AlphaCode能替代人类程序员吗?网友:被替代也挺好,这样就可以少写代码多开会了

DeepMind 是最新的人工智能研究实验室。它推出了一个可以生成软件源代码的深度学习模型,成果令人印象深刻。该模型被称为 AlphaCode,基于 Transformer,与 OpenAI 在其代码生成模型中使用的架构是一样的。
编程是深度学习和大型语言模型颇有前途的应用之一。对编程人才日益增长的需求刺激业界发起了一场发展创作工具的竞赛,这些工具可以提升开发人员的生产力,并给非开发人员提供创造软件的工具。
而在这方面,AlphaCode 肯定给人留下了深刻印象。它已经成功解决了很多复杂的编程挑战,这些难题往往需要数小时的计划、编程和测试。有一天它可能会成为一个很好的工具,可以用来把问题描述变成实用的代码。
但它肯定没法和任何级别的人类程序员相提并论。这是一种完全不同的软件创建方法,其中没有人类的思维和直觉参与,所以是不完整的。

编程挑战描述的例子(来源:DeepMind)
AlphaCode 不是业内在这一领域唯一的成果,但它完成了一项非常复杂的任务。其他类似的系统专注于生成简短的代码片段,如一个函数或一个代码块,旨在执行一个小任务(例如建立一个 web 服务器或从 API 系统中提取信息)。虽然这些任务令人印象深刻,但当语言模型被暴露在足够大的源代码语料库中时,这些任务就变得微不足道了。
相比之下,AlphaCode 的目的是解决竞争性的编程问题。编程挑战的参与者必须阅读挑战描述,理解问题,将其转化为算法解决方案,用通用语言实现它,并针对一组有限的测试案例进行评估。最后,他们的结果是根据不在实现过程中的隐藏测试的性能来评估的。编程挑战还可以有其他条件,如时间和内存限制。
总体而言,参加编程挑战的机器学习模型必须生成整个程序,解决一个与它之前所见所有事物都不一样的问题。这比根据以前看到的例子合成一个源代码摘录要困难得多。

编程挑战解决方案的例子(来源:DeepMind)
AlphaCode 是大型语言模型在解决复杂问题方面取得进展的又一个例子。这种深度学习系统一般被称为序列到序列模型(seq2seq)。Seq2seq 算法将一串数值(字母、像素、数字等)作为输入,并生成另一串数值。这是许多自然语言任务(如机器翻译、文本生成和语音识别)中使用的方法。
根据 DeepMind 的论文,AlphaCode 使用了一个编码器 - 解码器 Transformer 架构。近年来,Transformer 变得特别流行,因为它们可以处理很大的数据序列,而对内存和计算的要求比它们的前辈,循环神经网络(RNN)和长短时记忆网络(LSTM)要少得多。
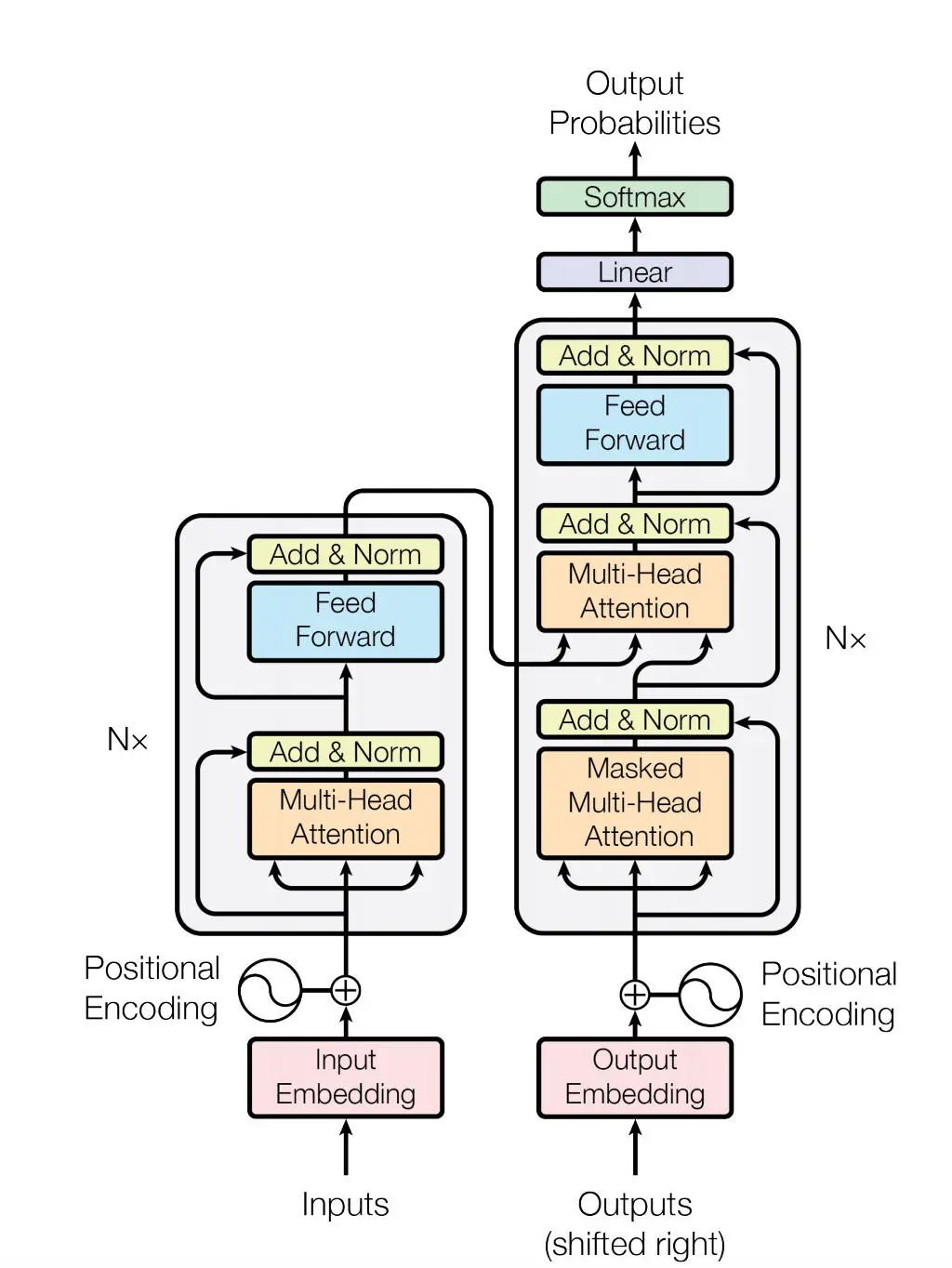
Transformer 网络结构
AlphaCode 的编码器部分为目标问题的自然语言描述创建一个数字表示。解码器部分接收由编码器生成的嵌入向量,并试图生成解决方案的源代码。
事实证明,Transformer 模型很擅长此类任务,特别是当它们被提供足够的训练数据和计算能力时更是如此。但比起把原始数据扔给超大型神经网络这样的暴力手段,在我看来,AlphaCode 的真正亮点更多归功于 DeepMind 的科学家在设计训练过程和生成及过滤其结果的算法方面展现出来的聪明才智。
为了创建 AlphaCode,DeepMind 的科学家使用了无监督预训练和有监督微调的组合。这通常被称为自监督学习,这种方法在没有足够的标记数据或数据注释昂贵且耗时的应用中变得很受欢迎。
在预训练阶段,AlphaCode 在从 GitHub 提取的 715 千兆字节的数据上进行无监督学习。该模型的训练过程是尝试预测语言或代码片段的缺失部分。这种方法的优点是,它不需要任何形式的注释;通过接触越来越多的样本,ML 模型逐渐变得更善于为文本和源代码的结构创建数字表示。
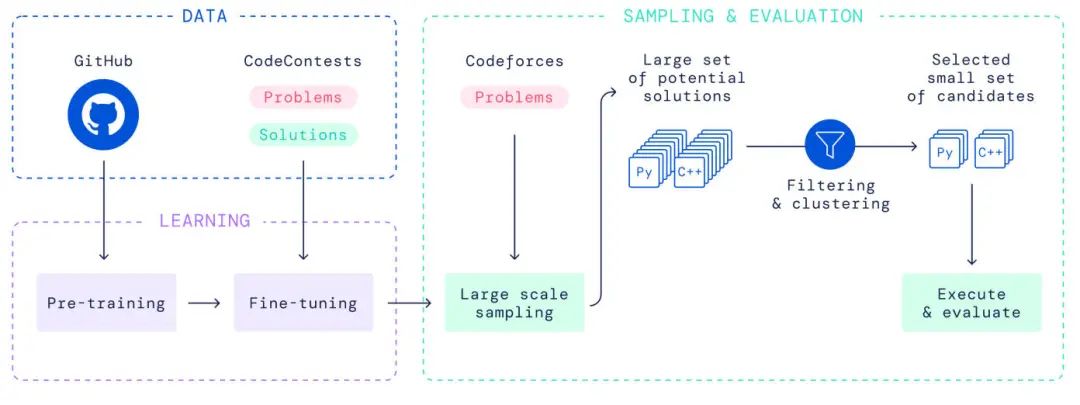
训练和应用 AlphaCode 的算法(来源:DeepMind)
之后预训练的模型在 CodeContests 上做微调,CodeContests 是由 DeepMind 团队创建的一个有注释的数据集。该数据集包含问题陈述、正确和错误的提交,以及从各种来源收集的测试案例——包括 Codeforces、Description2Code 和 IBM 的 CodeNet。该模型经过训练,可以将挑战的文本描述转化为源代码结果。它的结果用测试案例进行评估,并与正确提交的案例进行对比。
在创建数据集时,研究人员特别注意避免训练、验证和测试集之间的历史性重叠。这确保了 ML 模型在面临编程挑战时不会生成记忆性的结果。
一旦 AlphaCode 训练完成,它就会针对以前没有见过的问题进行测试。当 AlphaCode 处理一个新问题时,它会产生许多解决方案。然后,它使用一个过滤算法来选择最好的 10 个候选方案,并将它们提交到竞赛中。如果其中至少有一个是正确的,那么这个问题就被认为已经解决了。
根据 DeepMind 的 论文,AlphaCode 可以为每个问题生成数百万个样本,且它通常会生成成千上万的解决方案。然后 AlphaCode 对这些样本进行过滤,只留下那些通过了问题陈述中包含的测试的样本。根据论文,这一过程将删除大约 99% 的生成样本。但这样仍然会留下成千上万的有效样本。
为了优化样本选择过程,研究团队使用了一种聚类算法来将解决方案分为多个组。根据研究人员的说法,聚类过程倾向于将有效的解决方案组合在一起。这样就更容易找到一小部分有可能通过竞赛隐藏测试的候选者。
据 DeepMind 称,当在流行的 Codeforces 平台上的实际编程比赛中进行测试时,AlphaCode 在参赛者中平均排名是前 54%,考虑到编程挑战的难度,这样的结果非常令人印象深刻。
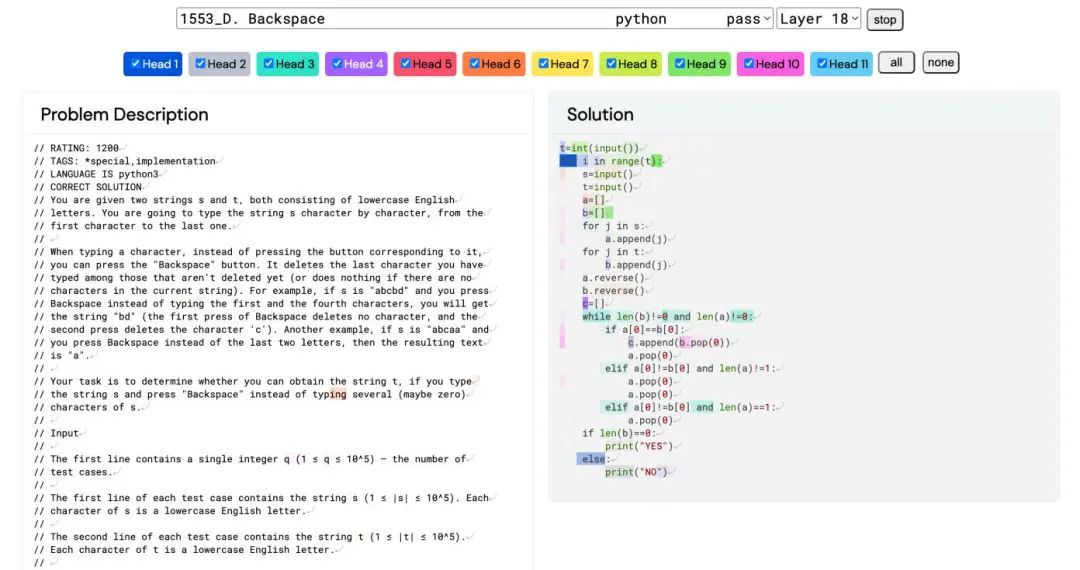
AlphaCode 的问题解析和代码生成过程的可视化(来源:DeepMind)
DeepMind 的博客正确地指出,AlphaCode 是人工智能代码生成系统第一次“在编程比赛中达到了具有竞争力的水平”。
然而,一些出版物将这一说法误认为 AI 编程“与人类程序员一样出色”,这就是将狭义的人工智能与人类的一般问题解决能力对比的谬误。
例如,一般来说,你可以预期一位擅长国际象棋和围棋的选手在其他许多方面也很聪明。事实上,在学习和掌握国际象棋之前,你必须先获得其他许多认知技能。然而,过去几十年的经验已经证明,人工智能系统可以在不获得所有这些技能的情况下,通过捷径解决非常困难的问题。
两个最好的例子是 DeepBlue 和 AlphaGo,这两个人工智能系统在国际象棋和围棋方面击败了人类世界冠军。虽然这两个系统都是计算机科学和人工智能领域了不起的成就,但它们只擅长一项任务。它们无法在其他任何需要仔细规划和制定战略的任务中与人类对手对抗,而这些技能是那些人类在成为国际象棋和围棋大师之前就已经掌握的。
竞争性编程也是一回事。一位在编程挑战中达到前列水平的人类程序员已经花了多年时间学习。他们可以抽象地思考问题、解决更简单的挑战、编写简单的程序,并表现出其他许多技能,而这些技能在编程比赛中被认为是理所当然的,并不会得到评估。
一言以蔽之,这些比赛是为人类设计的。你可以肯定,一般来说,在编程竞赛中排名较高的选手也是一名出色的程序员。这就是为什么许多公司使用这些挑战来做招聘决定。

相比之下,AlphaCode 是竞争性编程的一个捷径——尽管这是一条出色的捷径。它创造了新颖的代码。它不会从其训练数据中复制 - 粘贴。但它并不等同于一名普通的程序员。
人类程序员使用他们的直觉来引导他们有限的计算资源向正确的解决方案方向发展。他们使用调试、分析和审查过程来完善他们的代码。相比之下,AlphaCode 会生成成千上万的样本——有时多达 100,000 个——并对它们进行过滤,以找到有效的样本。
正如计算机科学教授 Ernest Davis 所观察到的,“这个过程很像是一大群猴子随机打字就能打出来哈姆雷特的故事。AlphaCode 已经成功地将猴子训练到了一个了不起的程度,但他们仍然需要大量猴子。然后它生成了 10 个候选结果,如果其中一个是正确的,它就认为自己成功了。”
他说的就是无限猴子定理,该定理指出,“一只猴子在打字机键盘上随机敲击按键无限长的时间,几乎肯定会打出任何给定的文字”,自然包括了莎士比亚的哈姆雷特。
这并不是对 AlphaCode 的攻击。事实上,AlphaCode 证明了凭借巧妙的设计、足够的计算能力和大量的数据,你就可以创建一个人工智能系统来搜索一个巨大的解决方案空间,而这个空间是不可能通过粗暴的计算来探索的(这也是 DeepMind 对 AlphaGo 所做的事情)。
然而,我们也必须承认这种方法的局限性。首先,正如 Davis 所指出的那样,随着解决方案变得越来越长,问题会变得极为困难。他写道:“AlphaCode 需要 100 万个样本才能在 20 行的程序上获得 34% 的正确率;要制作一个 200 行的程序——也就是计算机科学二年级的标准作业的长度——很可能需要 10^60 个样本”。
第二,AlphaCode 明确要求有良好的问题陈述和测试案例来评估和过滤它所生成的成千上万的样本。“现在,毫无疑问,提供输入和输出对于编程比赛中的人类参赛者是非常有用的,”Davis 写道。“尽管如此,就算不提供这些信息,人类程序员在大多数情况下依旧可以成功,只是要多做一点工作。相比之下,如果不提供具体的例子,AlphaCode 就会完全陷入困境;成功率会下降到不足百一。”
因此,与其让 AlphaCode 与人类程序员对决,我们更应该关注 AlphaCode 和其他类似的人工智能系统在与人类程序员联手时能做什么事情。这种工具可以对人类程序员的生产力产生巨大的影响。它们甚至可能给编程文化带来变化,使人类将重点转向制定问题(这门学科仍然是人类智能的领域)并让人工智能系统生成代码。
但人类程序员仍将处于控制地位。他们必须善用人工智能生成代码的力量和种种限制。
人们应该意识到 AlphaCode 的本来面目:一个代码生成器,可以为精心设计的问题陈述提出良好的候选解决方案。人们也应该承认它并不是:人类程序员的数字等价物。
原文链接:
https://bdtechtalks.com/2022/02/07/deepmind-alphacode-competitive-programming/
5 月 12-14 日,QCon 北京站策划【AI 基础架构】专题,邀请第四范式、百度、Zilliz 等公司高级专家现场分享,议题如下:
AI 数据库的内存优化之路,陈迪豪,第四范式平台架构师大模型时代的异构计算平台,孙鹏,百度资深研发工程师万物皆向量化——向量数据库 Milvus 的现状与未来,栾小凡,Zilliz 合伙人演讲提纲可点击底部【阅读原文】查看。QCon 北京站现场门票优惠即将结束,感兴趣的同学可扫描图中二维码或直接联系票务经理:17310043226。

今日荐文
点击下方图片即可阅读

华为穿过黑障区:年净利1137亿,暴增75%背后的核心竞争力在于研发投入

你也「在看」吗?👇


