集成3400 条commit!PyTorch 1.10 正式版发布,能帮你选batch size的框架

新智元报道
新智元报道
来源:GitHub
编辑:LRS
【新智元导读】历时四个多月,PyTorch 1.10终于发布了正式版,这次的更新内容性能更强,对安卓的支持更多,对开发人员也更友好了!
集成了 CUDA Graphs API以减少调用CUDA时CPU开销;
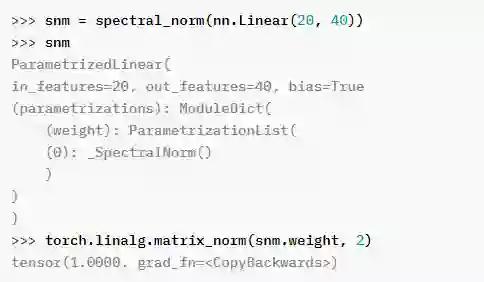
FX、torch.special和nn.ModuleParametrization等几个前端API已从测试版(beta)变为稳定版(stable);
除GPU外,JIT Compiler中对自动融合(automatic fusion)的支持目前也支持CPU了;
Android NNAPI支持在测试版中已经可以用了。
前端API



分布式训练
Remote 模块允许用户远程操作和使用本地模块一样,其中 RPC 对用户是透明的;
DDP通信 hook允许用户覆盖DDP如何在进程中同步梯度;
ZeroredUndanyOptimizer可与DistributedDataParallel 一起使用,以减小每个过程优化器状态的size。通过这种稳定版本,它现在还可以处理不均匀的输入到不同的数据并行woker。
性能优化工具
增强型内存视图:这有助于用户更好地了解内存使用,主要通过在程序运行的各个点显示活动内存分配来帮助开发人员避免内存错误;
增强型内核视图:附加列显示网格和块大小以及每个线程共享内存使用和寄存器的情况,这些工具可以给开发者推荐batch size的变化、TensorCore、内存缩减技术等;
分布式训练:Gloo现在支持分布式训练工作;
TensorCore:该工具显示Tensor Core(TC)的使用,并为数据科学家和框架开发人员提供建议;
NVTX:对NVTX markers的支持是从旧版autograd profiler移植过来的;
支持移动设备分析:PyTorch profiler现在与TorchScript 、移动后端能够更好的集成,支持移动工作负载的跟踪收集。
移动端 PyTorch

参考资料:
https://github.com/pytorch/pytorch/releases/tag/v1.10.0
https://pytorch.org/blog/pytorch-1.10-released/





