KubeNest - 运维特征(Trait)配置化开发框架设计及实践

一 背景
-
不必要重建:在一次应用发布过程中可能涉及多个trait,这些trait由Operator实现都去修改workload,每次修改都会造成pod重建,实际生产过程中,pod重建应该尽量避免
-
开发成本高:新开发一个trait需要通过新建一个operator应用来实现,虽然可以利用kubebuidler开发框架简化开发,但是仍然需要几天才能完成,且需要开发者了解Operaotr的开发机制,对于开发者有一定语言能力要求
-
运维成本高:trait数量过多,一旦涉及到公共逻辑代码修改(如status增加字段)时,需修改n个trait工程,同时需要升级m个集群,带来的维护成本将是o(n^2)的 -
资源浪费:每个trait是一个单独的应用,而应用部署时最低配置都是1核1G且多副本,然而内部执行的是简单转换逻辑仅用100M左右,因此这些trait实际上带来大量资源浪费
-
代码不规范:在trait共建方面,KubeNest仅规定了输入输出标准,用户可定制化trait开发,这也很容易因为代码不规范造成bug
-
不一致问题:面对相同的输入,在Operator代码逻辑不当可能会带来输出数据顺序不同,而该不一致问题很容易导致pod重建,如toleration顺序变化会导致pod重建,而这是无效的重建
二 旧的架构
1 Trait Operator化
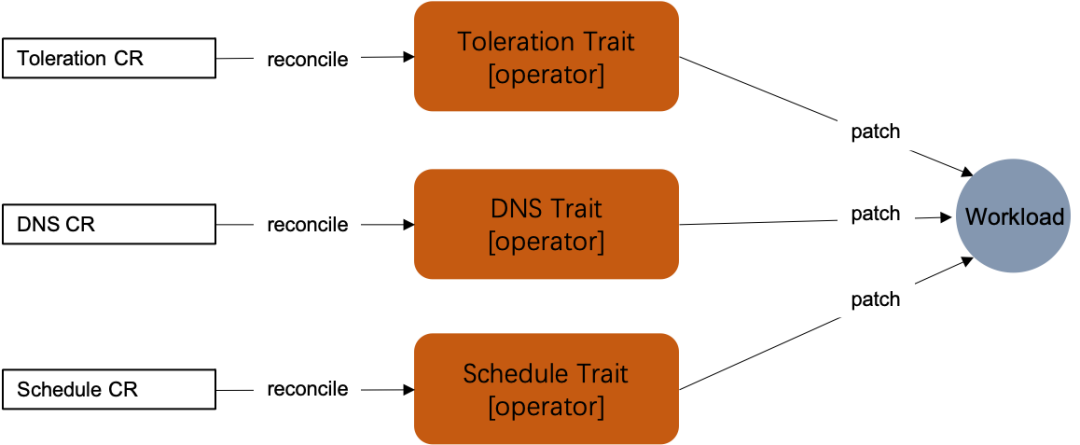
应用数据:应用相关的数据,用户无需关心但在Operator逻辑处理所需要的,存在metadata的annatation数据中,如workload的apiVersion和kind,在apply时需要。
-
toleration trait CR (用户选择底层资源)
apiVersion: apps.kubeone.alibaba-inc.com/v1kind: TolerationInjectormetadata: annotations: kubeone.ali/workload-api-version: apps.kruise.io/v1alpha1 # 应用数据 kubeone.ali/workload-kind: StatefulSet # 应用数据 ...#用户数据spec: parameters: sigma.ali/is-ecs: "true" sigma.ali/resource-pool: "example"
该CR表示用户希望将pod布置在打上污点标sigma.ali/is-ecs: "true"和sigma.ali/resource-pool: "example"的node上。
toleration trait产生的YAML片段
toleration trait根据trait CR中用户输入转化成YAML片段,然后将该YAML片段直接patch到workload上,完成该运维操作。
# YAML片段apiVersion: apps.kruise.io/v1alpha1kind: StatefulSetmetadata:name: sts-examplenamespace: ns-examplespec:template:spec:tolerations:- effect: NoSchedulekey: sigma.ali/resource-pooloperator: Equalvalue: example- effect: NoSchedulekey: sigma.ali/is-ecsoperator: Equalvalue: 'true'
2 风险点
-
顺序导致重建
在原生的statefulset和Open kruise statefulset中,YAML内容的顺序不同也会导致重启。因此,在旧的架构中,trait除了要关注输入参数的值,还需关注参数的顺序问题。当参数顺序不同时,trait产生的YAML片段顺序也会不同,当patch到workload上时,就会引发workload重启,从而可能带来pod重建的故障风险。 -
多次apply导致重建
一次发布过程中可能有多个trait施加运维操作,此时会有多次apply workload而导致pod多次重建。从安全生产角度考虑,用户希望pod重建次数越少越好。
三 trait配置化开发框架
1 Trait开发框架
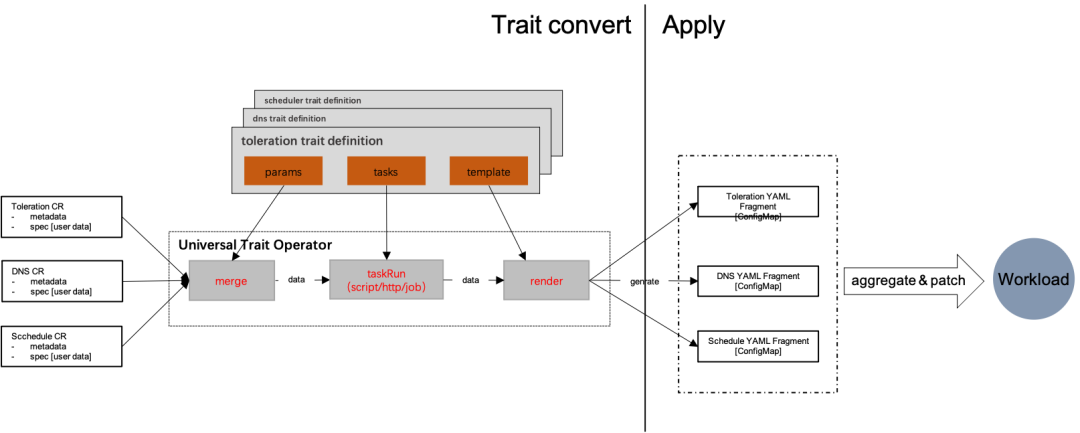
Trait convert:trait实现借助于Universal Operator通过数据+配置模版=YAML片段的方式生成YAML Fragment,该YAML Fragment会通过ConfigMap存储。
Apply:会聚合一次发布过程中产生的所有YAML Fragment,然后做一次patch到应用workload,从而避免了多次重建。
-
trait CR:用户提交的运维动作,其中包括应用数据(存在metadata)和用户数据(存在spec),可以参考toleration trait CR的示例
-
trait definition:去operator,将运维逻辑配置化,本质是一个YAML
-
name:该条数据的标示,在template中,通过name来渲染数据
-
keyRef:数据来源,值为json path的形式,会根据keyRef从spec中读取数据
-
default:默认值,如果从spec中找不到数据则用默认值
-
required:表明此属性是否必须
-
description:对该属性的描述
-
params:在模版中定义了该运维逻辑所需要的用户数据和每条用户数据的基本属性,每个数据属性有name、default、keyRef、description、required -
tasks:对于配置化的切面拓展,90%的trait是可以直接转换的,对于不能转换需要添加复杂逻辑的,trait开发者可以通过tasks来自定义,task会在生成YAML片段前执行,目前支持的task类型有shell、job、http -
template:以go template为基础的trait模版,结合数据render成最终的YAML片段 -
Universal Trait Controller:核心的转换控制器,结合trait CR和trait definiton生成YAML片段
2 流程介绍
-
用户数据处理(Merge)。trait CR中有用户数据(user data)和应用数据(app data),params中规定了参数要求,merge过程将用户数据和params结合输出,记为merged data -
定制化逻辑处理(TaskRun)。tasks是配置化方案的拓展,是用户自定义的逻辑,包括多种shell、http、job、func等多种方式。此过程会将merged data和app data作为task的输入参数,顺序执行多个task,tasks执行完会产生新的输出数据,记为output data -
数据渲染(Render)。app data、merged data和output data作为终态数据,将这些数据与template通过go template技术渲染得到YAML片段,YAML暂存在Fragment(configMap)中
-
OrderId:每次发布的orderId -
AppName:应用name -
WorkloadApiVersion:workload的apiVersion -
WorkloadKind:workload的Kind -
Namespace:应用的namespace -
CoreNamespace:kubeNest的namespace,值为ark-system -
Replicas:副本数
3 示例
apiVersion: core.oam.dev/v1alpha1kind: TraitDefinitionmetadata: name: etcd-secret-injector namespace: ns-examplespec: ... params: - name: END_POINT type: "string" description: "this is a description" default: "https://127.0.0.1" required: false tasks: - name: etcd-http kind: http # shell / job / http / func spec: script: '{{.Params.END_POINT}}/etcd' outputs: - name: TOKEN default: "default token" - name: KEY default: "default key" template: | apiVersion: v1 kind: secret metadata: name: {{ .AppName }} namespace: {{ .Namespace }} data: token: {{ .Outputs.TOKEN | b64dec }} key: {{ .Outputs.KEY | b64dec}}
四 方案对比
| 对比开发 | Operator开发 | 配置化开发 |
|---|---|---|
开发成本 |
需掌握Operator开发知识 |
仅需知道YAML编写知识 |
开发周期 |
前后需几天时间 |
去Operator,仅编写YAML,半个小时左右 |
运维成本 |
每个trait需单独部署与稳定性保障 |
当成功地将大部分trait收敛成YAML配置,仅需部署维护一个Universal trait Operator,大大节省了运维成本 |
资源配置 |
每个trait都是单独的Operator应用,最低配置1核1G,且需多副本部署 |
无资源消耗 |
标准化 |
仅输入输出标准化 |
不仅输入输出标准化,而且使开发过程标准化,能很好的避免因代码不规范引起的bug |
拓展性 |
无 |
多类型task支持用户自定义逻辑,有很好的切面拓展能力 |
稳定性 |
一次部署容易引发多次pod重建 |
避免多次重建 |
资源配置化开发去Operator,提供了通用trait的开发输入输出标准化管理,开发者仅需配置YAML,极大缩短了开发周期,同时将trait 应用收敛,降低运维成本和资源消耗,同时避免了多次重建保障了生产的稳定性。
五 总结
-
降本提效:该方案去operator应用能够有效的收敛资源,同时YAML配置化开发大大的提高了开发效率和降低了运维(部署、升级)成本;
-
数据一致性:模版化保证了数据是面向终态的,使得开发无需关注数据顺序,保障数据一致性,消除乱序带来重启的风险;
-
促进开源:该方案目前已经经过生产级的验证,得到很好的反响,并输出到KubeVela中,使得用户自定义开发trait更为简单,促进KubeVela开源生态的建设。
Spring Cloud微服务架构设计与开发实战
本次课程涵盖最新版本的Spring Cloud 微服务架构体系, 微服务架构模式、算法与典型场景、框架、优缺点,Spring Cloud 2020的重大变化、扩展Netflix、Spring Cloud Alibaba阿里巴巴体系,Dubbo等架构选型对比,淘宝微服务架构案例。
重点讲解:服务治理、注册发现、熔断限流、网关代理、链路追踪、安全监控等核心问题,循序渐进,概念为辅、实战为主,涵盖经典面试题。让您成为合格的微服务架构师。点击阅读原文查看详情!