ECCV2020 | Unsupervised Batch Normalization
计算机视觉研究院专栏
作者:Edison_G
BN的基本思想:因为深层神经网络在做非线性变换前的激活输入值(就是x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。

BN的理解,其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。
但是,今天我们要来说说被ECCV2020收录的一个技术《Unsupervised Batch Normalization》。
Batch Normalization是神经网络中一种广泛使用的工具,用于提高训练的泛化和收敛性。然而,在小型数据集上,由于难以获得无偏的batch统计数据,因此不能有效地应用。在某些情况下,即使只有一个小的标记数据集可用,也有来自相同分布的更大的未标记数据集。 作者提出使用这些未标记的样本来计算Batch Normalization统计量,称之为无监督批归一化(UBN)。
作者表明,使用未标记的样本进行batch统计计算可以减少统计的偏差,以及利用data manifold进行正则化。 UBN易于实现,计算成本低,可应用于各种问题。 最后实验使用未标记样本和UBN,在KITTI数据集上的准确率提高了6%以上。
我还是简单说一说这个技术的背景,BN的主要原理我就不详细描述了,我们之前也有分享给大家,有兴趣的同学可以点击下面链接阅读学习。
在过去的十年中,大规模的标记数据已经推动了许多计算机视觉问题的进展。对标记数据的依赖是许多视觉问题的基本瓶颈,因为获取Ground-Truth注释可能非常昂贵(例如用于语义分割的像素注释)或需要专门的设备和受控环境(例如深度估计,三维姿态估计,光流等)。

在这些情况下,研究往往采用不同的策略。一种常见的方法是从零开始对“realistic”合成数据的深层网络进行预训练,然后对可用的标记数据进行最终调整。 这种策略通常被最先进的光流方法使用。 虽然这种方法减轻了过拟合,但它需要创建这样现实的数据,并且不提供利用未标记数据可用性的机会。虽然数据可能很难和昂贵的标签,有时额外的未标记数据样本(例如来自相同分布的图像)可以很容易地免费获得。

另一种流行的技术是迁移学习,其中大型模型是在自监督任务上预训练的,然后对可用的少量标记数据进行微调。 虽然预训练阶段有助于优化起点,但微调阶段仍然有可能与少量标记数据过拟合。 另一种有效的策略是半监督学习,其目的是同时从标记数据和未标记数据中学习。 这种方法是成功的,但通常需要对每个视觉问题进行具体的适应。
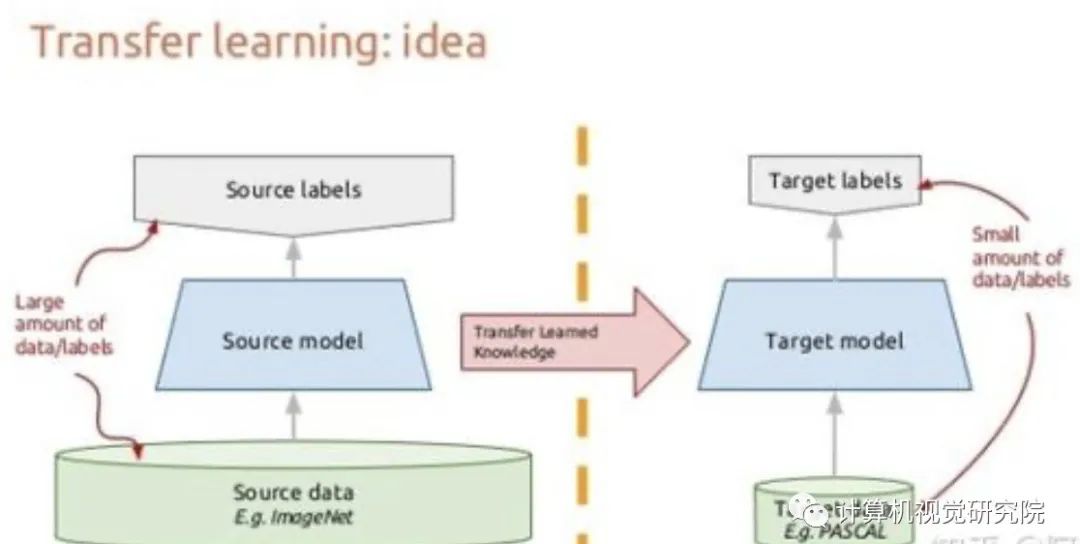
所以,作者提出了一种通用的方法,不需要适应任何新的视觉问题,利用额外的未标记数据,不需要微调。特别是采用了广泛使用的BN技术来使用未标记的数据。
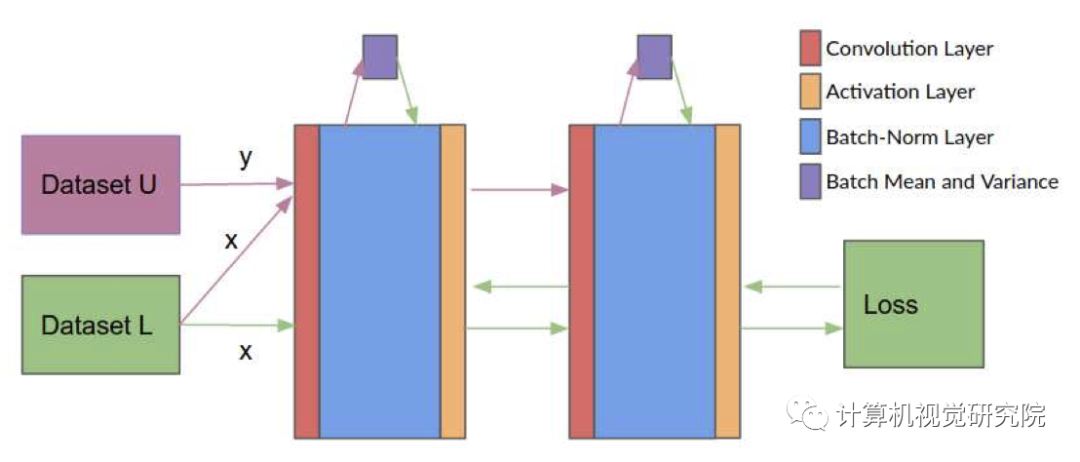
UBN的基础是首先更新批统计数据而不是权重。给定来自标记数据集L的批处理x∈L和来自未标记数据集U的批处理y∈U。第一步构建一个联合批处理n={x,y},并向前传递以更新normalization统计数据;第二步在使用x时进行forward-backward传递,并在前面的步骤中计算更新批归一化统计量。
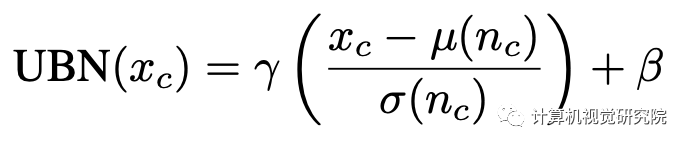

UBN(左) BN(右)
我们从上图中看到,用BN进行监督训练,很好地学习了标记样本的分布,从而学习了准确的决策边界。然而,这些决策边界并不反映真实的数据分布。相反,使用UBN,网络学习将其决策边界与data manifold对齐,并通过使用未标记样本的批处理统计来学习,在标记样本之间进行插值。
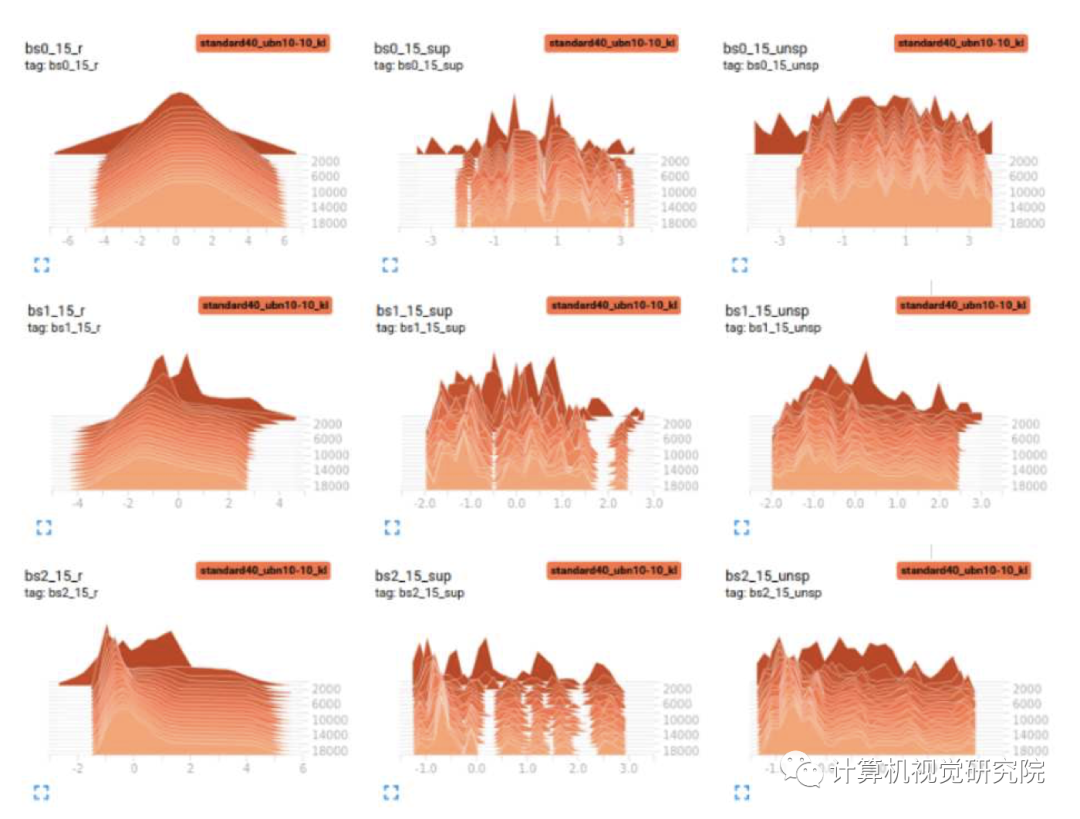
我们从特征映射的直方图中观察到,未标记和标记样本的分布之间存在着巨大的差异。只计算与标记样本有关的批处理统计数据将导致归一化值中大量的偏差。我们假设,在数据有限的问题中,获得正确的batch统计的困难将是导致深度学习方法失败的重要原因。 新提出的方法通过计算相对于更好地反映真实数据分布的更多样本的归一化值来缓解这个问题。

我们通过使用相同的输入进行多个预测,同时更新批统计,可视化了通过改变批统计而引起的不确定性。这给了我们一个预测的分布,我们可以从中计算我们预测的标准差。我们观察到,网络的不确定性遵循data manifold,并与不正确的预测和没有数据样本的区域很好地对齐。
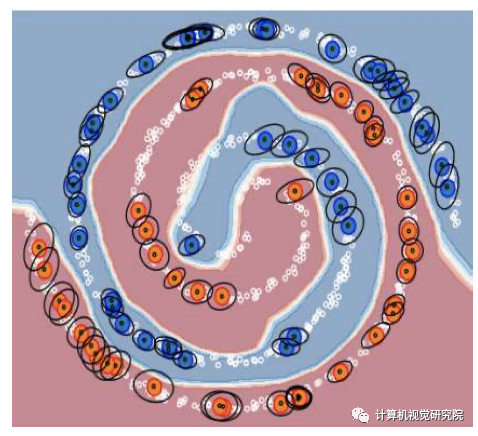
我们通过使用标记样本对网络进行前向传播来分析改变批统计的诱发噪声,保存网络预测,更新批统计数据,并在特征空间中使用反向传播更新输入,直到预测与早期批统计相同为止。这给出了与更改批统计数据具有相同效果的起点分布。我们观察到,除了决策边界太接近data manifold的区域外,增强遵循data manifold,在这种情况下,它将决策边界从标记的样本推开。因此,BN层应用依赖于data manifold的隐式增强。
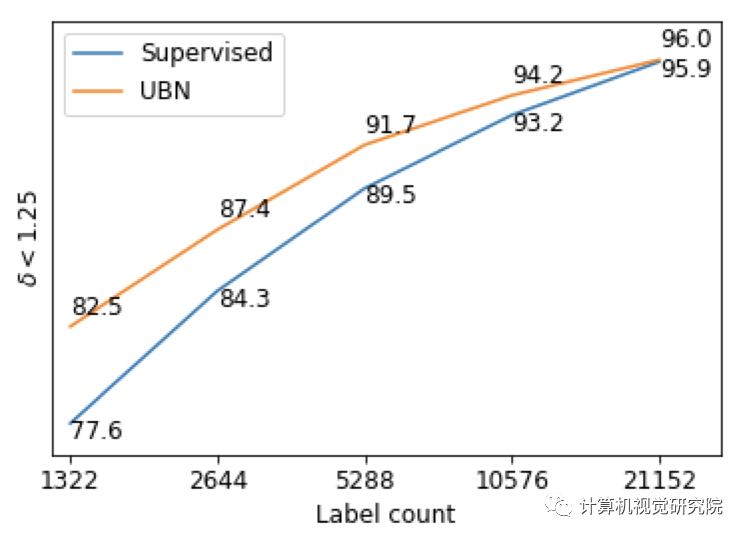
UBN shows a larger improvement as the number of la- beled images decreases
随着标记样本的数量收缩,UBN表现出越来越大的提升,并优于监督的BN训练。如果标记图像的数量接近未标记图像,这两种方法实际上变得相同,这使得新提出的方法更适合于标签有限的问题。
✄------------------------------------------------

扫码关注我们
公众号 : 计算机视觉研究院



