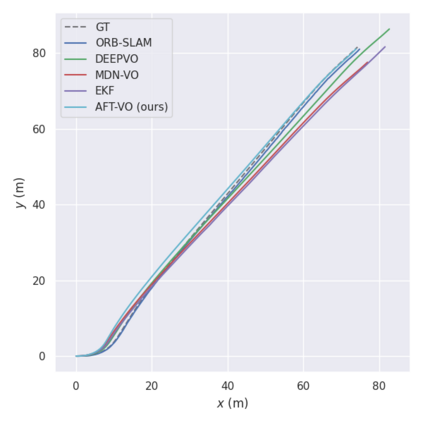
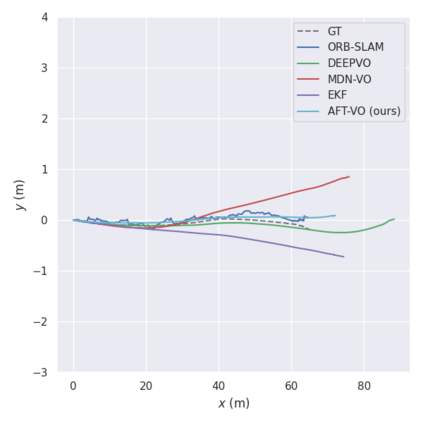
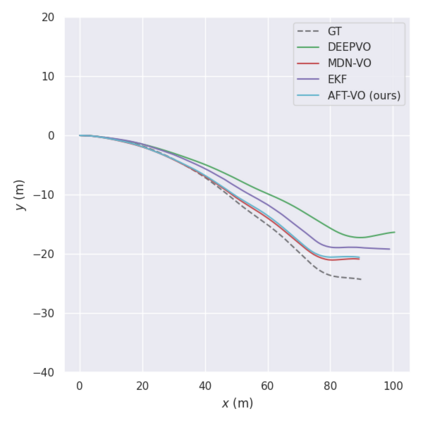
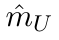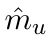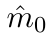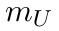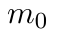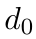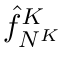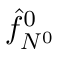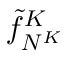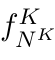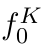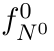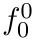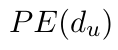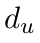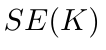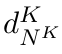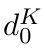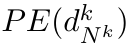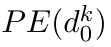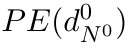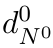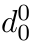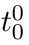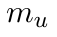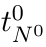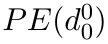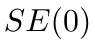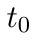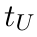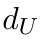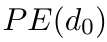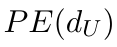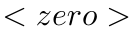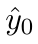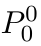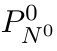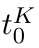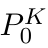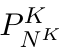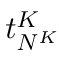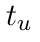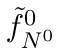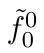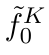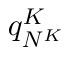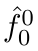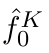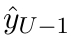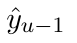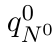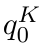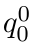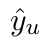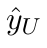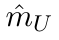Motion estimation approaches typically employ sensor fusion techniques, such as the Kalman Filter, to handle individual sensor failures. More recently, deep learning-based fusion approaches have been proposed, increasing the performance and requiring less model-specific implementations. However, current deep fusion approaches often assume that sensors are synchronised, which is not always practical, especially for low-cost hardware. To address this limitation, in this work, we propose AFT-VO, a novel transformer-based sensor fusion architecture to estimate VO from multiple sensors. Our framework combines predictions from asynchronous multi-view cameras and accounts for the time discrepancies of measurements coming from different sources. Our approach first employs a Mixture Density Network (MDN) to estimate the probability distributions of the 6-DoF poses for every camera in the system. Then a novel transformer-based fusion module, AFT-VO, is introduced, which combines these asynchronous pose estimations, along with their confidences. More specifically, we introduce Discretiser and Source Encoding techniques which enable the fusion of multi-source asynchronous signals. We evaluate our approach on the popular nuScenes and KITTI datasets. Our experiments demonstrate that multi-view fusion for VO estimation provides robust and accurate trajectories, outperforming the state of the art in both challenging weather and lighting conditions.
翻译:为了应对这一局限性,我们建议AFT-VO(AFT-VO)在这项工作中提出一个新的基于变压器的传感器聚合结构,以便从多个传感器中估计VO。我们的框架结合了来自不同来源的不同步多视相机的预测和源源时间差异的计算。我们的方法首先使用一个混合密度网络(MDN)来估计6-DOF对系统每个摄像头的概率分布。然后推出一个新的基于变压器的熔化模块AFT-VO(AFT-VO),该模块结合了这些不连贯的预测以及它们的信心。更具体地说,我们引入了分解和源代码解技术,用于测量不同来源的测量时间差异。我们的方法首先使用了一个混合密度网络(MDN)来估计6-DoF对系统每个摄像头的概率分布。然后引入了一个新的基于变压器的熔化器组合模块AFT-VO(AFT-VO),将这些不连贯的预测与它们的信任结合起来。更具体地说,我们引入了分解器和源解调调调和源解调调化技术,我们用于将多源的螺旋路路段的图像的图像的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的演示,为我们提供了我们的演制制制导。