社区分享 | Spark 玩转 TensorFlow 2.0
本文来自社区投稿与征集,作者梁云,转自:https://github.com/lyhue1991/eat_tensorflow2_in_30_days
tf.keras 接口训练的线性模型为例进行演示。在本例基础上稍作修改则可以用 Spark 调用训练好的各种复杂的神经网络模型进行分布式模型推断。
tf.Module 提供的便捷的封装功能,我们可以将训练好的模型导出成模型文件并在 Spark 上分布式调用执行。
这无疑为我们的工程应用提供了巨大的想象空间。
Spark-Scala 调用 TensorFlow 模型概述
在 Spark(Scala) 中调用 TensorFlow 模型进行预测需要完成以下几个步骤:
准备 protobuf 模型文件
创建 Spark-Scala 项目,在项目中添加 Java 版本的 TensorFlow 对应的 jar 包依赖
在 Spark-Scala 项目中 driver 端加载 TensorFlow 模型调试成功
在 Spark-Scala) 项目中通过 RDD 在 executor 上加载 TensorFlow 模型调试成功
在 Spark-Scala 项目中通过 DataFrame 在 executor 上加载 TensorFlow 模型调试成功
** 建议参考本项目中的《Appendix I: Load TensorFlow model in Spark.ipynb》文档。
一 准备 protobuf 模型文件
我们使用 tf.keras 训练一个简单的线性回归模型,并保存成 protobuf 文件。
import tensorflow as tf
from tensorflow.keras import models,layers,optimizers
## 样本数量
n = 800
## 生成测试用数据集
X = tf.random.uniform([n,2],minval=-10,maxval=10)
w0 = tf.constant([[2.0],[-1.0]])
b0 = tf.constant(3.0)
Y = X@w0 + b0 + tf.random.normal([n,1],mean = 0.0,stddev= 2.0) # @表示矩阵乘法,增加正态扰动
## 建立模型
tf.keras.backend.clear_session()
inputs = layers.Input(shape = (2,),name ="inputs") #设置输入名字为inputs
outputs = layers.Dense(1, name = "outputs")(inputs) #设置输出名字为outputs
linear = models.Model(inputs = inputs,outputs = outputs)
linear.summary()
## 使用fit方法进行训练
linear.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])
linear.fit(X,Y,batch_size = 8,epochs = 100)
tf.print("w = ",linear.layers[1].kernel)
tf.print("b = ",linear.layers[1].bias)
## 将模型保存成pb格式文件
export_path = "./data/linear_model/"
version = "1" #后续可以通过版本号进行模型版本迭代与管理
linear.save(export_path+version, save_format="tf")
!ls {export_path+version}
# 查看模型文件相关信息
!sav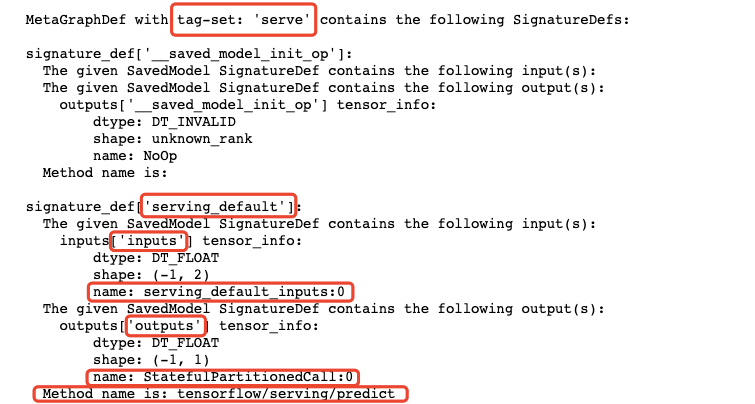
二 添加 TensorFlow for java 项目依赖
<!-- https://mvnrepository.com/artifact/org.tensorflow/tensorflow -->
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.15.0</version>
</dependency>https://mvnrepository.com/artifact/org.tensorflow/tensorflow/1.15.0
三 在 Driver 端加载 TensorFlow 模型
我们的示范代码在 Jupyter Notebook 中进行演示,需要安装 toree 以支持 Spark-Scala。
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
//注:load函数的第二个参数一般都是“serve”,可以从模型文件相关信息中找到
val bundle = tf.SavedModelBundle
.load("/Users/liangyun/CodeFiles/eat_tensorflow2_in_30_days/data/linear_model/1","serve")
//注:在java版本的tensorflow中还是类似tensorflow1.0中静态计算图的模式,需要建立Session, 指定feed的数据和fetch的结果, 然后 run.
//注:如果有多个数据需要喂入,可以连续用用多个feed方法
//注:输入必须是float类型
val sess = bundle.session()
val x = tf.Tensor.create(Array(Array(1.0f,2.0f),Array(2.0f,3.0f)))
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
if(x != null) x.close()
if(y != null) y.close()
if(sess != null) sess.close()
if(bundle != null) bundle.close()
result输出如下:
Array(Array(3.019596), Array(3.9878292))四 通过 RDD 加载 TensorFlow 模型
下面我们通过广播机制将 Driver 端加载的 TensorFlow 模型传递到各个 executor 上,并在 executor 上分布式地调用模型进行推断。
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
val spark = SparkSession
.builder()
.appName("TfRDD")
.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
//在Driver端加载模型
val bundle = tf.SavedModelBundle
.load("/Users/liangyun/CodeFiles/master_tensorflow2_in_20_hours/data/linear_model/1","serve")
//利用广播将模型发送到excutor上
val broads = sc.broadcast(bundle)
//构造数据集
val rdd_data = sc.makeRDD(List(Array(1.0f,2.0f),Array(3.0f,5.0f),Array(6.0f,7.0f),Array(8.0f,3.0f)))
//通过mapPartitions调用模型进行批量推断
val rdd_result = rdd_data.mapPartitions(iter => {
val arr = iter.toArray
val model = broads.value
val sess = model.session()
val x = tf.Tensor.create(arr)
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
//将预测结果拷贝到相同shape的Float类型的Array中
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
result.iterator
})
rdd_result.take(5)
bundle.close
输出如下:
Array(Array(3.019596), Array(3.9264367), Array(7.8607616), Array(15.974984))五 通过 DataFrame 加载 TensorFlow 模型
主要思路是将推断方法注册成为一个 SparkSQL 函数。
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
object TfDataFrame extends Serializable{
def main(args:Array[String]):Unit = {
val spark = SparkSession
.builder()
.appName("TfDataFrame")
.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
val bundle = tf.SavedModelBundle
.load("/Users/liangyun/CodeFiles/master_tensorflow2_in_20_hours/data/linear_model/1","serve")
val broads = sc.broadcast(bundle)
//构造预测函数,并将其注册成sparkSQL的udf
val tfpredict = (features:WrappedArray[Float]) => {
val bund = broads.value
val sess = bund.session()
val x = tf.Tensor.create(Array(features.toArray))
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
val y_pred = result(0)(0)
y_pred
}
spark.udf.register("tfpredict",tfpredict)
//构造DataFrame数据集,将features放到一列中
val dfdata = sc.parallelize(List(Array(1.0f,2.0f),Array(3.0f,5.0f),Array(7.0f,8.0f))).toDF("features")
dfdata.show
//调用sparkSQL预测函数,增加一个新的列作为y_preds
val dfresult = dfdata.selectExpr("features","tfpredict(features) as y_preds")
dfresult.show
bundle.close
}
}
TfDataFrame.main(Array())
+----------+
| features|
+----------+
|[1.0, 2.0]|
|[3.0, 5.0]|
|[7.0, 8.0]|
+----------+
+----------+---------+
| features| y_preds|
+----------+---------+
|[1.0, 2.0]| 3.019596|
|[3.0, 5.0]|3.9264367|
|[7.0, 8.0]| 8.828995|
+----------+---------+
以上我们分别在 Spark 的 RDD 数据结构和 DataFrame 数据结构上实现了调用一个 tf.keras 实现的线性回归模型进行分布式模型推断。
tf.Module 提供的便捷的封装功能,我们可以将训练好的任意机器学习模型导出成模型文件并在 Spark 上分布式调用执行。
这无疑为我们的工程应用提供了巨大的想象空间。
关于作者
感谢作者:梁云,知乎专栏 Python 与算法之美主理人,热爱机器学习和大数据挖掘,喜欢吃鱼和爬山 😇。
本篇文章节选自《Eat TensorFlow2 in 30 days》,更多精彩内容,欢迎关注项目 Github地址。
Eat tensorflow2 in 30 days
https://github.com/lyhue1991/eat_tensorflow2_in_30_days