AAAI 22|大连理工IIAU Lab提出SSLSOD:自监督预训练的RGB-D显著性目标检测模型

极市导读
本文在显著性目标检测任务(SOD)中,首次引入自监督预训练。凭借提出的有效的前置任务(pretext task),在仅使用少量无标签的RGB-D数据进行预训练的情况下,该模型仍能够具有竞争力的表现。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

大连理工 IIAU Lab 提出 SSLSOD:自监督预训练的 RGB-D 显著性目标检测模型。该文在显著性目标检测任务(SOD)中,首次引入自监督预训练。凭借提出的有效的前置任务(pretext task),在仅使用少量无标签的RGB-D数据进行预训练的情况下,该模型仍能够具有竞争力的表现。
论文链接:https://arxiv.org/pdf/2101.12482.pdf
工作动机

现有的全监督SOD方法几乎都是采用基于ImageNet预训练的Backbone作为编码器,与解码器(随机初始化)同时进行微调来完成SOD这一下游任务(downstream task)。然而,ImageNet数据量庞大且需要人工标注,对ImageNet的过度依赖会产生许多负面影响。最近几年,自监督学习发展火热,潜力巨大。
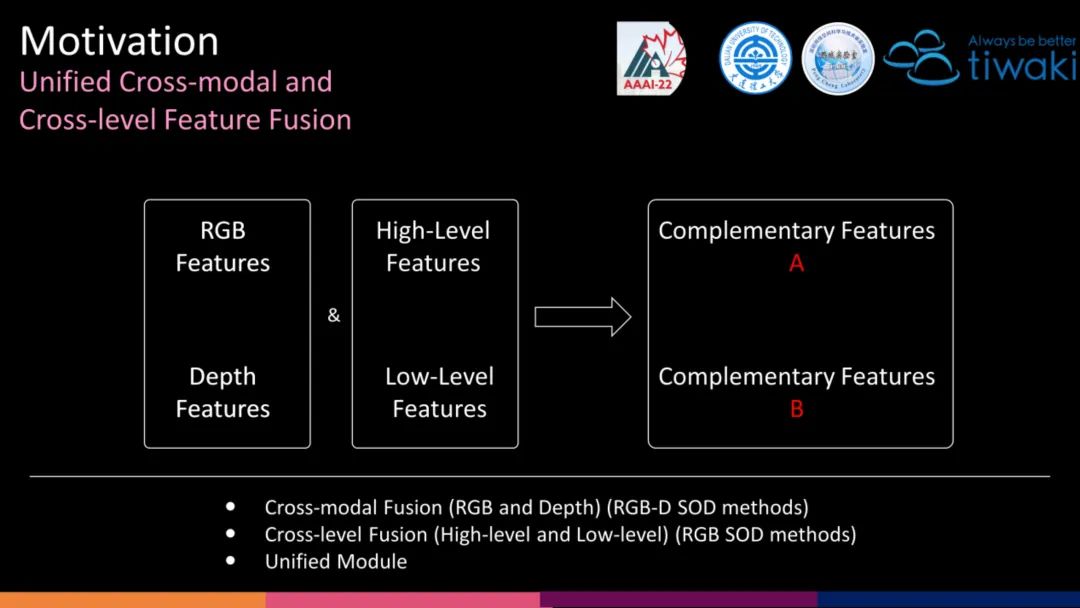
对于 RGB-D SOD 任务本身,从特征融合角度,主要涉及跨模态融合以及跨层级融合。然而,现有的 RGB-D SOD 方法主要关注于跨模态融合,并为之设计了各式各样甚至繁琐的结构,却忽略了跨层级融合的设计。从网络结构角度,Saliency map的生成最终是由解码器完成的,倘若跨层级融合不充分,那么即使跨模态融合相当完美,最终的性能也将会大打折扣。RGB与Depth,High-level 与 Low-level 的融合,其根本属性都是一对具有互补属性关系的特征。因此,从互补属性出发,设计一个简单&有效&通用的融合模块是十分有必要的。
解决方案
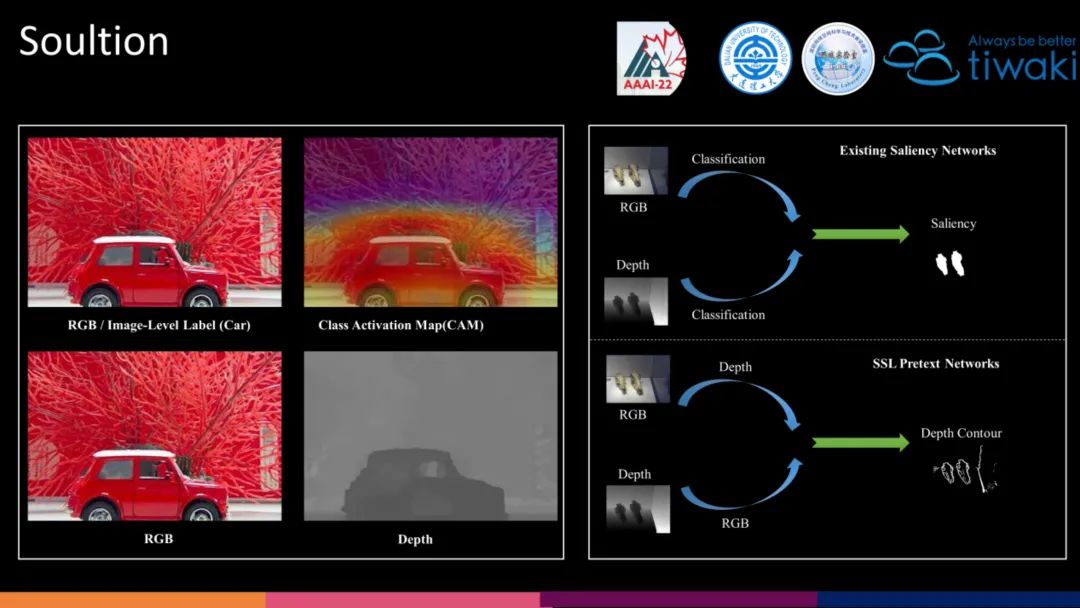
为了制定合理的自监督预训练任务,我们需要详细分析为何采用 ImageNet 预训练可以在 SOD 获得不错的效果。首先,借助分类任务,经过 ImageNet 预训练的网络其通过类激活图(CAM)可以观察到,对于显著性目标往往有着较高的注意力。在现实生活中,显著性目标在深度位置上,相比于背景也往往有着较明显的对比(Depth)。
为此,利用 Depth Estimation 这一任务,能够帮助编码器提升显著性目标的定位能力。然后,我们列举了一个典型的基于 ImageNet 预训练的 RGB-D 抽象结构图。RGB 与 Depth 同时加载相同的 Classification 的预训练权重,解码器联合两个模态特征完成 SOD 这一相同任务。
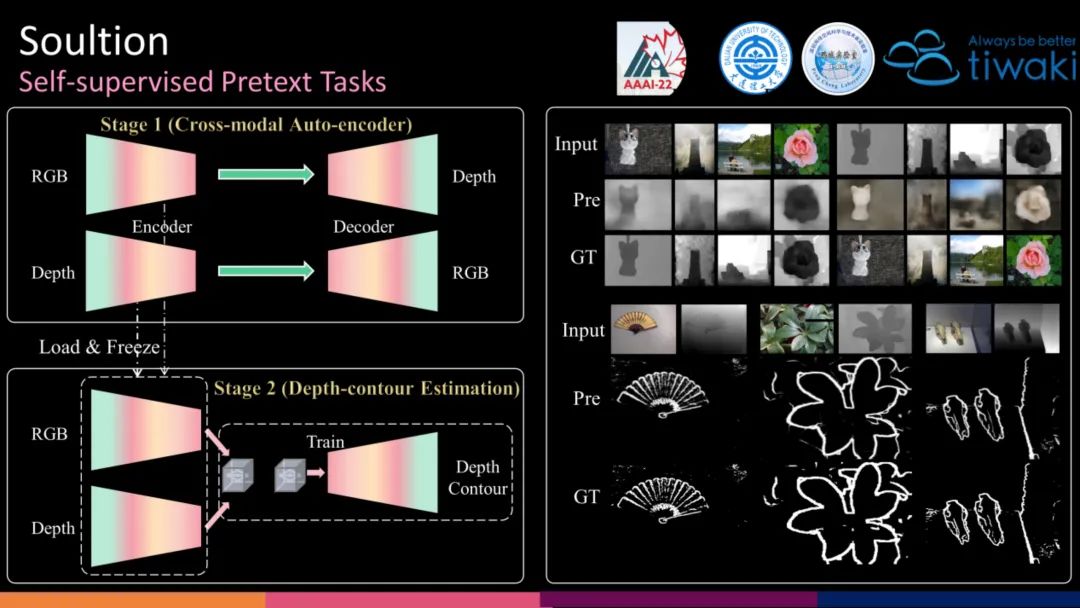
类比以上过程,我们首先提出了第一个Pretext task:跨模态自编码器(Cross-modal Auto-encoder)。两模态间的相互预测,能够缩减其之间的 GAP(主要是指 RGB 模态反映了一个场景的外观,而深度模态体现了不同位置的相对空间距离。显著目标可能外观光滑,但深度不同,反之亦然。为了完整地分割目标,我们必须对齐多模态特征,即缩小两种模态之间的差距。跨模态自编码器可以促进 RGB 和深度编码器相互深度感知,使得每个编码器的特征流具有多模态属性,从而实现对齐)。设计 Depth 预测 RGB 的另一个好处是可以挖掘Depth编码器的潜能(越困难的任务往往越有利于上下文信息的挖掘 [Scaling and benchmarking self-supervised visual representation learning, CVPR 2019]。)
接着,我们按照图中类比设计了第二个Pretext task:深度轮廓估计(Depth-contour Estimation)。 该任务的设计来源于三方面:(1)确定的预测任务为模态间的融合提供了条件。(2)Contour 是下游任务的预测图中的一个基本属性,倘若能够有着精准的 Contour Estimation,会极大的缓解下游任务的压力,即仅需完成 Contour 内外的前景/背景分类。(3)Depth-Contour 相比于 RGB-Contour 的背景干扰更少且关于显著性的信息更多。
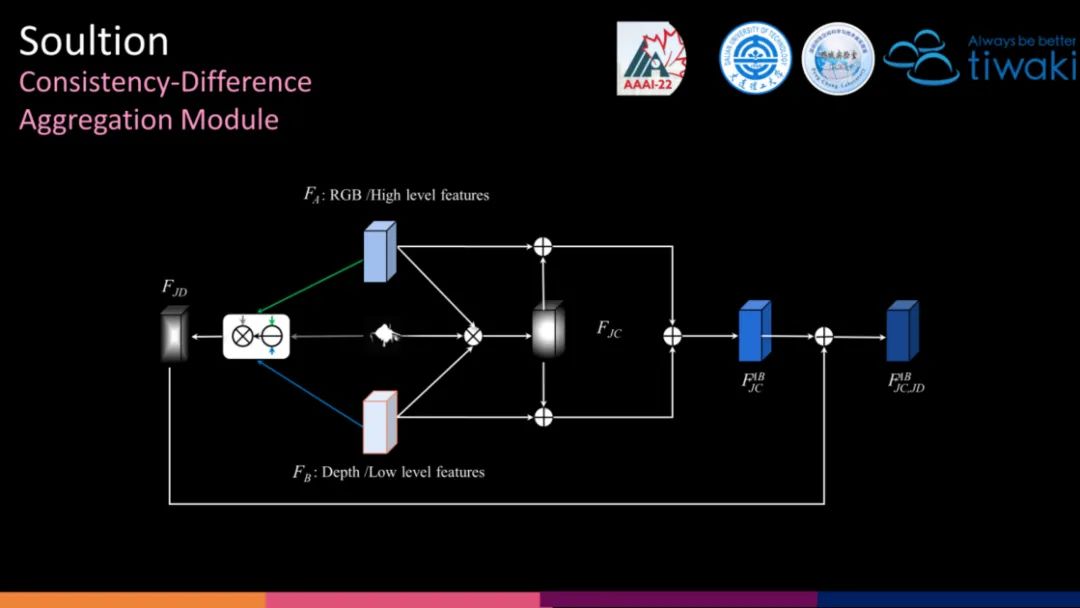
我们提出了一个称为一致性-差异聚合(CDA)的通用模块,以实现跨模态和跨层级的融合。具体来说,对于具有互补关系的两类特征,我们计算它们的联合一致(JC)特征和联合差异(JD)特征。JC更加关注它们的一致性,抑制非显著信息的干扰,而 JD 描绘了它们在显著区域的差异,鼓励跨模态或跨层级对齐。
网络框架
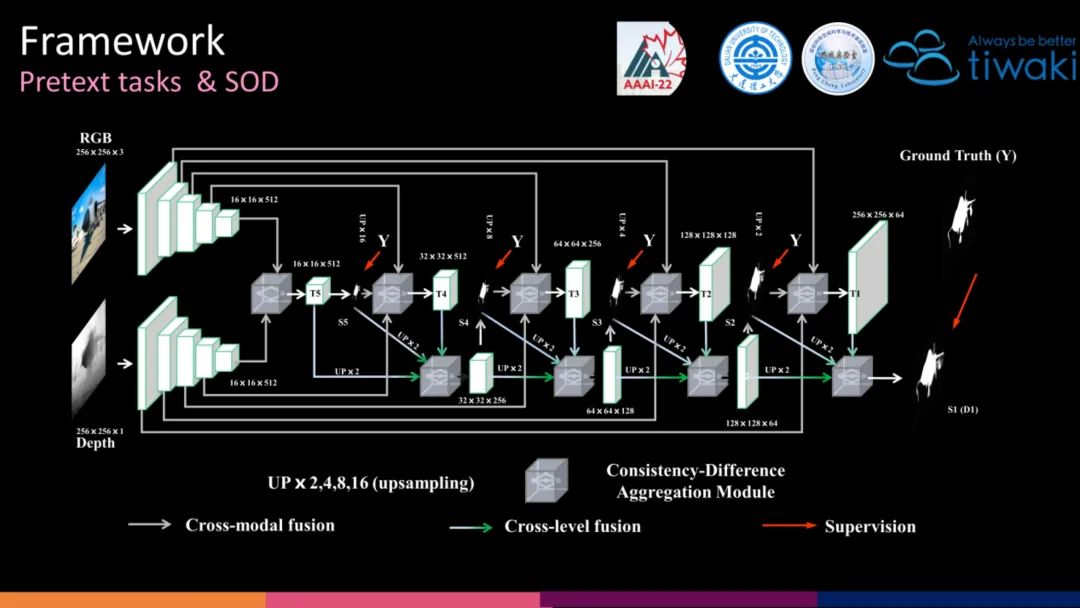
本文的自监督预训练和下游任务均采用的同一个网络框架。因此,能够在预训练结束后,可以无缝地加载预训练权重,更容易训练。
实验结果
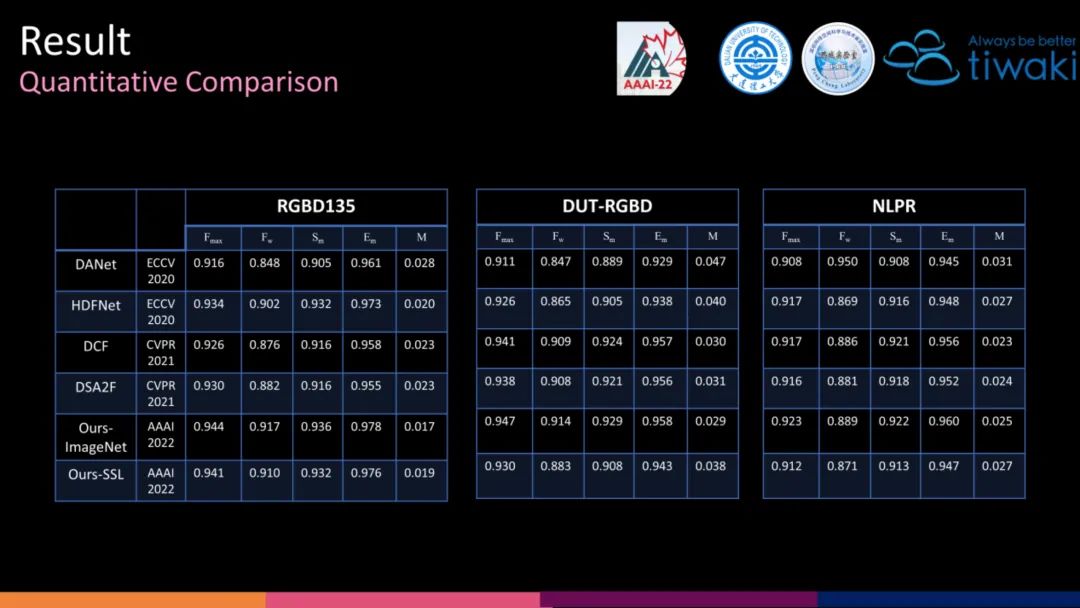
Ours-SSL 虽然没有超过 Ours-ImageNet,但是却可以超越一些其他 ImageNet-based 的方法。

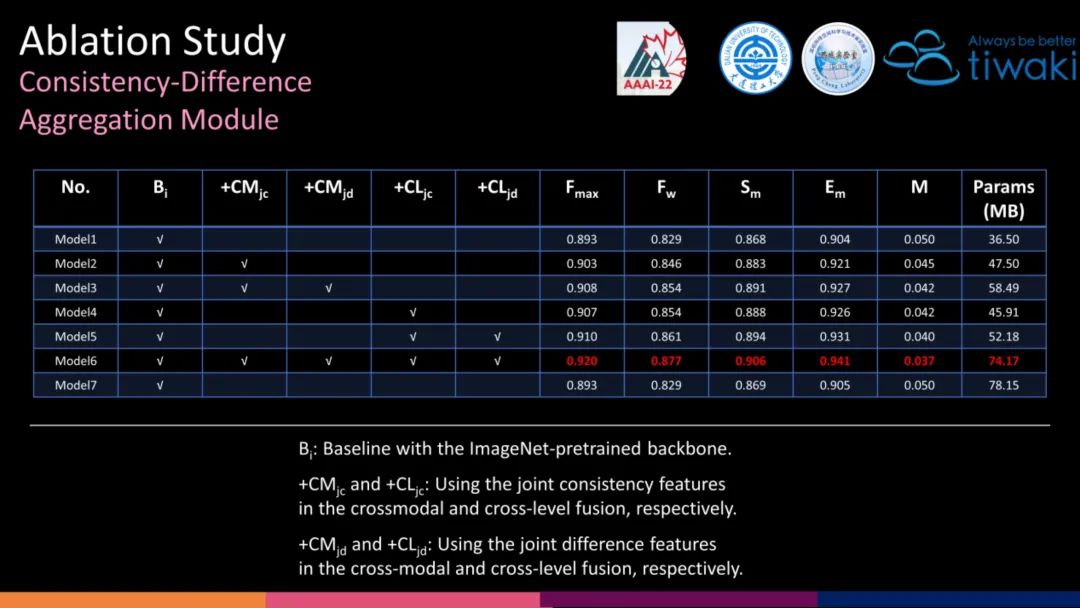
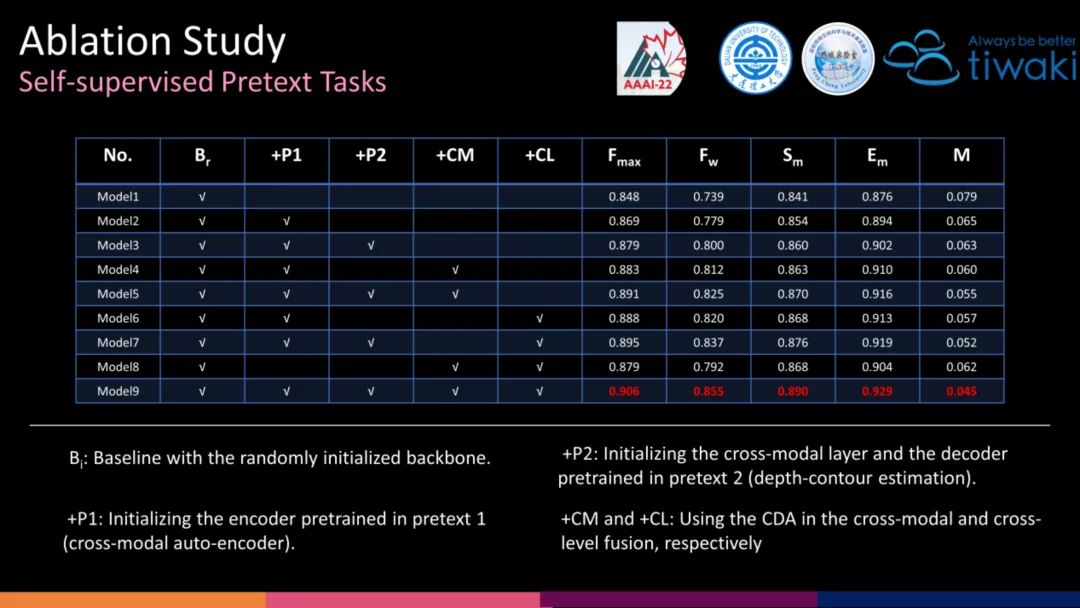
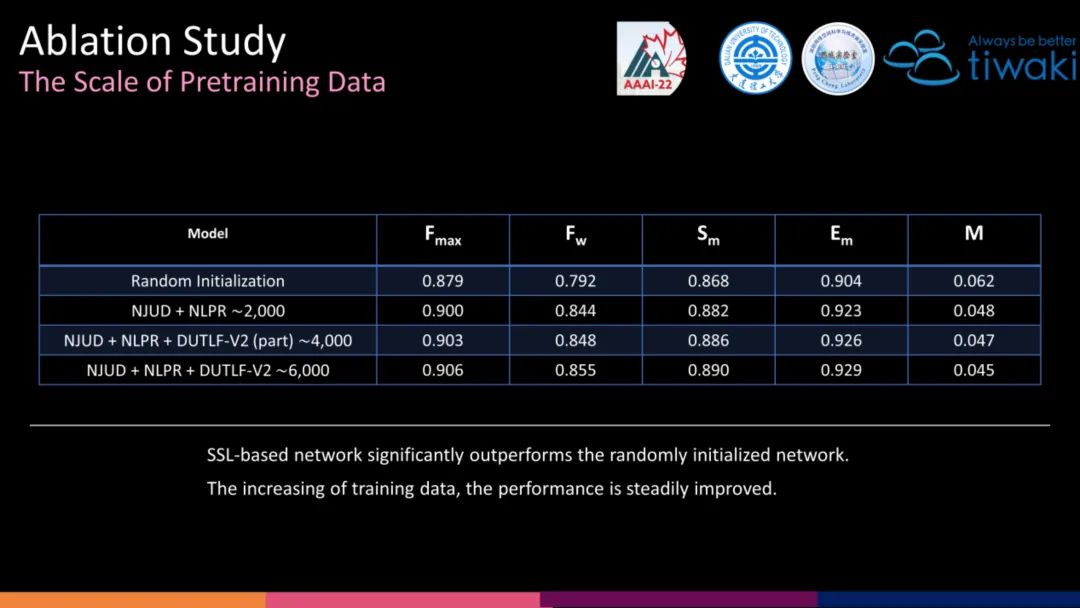
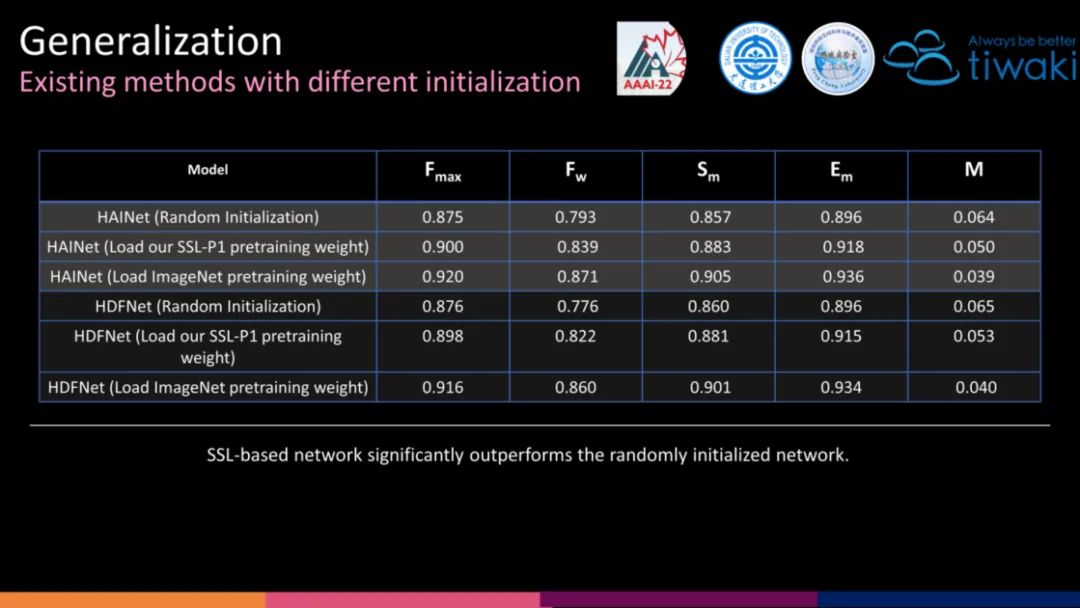
我们设计的第一个前置任务的权重,可以直接作为其他 RGB-D SOD 的编码器初始化,可以看到相比于随机初始化,具有明显的优势。

我们给出一些本文的潜在/未来工作:
(1)对解码器进行自监督预训练。以往的方法忽视了对解码器预训练,仅是简单的使用随机初始化解码器权重(潜在工作)。
(2)半自监督。半监督与自监督交织在一起(未来工作)。
(3)虽然,本文设计的自监督模型与 ImageNet-based 模型之间的性能仍有差距,但是当前仅使用了少于 0.5% ImageNet 规模的数据量,增大预训练规模,潜力巨大(未来工作)。

总结
-
本文是第一个引入自监督预训练到SOD任务中的工作。
-
本文是第一个旨在统一跨模态与跨层级融合的RGB-D SOD工作。
代码后续开源(预计AAAI 2022线上开会结束后),请关注:https://github.com/Xiaoqi-Zhao-DLUT/SSLSOD
更多相关工作,请关注作者个人主页:https://xiaoqi-zhao-dlut.github.io
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

Lart
知乎:人民艺术家
CSDN:有为少年
大连理工大学在读博士
研究领域:主要方向为图像分割,但多从事于二值图像分割的研究。也会关注其他领域,例如分类和检测等方向的发展。
作品精选



