案例分享 | 华泰证券利用 TensorFlow 构建金融舆情系统
文 / 张汝宸 朱峰 朱德伟

背景介绍
美国“华尔街日报”最吸引读者专栏之一是 “Abreast of the Market News”。在该专栏中,读者每天可以跟踪市场指数、参阅相关股票分析师前瞻预测进行合理的市场投资。新闻里涉及的不同公司、行业等主体的舆情倾向也直接反映了投资者对其在股市表现的不同期望。在每天海量新闻、突发事件充斥着各大新闻媒体门户网站之时,如何快速、高效和准确地捕捉新闻主体相关的市场情绪,也是现在金融研究热点问题。
华泰证券是一家致力于利用科技助力金融业务的行业头部券商。我们基于全网金融网站的实时新闻数据,借助 TensorFlow 和 BERT 模型,训练并部署了一套舆情分析系统(如图 1 所示)。系统实时追踪热点话题,解析新闻关联的公司、行业和事件,给出情绪标签和异动榜单,同时还可以针对特定事件,进行回测,挖掘事件与标的涨跌的相关性。系统在交易、资管、投研、风控等多个业务场景均已落地并发挥重要作用。
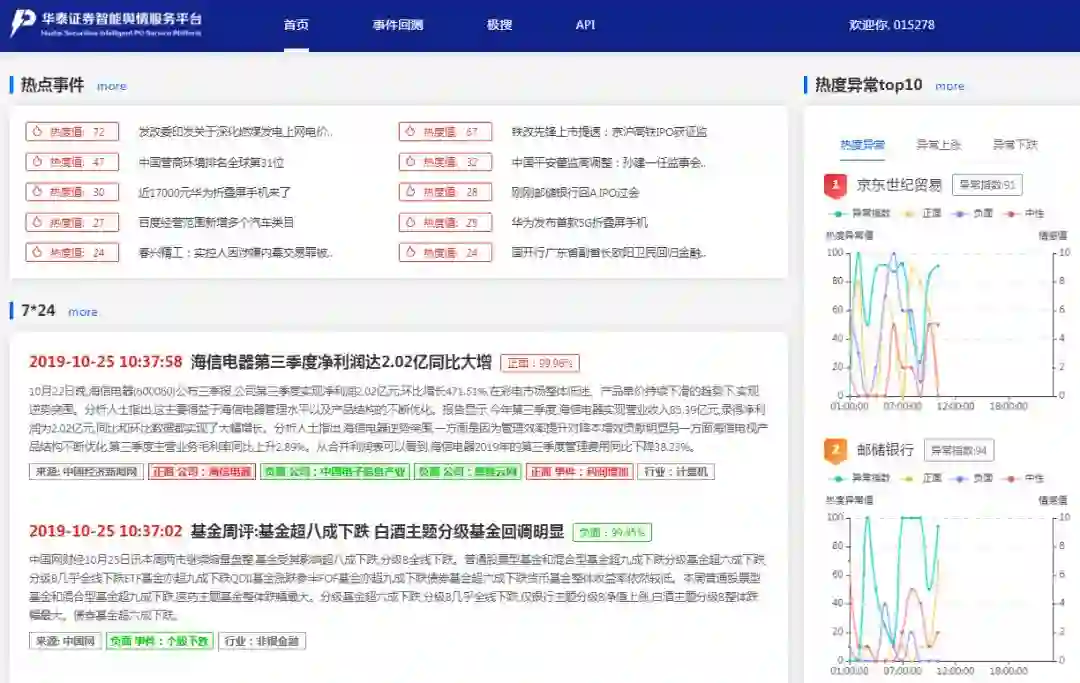
图 1 - 华泰证券智能舆情系统
数据准备
2.1 实时数据
2.2 训练数据

数据标签为正负中三分类,标注标准主要依据两点:
-
通过词语或者词组来进行正负标注 词语标注主要关注情感词(上涨、下跌等)、否定词(未能,暂未等)、程度词(大幅,明显等)和转折词(但是,然而等);词组标注主要关注双重否定(亏损减少)和前后转折(速度快但不稳定)。
-
根据金融逻辑来进行标注
一些行业的金融逻辑和直观判断会有出入,需要仔细甄别。例如:去产能。去产能直观来看代表产能下降,偏负面,但在化工、钢铁等行业中,去产能意味着供给减少,往往会导致产品价格上升,是一个正面信号。
2.3 易错数据分类
表 2 - 易错数据分类

算法设计
3.1 算法结构
如图 2 所示,整个系统的算法结构从数据清洗开始,需要去除一些特殊符号并规范格式。清洗过后,首先要对文本进行金融非金融的分类,不是金融类别的文本会被过滤掉。留下的金融文本需要再次进行分类,以区分公告非公告。其中公告文本可以直接走公告事件体系,直接给出对应的金融逻辑情感标签。而非公告类文本,即常规的金融新闻,会进入主体和篇章情感模型中进行分类。最后,基于长期积累形成的一个针对宏观、行业、个股的投资事件体系,如果检测触发了其中的一些重要事件,则会根据这些重要事件的金融逻辑情感标签对模型结果进行修正。
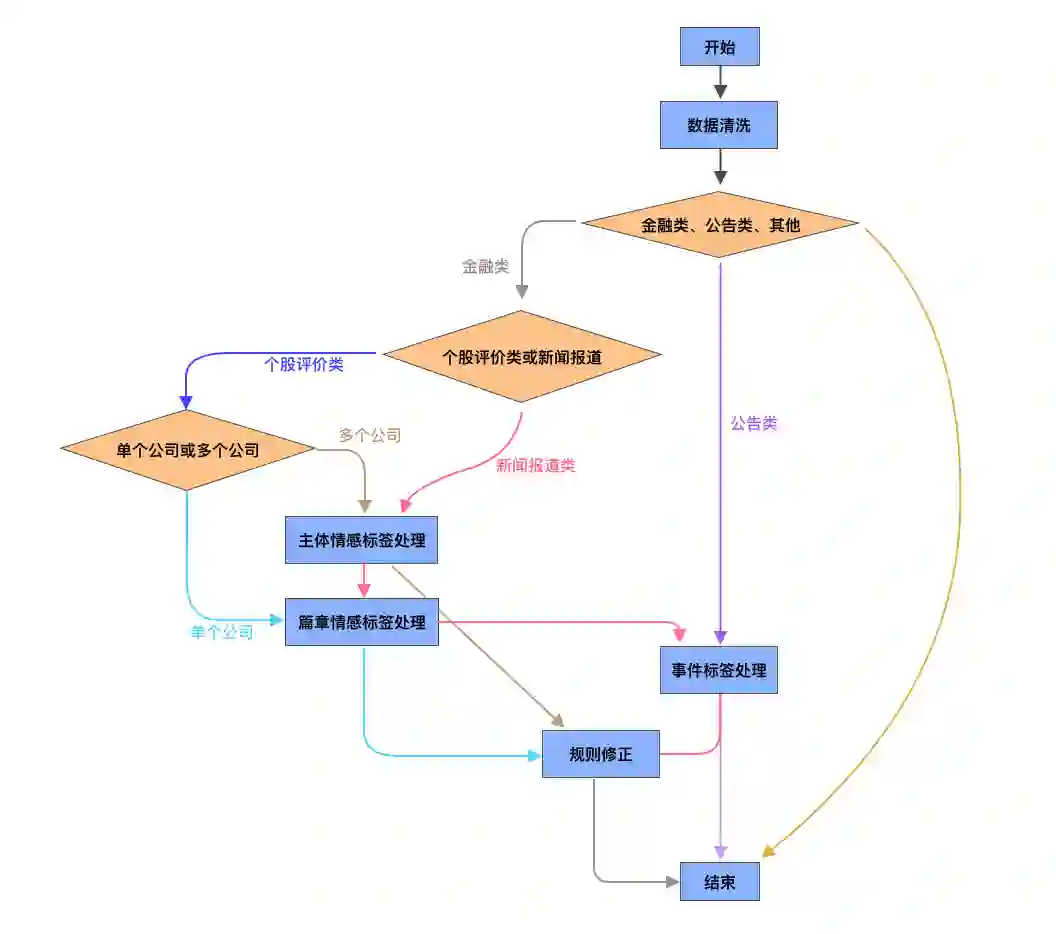
图 2 - 舆情系统算法结构
3.2 核心模型
以主体情感分类为例,我们主要关注模型的正负误判率,对于此项指标,如图 3 所示,在两次质检数据上,BERT 的表现均更优。
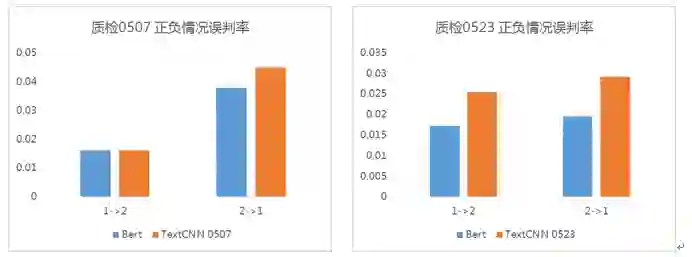
图 3 - BERT 与 TextCNN 正负误判率对比
进一步的,针对上文提及的主体情感的易错数据类别,我们对模型进行了特别设计,以适应数据集自身特点。例如,对于高占比的多主体问题,如果只是单纯利用 BERT 进行情感分类,则不能有效学习同一句话中不同实体之间的情感差别。为此,设计模型如图 4 所示:
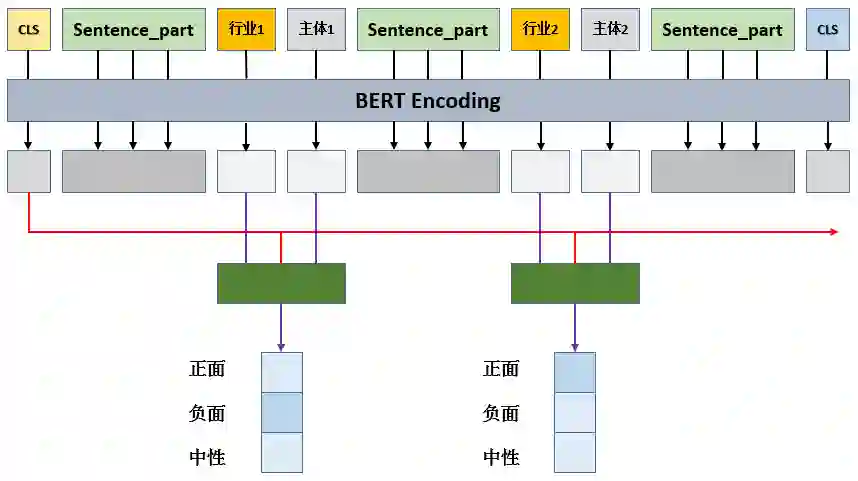
图 4 - 主体情感模型结构(针对多主体问题优化)
首先,在 BERT 输入端,在关注的主体前加入了主体所属的行业信息,目的是学习不同行业间差异化的金融逻辑。不同的行业类别 Token 可以用 BERT 预训练中未使用的符号代替。其次,在输出层之前,不仅融合了主体和所属行业的向量编码,还融合了整个句子开始处的向量编码,其目的是在引入主体和行业上下文信息的同时,也引入句子整体的信息,以更好地区分同句不同主体之间的情感差异。最后,多主体三分类分别求 Loss,损失函数相加,联合训练。这样的模型结构设计,较为有效地解决了多主体问题,模型 F1 - Score 提升了约 2.3 %。
算法改进
4.1 金融领域预训练
4.2 数据均衡与增强
4.3 增加多主体数据
服务部署
由于应用了 BERT 模型,我们的服务都是部署在 GPU 之上的。但目前阶段,TensorFlow Serving 并不支持多 GPU 的自动负载均衡。尽管它可以获取所有的 GPU,并可以在每个 GPU 上都创建 Session,但在一个服务进程里,所有的计算只会在一个 GPU 上完成。因此我们对每个 GPU 都启动一个 Docker 服务进程,在上层使用了 ZeroMQ 进行负载均衡,这样就实现了多 GPU 的模型服务,对文本输入序列较长的篇章情感模型,响应速度提升了约 5 倍。
舆情因子
研究舆情因子,有助于我们把握市场看涨或看跌的情绪,做出正确的走势判断。舆情是“舆论情况”的简称,是指在一定的社会空间内,围绕社会事件的发生、发展和变化,民众的情绪反应。目前百度,新浪等公司都上线了基于网络资讯的分析平台,华泰也自研了金融舆情因子接口,下面我们就基于自研的情感指数对行情进行分析。
首先我们按照表 3 对训练数据的输入输出进行建模:
表 3 - 按给定时间粒度获取

通过构造不同的特征值,我们对行情和舆情数据进行多因子模型的特征提取,如表 4 中的情感衍生特征和表 5 中的价格衍生特征:
表 4 - 情感衍生特征
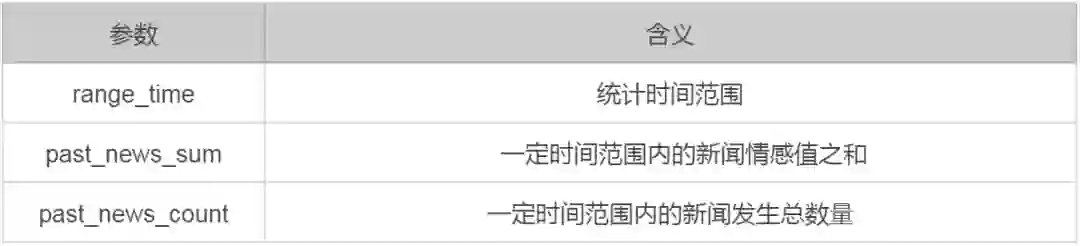
表 5 - 价格衍生特征
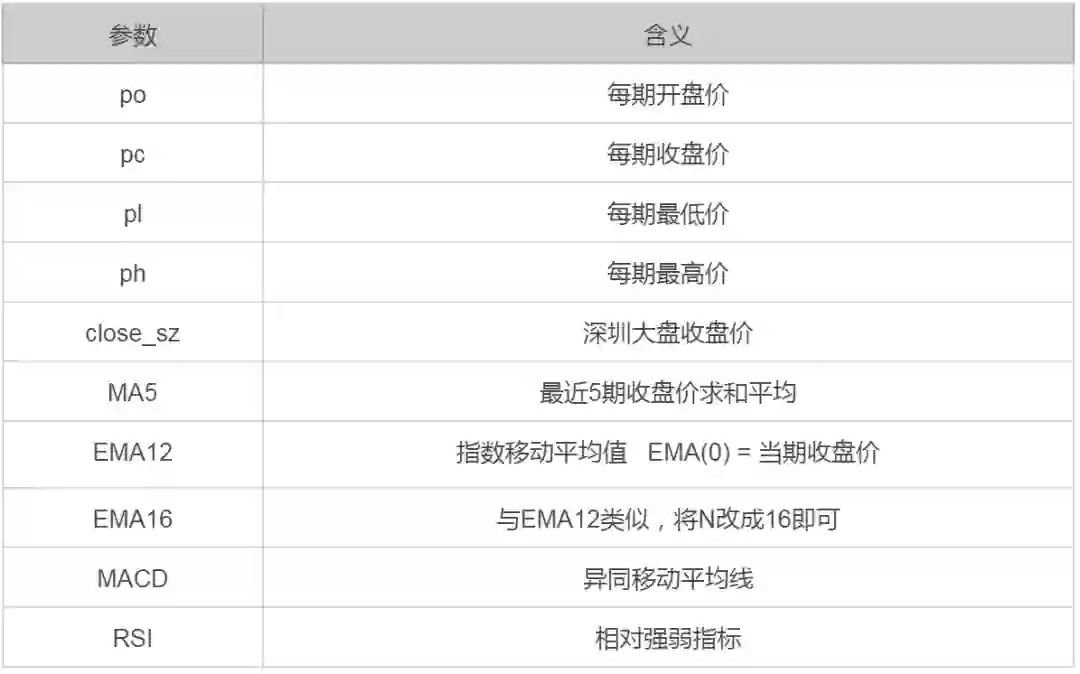
以博兴股份(600083.XSHG)为例,我们取时间粒度 frequency = 30 - 230 分钟,训练:预测 = 3 : 1,使用 XGboost 进行三分类模型训练,大多数时间粒度的测试集准确率可以达到 0.5 以上。
特征方面,采用(120 + 180 + 240 分钟情感窗口)的全特征训练出来的模型最好。特征重要性方面, past_news_count 和 past_news_sum 特征在情感指标中贡献较高,下图是前述实验的特征重要程度图,其他实验也基本呈现相似的趋势。可以看到情感指标中贡献度较高的特征为当天负面新闻数,以及之前 1 - 5 天正面新闻数,说明了情感指数(因子)在涨跌预测模型中的重要性。
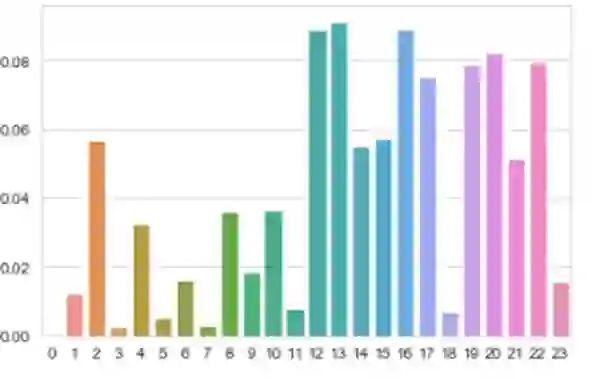
图 5 - 舆情因子贡献程度
1 features = ['neutral_count','positive_count','negtive_count', 'bf_neu_sum','bf_pos_sum','bf_neg_sum','bt_0','bt_1','bt_2','bt_3','bt_4','bt_5','bt_6','bt_7','bt_8','bt_9','bt_10','bt_11','bt_12','bt_13','bt_14','bt_15','bt_16','bt_17']总结与展望
本文介绍了华泰证券使用 TensorFlow 和 BERT 构建情感模型、搭建舆情系统的方法,通过一系列的数据处理、训练、分析和迭代,基于 TensorFlow Serving,在 GPU 上部署了高效的模型算法。同时探究了构建舆情因子的可行性。在市场越发趋于有效,技术面套利机会空间缩小的情况下,将新闻消息与对应个股的利好利空程度进行定量研究,并辅以计算机量化,将成为投资利器。
致谢
最后还要感谢华泰证券信息技术部数据科学研发中心的同事张超,在文章撰写过程中提供的帮助和建议。
参考文献
[3] Wei, Jason W., and Kai Zou. "Eda: Easy data augmentation techniques for boosting performance on text classification tasks." arXiv preprint arXiv:1901.11196, 2019.
想加入案例分享?点击 “阅读原文”,填写相关信息,我们会尽快与你联系。
更多相关案例: