., 2019) 作为基线模型。同样的将 RoBERTa 中的自注意力模块替换为线性注意力模块,并保持其他结构不变,该研究在 2 个 Nvidia Tesla A100 GPU 上训练双向任务。如图 4 所示,COSFORMER 在训练集和验证集上的收敛速度都比 vanilla Transformer 快,具有可比或更小的损失值。此外,与没有重重加权的模型相比,具有重重加权机制的 COSFORMER 变体具有明显更好的收敛速度和最终结果,这进一步验证了基于余弦的距离矩阵的有效性。
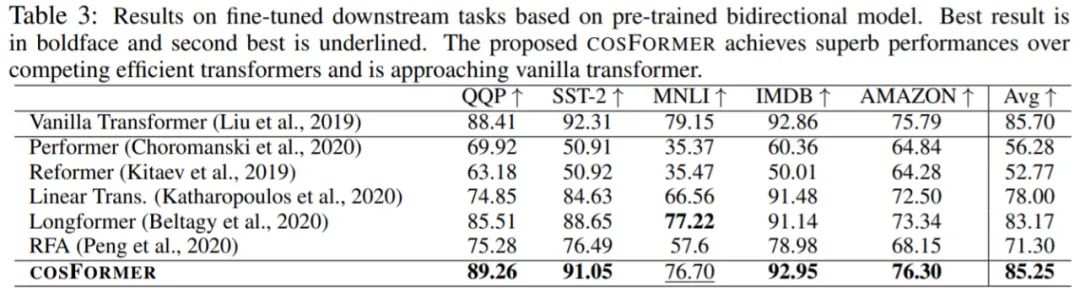
其次,该研究通过与其他现有的 Transformer 变体进行比较,研究了 COSFORMER 在下游任务上的泛化能力。
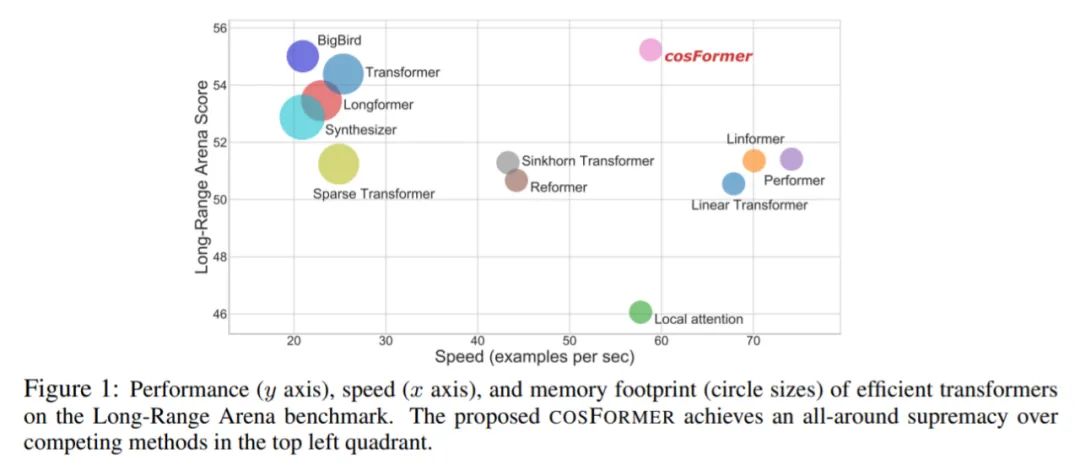
从表 3 中,我们可以看到 COSFORMER 在多个数据集上优于基线(Liu et al., 2019),此外与其他高效的 transformer 相比,COSFORMER 在所有五个下游数据集上均达到最佳或次要位置。值得注意的是,尽管 Longformer (Beltagy et al., 2020) 在 MNLI 上取得了比 COSFORMER 更好的结果,但它需要 O(Nw) 的计算复杂度。如图 1 所示,Longformer 比 COSFORMER 更慢并且需要更多的内存开销。
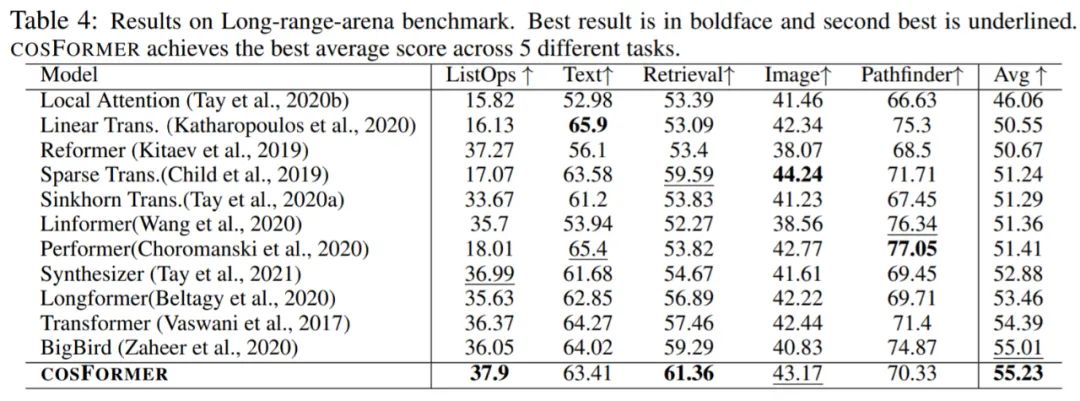
该研究进一步在 long-range-arena 基准上将 COSFORMER 与其他 transformer 变体进行比较,以了解其建模远程依赖关系的能力并展示对模型效率的比较分析 。
如表 4 所示,总体上来说 COSFORMER 在所有任务中都取得了具有竞争力的结果,同时在 ListOps 和文档检索方面取得了最佳性能。值得一提的是,COSFORMER 在 Long-range-arena 基准测试中取得了最好的整体分数,是仅有的两个超越 vanilla transformer 架构的模型之一。
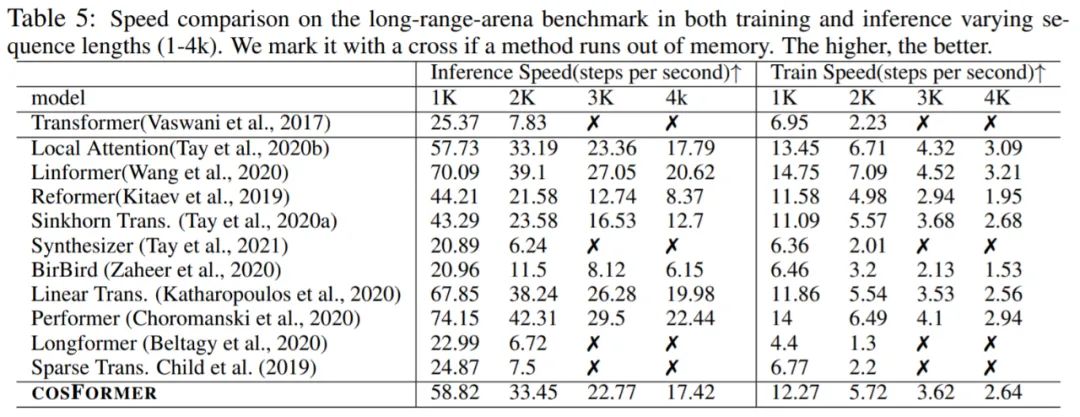
如表 5 和图 1 所示,大多数基于模式、vanilla transformer 的方法都比 COSFORMER 更慢并且需要更大的内存。COSFORMER 在保持卓越建模和泛化能力的同时,总体上比其他线性变体实现了更好的效率。
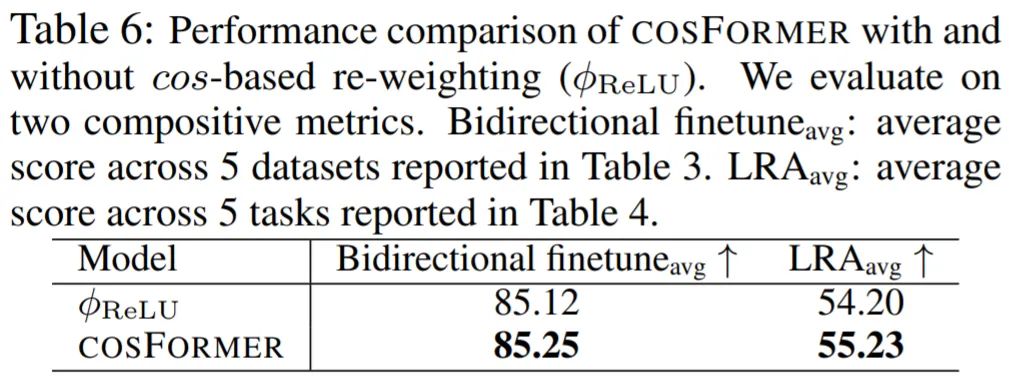
最后,该研究进行消融实验,以了解 COFORMER 中具有和不具有重重加权机制的影响,如表 6 所示,COSFORMER 在没有重重加权的情况下取得了更好的整体结果,显着提高了双向微调和 long-range-arena 的平均分数。这验证了所提出的重重加权有效地结合了自然语言任务的局部归纳偏差。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



