CVPR 2022 | Point-BERT: 基于掩码建模的点云自注意力模型预训练

极市导读
Point-BERT设计了一种新的点云Transformers预训练方法,通过构建MPM任务,帮助标准Transformers同时学习低层结构信息与高层语义信息,并为标准Transformers在三维物体相关任务带来了很大的提升。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

在这里和大家分享一下我们被CVPR 2022录用的工作“Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling”
单位:清华大学, 北京智源研究院, 北京大学
项目主页:https://point-bert.ivg-research.xyz/
代码仓库:https://github.com/lulutang0608/Point-BERT
论文下载地址:https://arxiv.org/abs/2111.14819
简介:
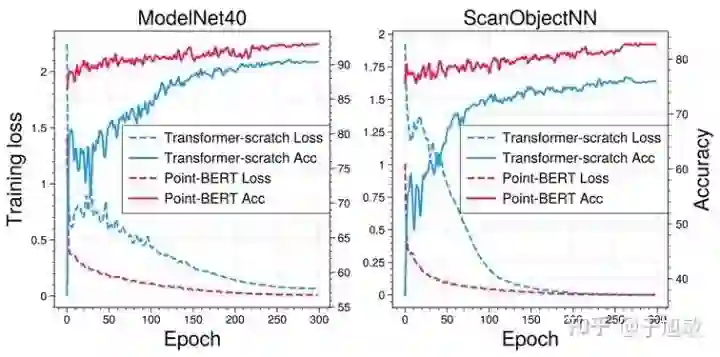
Transformers在NLP领域中取得了统治级别的表现,从2020年Vision Transformers提出后,Transformers也展现了其在2D视觉任务中的巨大潜力。基于这种统一而简单的网络结构,不少学者也致力于基于这种只包含自注意力机制的Transformers去搭建Unified Model,去同时处理来自语言、图像等不同域的数据(只需要更换不同的Input embedding layer)。但在3D视觉任务中,这种标准Transformers的直接运用却表现不佳,见下图(蓝线),所以现有的Unified Model都暂时没有将3D点云考虑为一种输入模态。在3D任务上的欠佳表现主要是由于标准Transformers中不包含Inductive Bias(归纳偏置),极大地增加了训练难度并提高了对标注数据数量的需求,而3D领域缺乏了如2D领域的ImageNet这样的大规模数据集,这使得不少相关研究通过设计包含丰富几何后验的模块(如kNN等)来减轻标准Transformers对数据的依赖,但这样针对于3D数据特殊的设计,可能使得3D点云Transformers缺少标准Transformers的通用性。
而我们的论文中说明通过利用无标签数据设计自监督训练,即使不改变标准Transformers的原始设计,依然可以在3D任务上达到很好效果,包括在虚拟模型数据集ModelNet与真实Scan数据集ScanObjectNN的物体识别任务,见下图(红线)。
方法:
BERT是NLP领域中目前最成功的Transformers预训练方法之一,它通过构建掩码重建(Masked Language Modeling)等任务来进行自监督训练。如果可以将点云表达为如同语言一样的一组离散“词汇”,我们就可以很自然的借鉴BERT在NLP任务中的成功经验。
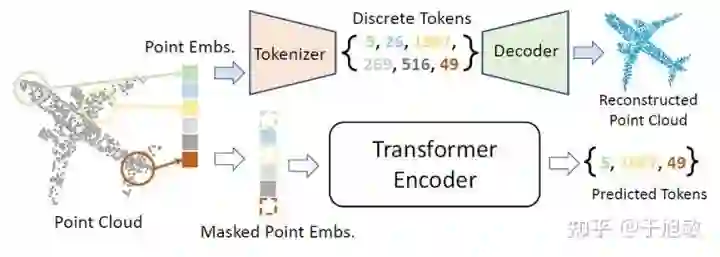
于是我们提出首先将点云转化为由“局部结构”构成的集合。在这一步中,我们通过最远点采样与kNN去将点云分成N个局部点云,这些局部点云包含了细节的局部几何信息与结构。为了将这些局部结构编码成为如语言中的“词汇”,我们设计了Tokenizer去进行点云到“词汇”的转换,并在Tokenizer之后接上Decoder构成Discrete VAE (dVAE),通过进行局部点云重建任务的方式来训练该Tokenizer。具体而言,我们将一个点云分为N个局部点云(sub-clouds),对每一个局部点云,我们通过dVAE的Tokenizer将其编码成为一个离散编码(Discrete Token,如“5”),并利用dVAE的Decoder将该离散编码翻译成重建局部点云,通过监督编码重建损失来进行优化。最终,我们可以将任何点云表示为一组离散编码的集合,其中每一个离散编码都对应了一个明确的局部结构(如“5”代表飞机头部的结构,“49”代表了机尾的结构)。举个例子,如下图,我们可以认为,一个飞机被简单、抽象地表达为了{5,26,1967,269,516,49}。这与单词和句子的关系相似,所以我们可以构建属于点云的Masked Point Modeling(MPM)任务,引导Transformers通过可见的点云局部结构,去预测被掩盖掉(masked)的局部结构。
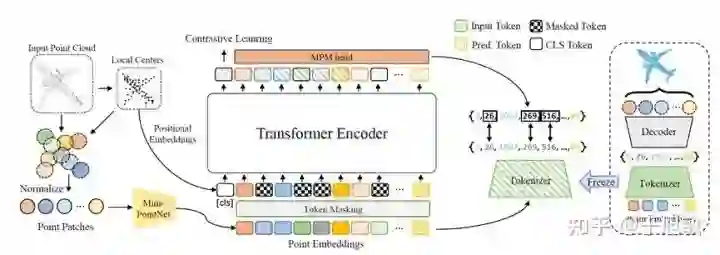
我们提出的MPM任务如下图所示。利用训练好的dVAE,我们可以将任意3D物体表达为一个“词汇”集合,这将作为MPM任务的预测目标。Transformers以加过随机掩码(mask)的sub-clouds为输入,通过自注意力机制与前馈神经网络和一个为该任务设计的MPM head,对被掩盖部位的“词汇”进行预测,并与完整点云的离散编码进行对比。该过程可以引导Transformers学习不同局部之间的关系,并利用局部关系进行被掩盖部位的预测。为了同时保证Transformers对语义信息的学习,我们也加入了Class Token,来输出点云的全局特征,并加入对比学习损失进行监督。为了增强样本的多样性,我们设计了一种Point Patch Mixing的方法生成更多的训练样本。
最后我们将预训练的Transformers在多个下游任务上进行微调(finetune),可以提升该模型在这些任务上的性能表现。
实验结果:
我们在分类问题和分割问题上进行了实验:
-
对于分类问题,我们将MPM预训练中的MPM head更换为MLP,并进行分类训练。 -
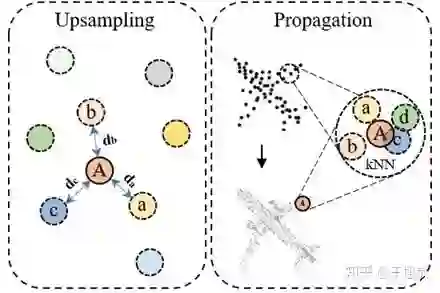
对于分割问题,我们设计了适合于标准Transformers的segmentation head,主要部分如下图所示,进行组件分割(Part Segmentation)训练。
我们在三维物体分类,少样本学习,迁移学习与组件分割上进行实验,我们主要结果如下:
-
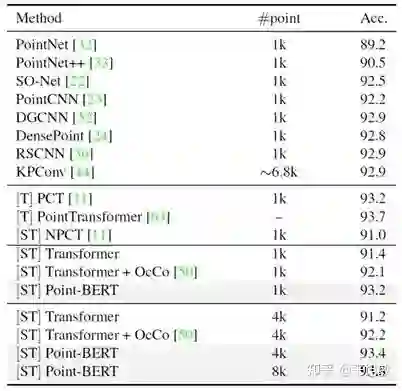
在点云物体分类任务上, Point-BERT采用最少的人为先验,超越了目前主流的点云学习模型;
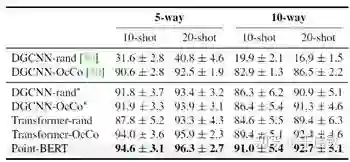
2. Point-BERT学习到的特征可以很好地迁移至新的任务与新的数据域;
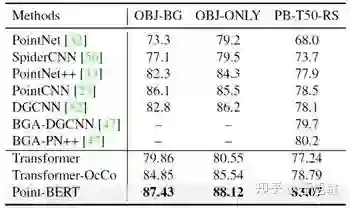

3. 由可视化结果可以看出,Point-BERT即使在点云缺失比例很高的情况下也能准确地预测出缺失部分的点云结构。

Point-BERT经过MPM与训练后的重建结果。通过Transformer进行缺失离散编码预测后,利用预训练的Decoder进行物体补全
结论
Point-BERT设计了一种新的点云Transformers预训练方法,通过构建MPM任务,帮助标准Transformers同时学习低层结构信息与高层语义信息,并为标准Transformers在三维物体相关任务带来了很大的提升。更多细节请参考我们的文章与开源代码。
参考文献
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805, 2018 -
Hangbo Bao, Li Dong, and FuruWei. Beit: Bert pre-training of image transformers. arXiv:2106.08254, 2021. -
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:2010.11929, 2020 -
Hanchen Wang, Qi Liu, Xiangyu Yue, Joan Lasenby, and Matt J Kusner. Unsupervised point cloud pre-training via occlusion completion. In ICCV, 2021.
公众号后台回复“数据集”获取小目标检测数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



