深度学习在金融文本情感分类中的应用

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
随着互联网的飞速发展,以 Web2.0 思想和技术为基础的社群媒体聚集了大量的网络用户,社群媒体不再是单纯的新闻发布平台,而是允许用户创建内容,发表观点和交流意见的平台。越来越多的人喜欢将自己的观点、看法和意见发布到社群平台上。例如国外的 Facebook,Twitter,国内的微薄,知乎及金融领域的平台:天天基金网,雪球网等。
这些主观性的文本可以是用户对某个产品或服务的评论,或者是公众对某个新闻事件或国家政策的观点等。潜在的消费者在购买某个产品或服务时获取相关的评论可提供决策参考,政府部门可以浏览公众对新闻事件或国家政策的看法来了解舆情,金融证券公司也可以根据股民的情绪,对股市的反应等信息形成投资指标。这些主观性的文本每天以指数级的速度增长,仅靠人工进行分析需要消耗大量的人力和时间。
因此,采用计算机来自动地分析文本表达的情感,成为学术界目前的研究的一个热点。
随着计算机硬件的升级,基于大数据的深度学习算法的突破,AI 热潮再一次来临,当前 AI 已经在与各行各业相结合,持续为健康医疗,交通出行,安防监控,金融等领域赋能,其中 AI+ 金融是 AI 技术最有潜力的一个应用场景,由此也衍生出了“金融科技”这一概念。自然语言处理(NLP)作为 AI 技术的一个重要分支,在金融领域的文本挖掘中扮演着越来越重要的角色,如:光大证券的“中文云”文本挖掘系统与金融量化领域的结合使用,银河证券基于研究报告内容对证券市场热点主题概念及情绪的监控,广发证券基于互联网信息挖掘的量化投资策略等,无不是自然语言处理在背后作为技术支撑。
情感分析作为自然语言处理的一个方向,也在越来越多的领域发挥着重要的作用,如:口碑分析,市场情绪分析,舆情监控等。百度的 AI 平台更是将情感倾向分析作为热门服务。华泰作为券商行业的引领者,自然要在 AI 的潮流下,成为金融科技的引领者,事实上也确实在一直探索着 AI 技术在实际业务场景下的应用。情感分析目前已经应用到诸多产品之中,比如:金融文本数据分析平台利用情感分析技术,分析挖掘各大财经网站、股票论坛中不同的的立场不同的思维方式的人群的不同观点与情绪,分析挖掘反应投资者情绪的网络舆情,形成指标,为投资者提供参考。华泰的 AI 技术平台也通过提供情感分析接口为其他产品提供技术支持。所以,对情感分析算法持续研究与创新,将其与金融业务深度结合,有着深远的意义。
结合真实业务场景需求,本文研究了多种情感分析算法,并对每一种的模型算法做了评估测试。
在这一部分主要介绍 4 种不同的情感分类方法:分别为基于机器学习、CNN_word_level、CNN_character_level、RNN 的情感分类。其中 CNN_word_level 和 CNN_character_level 都是基于 CNN 的模型,不过具体流程不同,为了区分,分别命名为 CNN_word_level 和 CNN_character_level。
基于机器学习的情感分类模型主要分为 3 个步骤:文本预处理,文本向量化,训练分类器。
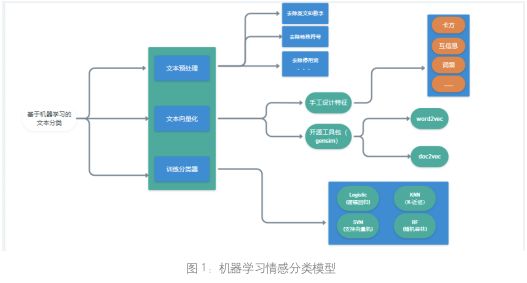
文本预处理:本文收集的财经新闻语料一般都是爬虫获得的,语料中有很多的噪声信息, 比如 HTML 标签、英文字母,特殊字符等,需要对原始语料做清洗工作,去噪、分词、去除停用词等,至此文本预处理步骤完成。
文本向量化:文本向量化也称为特征提取或者特征工程。特征提取的方法可以分为两类: 手工设计和训练获得。手工设计的特征通常有:文档频率(DF)、信息增益(IG)、互信息(MI)、卡方统计(CHI)、TF-IDF 等。这些方法依赖于人工的设计,受人为因素的影响,推广能力差,在某一领域表现优秀的特征不一定在其他领域也表现优秀。所以在选择通过语料训练得到的特征。实验中使用谷歌开源的工具包 gensim.word2vec 来提取文本的特征,使得文本向量化。
训练分类器:机器学习中常用的分类器包括 k 近邻算法(KNN),逻辑回归(Logistics)、随机森林 (RF)、支持向量机(SVM)等。在实验中对比各种分类器后,发现 SVM 的表现更好。
深度学习模型在计算机视觉和语音识别两大领域已经取得了显著的结果,在自然语言处理领域,基于深度学习模型的研究工作已经涉及了通过神经语言模型学习词向量的表示和在训练好的词向量上组合特征用于分类任务。卷积神经网络(CNN)利用可以提取局部特征的卷积层,起初设计用来处理计算机视觉问题的 CNN 模型已经逐渐被证明在 NLP 领域同样有效,并且在语义分析,搜索查询检索,句子模型,和其他 NLP 任务上已经取得了相当好的结果。本文参考论文 Convolutional Neural Network For Sentence Classification 提出的算法进行实验。流程图如图 3 所示。
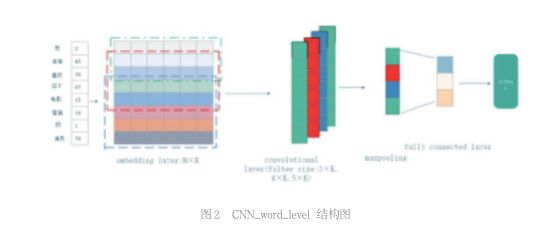
词表构建:因为训练的是中文语料,需要做分词的预处理,然后根据训练语料的分词结果构建词表。训练时,输入语料查找每个词在词表中的位置,映射为数值输入。比如上图中,“非常”在词表中的索引值是 45,则在输入训练的时候映射为 45。这步可以通过 Tensorflow 中的 VocabularyProcessor() 和 embedding_lookup() 函数实现。
Embedding layer: 如上图所示,Embedding layer 由句子中每个词的词向量组成的 N×K 维的矩阵作为输入,其中 K 为词向量的维度,N 表示最长的句子的长度,实验中使用 K=64。因为卷积神经网络需要固定大小的输入,所以对于长度不足 N 的句子,用 0 填充。这个矩阵的类型可以是动态的(static),也可以是静态的 (non_static)。静态的就是词向量是固定不变的,而动态则是在模型训练的过程中,词向量可做优化的权重,通过反向传播算法来调整参数。可以看出动态调整参数把 two stage 的问题转化为了 one stage 问题,不需要单独去做文本向量化的工作,而且词向量直接和分类误差联系在一起,可以提高准确率。
卷积层:在 Embedding 的基础上,通过卷积操作得到特征图(Feature Map)。在实验中使用了 3 种不同大小的卷积核。不同于处理图像时卷积核都是正方形的,比如 3×3,5×5,7×7,使用的卷积核大小分别为 3×K,4×K,5×K, 这是因为每个词的维度是 K, 进行卷积操作时,感受野应该包括整个词的大小,所以卷积核的宽度为 K, 不同高度的卷积核考虑不同词之间的联系,比如高度为 5,则考虑到前后 5 个词之间的关系。使用不同大小的卷积核提取到的特征更丰富。对于每一种大小卷积核都使用 128 个,每一个卷积核通过与输入层卷积得到一个 Feature Map,在 NLP 中也称为文本特征,所以最后卷积层的输出为 300×N×1。
池化层:在卷积层之后使用最大池化层操作(maxpooling),即从一维的特征图中选择一个最大值,最大值代表着最重要的信号。最后将池化后的值拼接为一个一维向量作为下一层的输入。
全连接层 +sofmax:池化层输出的一维向量通过全连接的方式连接一个 sofmax 分类器。本文研究的情感分析主要分为三个类别(正,负,中)。故全连接层有三个神经元。在全连接层中使用 Dropout 防止过拟合,并在全连接层上加 L2 正则化参数。
如图 3 所示,CNN_character_level 的情感分类模型和 word_level 的模型结构是相似的,都是使用 CNN 的思想来做情感的分类。
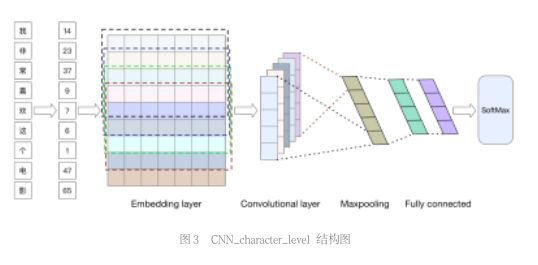
不过在实施细节上面有一些不同。第一,在建立词表的过程中,chareter_level 模型并不对原始语料做分词处理,而是直接对语料分字处理,根据字符建立字符表,然后根据查找字符表来获得语料的数字化表示。第二,在卷积核的使用上,charater_level 只使用了 5×K 大小的一种卷积核,因为基于字符处理,只有更大的卷积核才能考虑到上下文的关联信息。第三,character_level 在全连接时使用了 2 层全连接层,一般来说网络层数越多提取到的语义信息会更丰富。有关网络模型的详细参数会在实验部分给出,其中 charater_level 取得了最好的成绩。
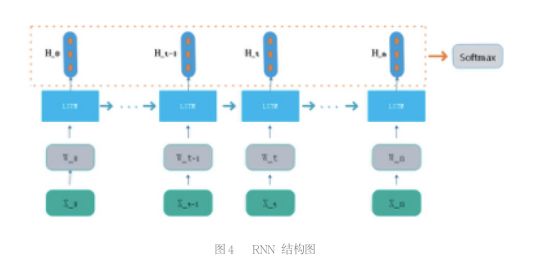
RNN 即循环神经网络,其用途是处理和预测序列数据。其核心是将历史信息连接到当前的任务中,具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。原生的 RNN 会遇到一个很大的问题,叫做 The vanishing gradient problem for RNNs, 即长期依赖问题,后面时间的节点对前面时间节点的信息感知力下降,也就是忘事。解决这个问题使用了 LSTM 神经单元,这是一种特殊结构的神经单元,能够解决长期依赖关系,由于篇幅原因,在这不详细介绍。RNN 的情感分类模型如图 4 所示,输入语料经过 embbedding layer 表示为向量, 每一个输入经过 LSTM 网络会有一个输出, 把所有的输出 H 叠加后送入 sofmax 分类器,输出分类结果。
情感分类的数据集使用内部的约 30000 条带有人工标注的财经新闻语料,其中正面标签的新闻 10013 条,负面标签新闻 10013 条,中性标签新闻 10011 条。将数据集按照 8:2 的比例划分为训练集和测试集。
机器学习模型中需要调整训练 Word2Vec 和 SVM 的参数。Word2Vec 的参数经过实验,确定的参数如下:sg=1, size=200, window=5, min_count=5, iter=5。SVM 在给定的参数列表中自动寻找最优的参数,具体细节可以参考提供的代码;CNN_word_level, 设置词向量矩阵的长度为新闻语料中最长的句子的词语的个数,词向量维度为 64。每种类型的卷积核个数为 128;CNN_character_level 和 RNN 模型的参数有很多,可以参考图 5。

使用准确率(precision)、召回率 (recall)、以及总体准确性 (accuracy) 对模型进行评估。表 1 和表 2 给出了机器学习模型在各个指标上的表现。根据表中数据可以看出中性新闻的准确率最低,而且从混淆矩阵来看,正面新闻和负面的判错的样例,也是大多数被判别到了中性新闻之中,这是因为中性新闻带有很强的主观性,不像正面和负面新闻一样,有很明确的标注标准。
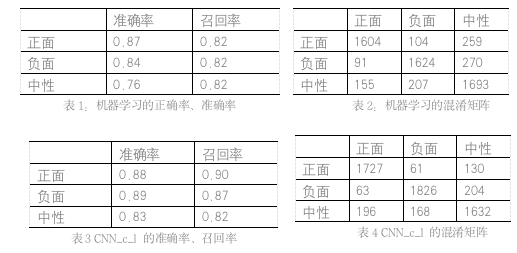

表 3 和表 4 给出了 CNN_character_level 模型评估结果,这是 4 个模型中表现最好的模型,相比于机器学习模型,深度学习模型的效果更好,在准确率和召回率上都得到了提高。表 5 给出了 5 种模型总体准确率(accuracy)对比,CNN_w_l 表示 CNN_word_level 模型, CNN_c_l 表示 CNN_character_level 模型。在 4 种模型中,CNN_character_level 取得了最好的结果:0.87, 其次是 RNN,CNN_word_level,机器学习,RNN 的精度也很高,但是在实际训练和测试过程中,RNN 模型非常耗时。总体来看,本文提出的模型很有竞争力,如果有足够多的语料,模型将会有更好的效果。
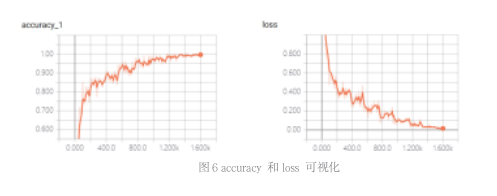
本文的深度学习模型都是用 Tensorflow 实现的,将构建网络的性能指标直观展现如图 6。
本文搭建的模型虽然取得了不错的成绩,但依然有很大的上升空间。后续将继续深入研究,不断优化已有的模型算法,做出改进,同时关注前沿技术的发展;研究自然语言处理的其他方向,不仅仅局限于情感分析。对于公司发展而言,只有算法和业务相结合才能产生效益,所以也会进一步了解业务需求,让技术与业务产生更好的化学反应,发挥最大的价值。

喜欢这篇文章吗?记得点一下「好看」再走👇




