CVPR2020 | 基于点的3D单阶段对象检测器3DSSD

论文原文:3DSSD: Point-based 3D Single Stage Object Detector
论文地址:https://www.aminer.cn/pub/5e54f1813a55acae32a25f25
作者:Zetong Yang,Yanan Sun,Shu Liu,Jiaya Jia
发表会议:CVPR 2020
基于体素的 3D 单阶段检测器的普及率与未开发的基于点的方法形成对比。在本文中,作者提出了一种轻量级的基于点的 3D 阶段目标检测器 3DSSD,以实现准确性和效率的良好平衡。在这种范例中,所有现有的基于点的方法中必不可少的上采样层和优化阶段都将被放弃。相反,在下采样过程中提出一种融合采样策略,以使在代表性较小的点上进行检测变得可行。本文为了满足高精度和高速度的要求,开发了一种精细的框预测网络,其中包括候选生成层和具有 3D 中心度分配策略的无锚回归头。3DSSD 范例是一种优雅的单阶段免锚模式,在广泛使用的 KITTI 数据集和更具挑战性的 nuScenes 数据集上对其进行评估,本文的方法大大优于所有基于体素的单阶段方法,甚至可以产生与两阶段基于点的方法相当的性能,推理速度高达 25+ FPS,比以前的最先进的基于点的方法快 2 倍。
3D 画面理解对于包括自动驾驶和增强现实在内的许多应用都起到了促进,本文聚焦于 3D 的目标检测,即预测点云表示的3D目标的边缘框及其类别标签。
2D 的目标检测已经有了很大突破,但无法直接将其方法应用到 3D 的场景中。与 2D 的图片相比,点云更加稀疏无序,而且对于局部特征十分敏感,这使得我们很难使用 CNN 进行学习,因此 3D 的目标检测的主要问题就是如何利用点云数据。
已有的一些方法如将点云转化为图片、将点云分割为等分布的体素,本文将其称为基于体素的方法,这些方法都是将点云转化为 2D 的目标检测算法可以应用的形式,虽然这些方法直接且有效,但在转化过程中仍然存在着信息损失,这影响了其表现的进一步提升。
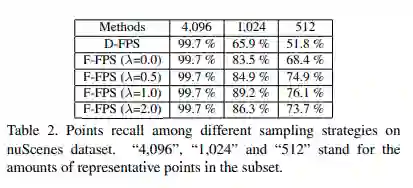
还有一些基于点的方法直接将点云作为输入,然后对每一个点进行边界框的预测。其中又分为两个阶段,第一个阶段设置一些集合提取层(SA)用于降采样以及抽取上下文特征,另一个阶段则是使用特征传播层(FP)来进行上采样以及传播点在降采样中丢失的特征。一种 3D 的区域建议网络(RPN)可以为每个点生成建议,从而在第二阶段给出最终的预测结果。这些方法取得了更好的效果,但做 inference 需要更长的时间。其中 FP 的第二阶段耗费了一半的 inference 时间,目前 SA 中的采样策略是基于 3D 欧氏距离的最远点采样(D-FPS),这意味着先前仅有少数内部点的样本或许会在采样后被丢失,从而导致它们无法被检测到。
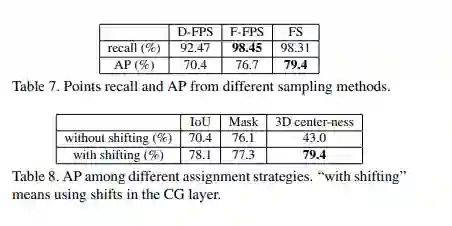
在 STD 中,如果不使用上采样而仅使用降采样后被保留下来的点做检测,模型的效果将会下降 9%,这就是 FP 必须要用来做上采样的原因。为解决这一问题,本文首先提出了一种基于特征距离的采样策略 F-FPS,并进一步的将 F-FPS 与 D-FPS 进行混合。
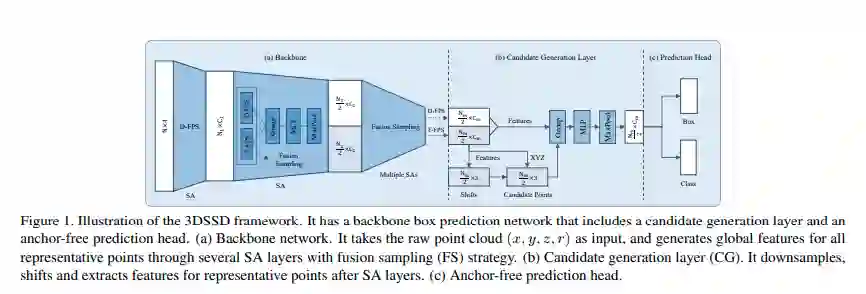
为了更好地探索在 SA 之后被保留下来的有代表性的点,本文提出了一个边框预测网络,包括一个候选生成层(CG)、一个无锚回归头和一个 3D 中心分配策略。在 CG 中,首先用 F-FPS 中有代表性的点生成候选点,这一过程收到这些点以及共现例子中的中心点的相对位置的约束。接下来将这些候选点作为中心,从 F-FPS 和 D-FPS 有代表性的点中选取其周围的点,将其特征通过多层感知网络(MLP),这些特征最终被输入到无锚回归头中来预测 3D 边框。本文还设计了一个 3D 中心分配策略,给候选点中更靠近样本中心的点更高的得分。
本文在 KITTI 和 nuScenes 两个数据及上进行了实验,实验结果表明本文提出的方法优于所有基于体素的单阶段方法,在更快的 inference 的基础上与两阶段基于点的方法也具有一定可比性。
本文的主要贡献如下:
1. 提出了一个轻量而高效的基于点的单阶段 3D 目标检测器 3DSSD,抛弃了需要大量计算的 FP,这与已有的基于点的方法都不同。
2. 提出了一个混合的采样策略,可以保留先前仅有少数内部点的样本。
融合采样
3D 目标检测有基于点和基于体素两种框架,前者更加耗时,由候选生成与预测细化两个阶段组成。
在第一个阶段,SA 用于降采样以获得更高的效率以及扩大感受野,FP 用来为降采样过程中丢掉的点传播特征。在第二阶段,一个优化模块最优化 RPN 的结果以获得更准确的预测。SA 对于提取点的特征是必需的。但 FP 和优化模块会限制效率。

边框预测网络
已有的工作是在得到每个点的特征后接三层 SA 分别用于中心点选择、周围点特征的提取以及生成语义信息。本文为进一步降低计算成本,候选中心点的生成是直接在 F-FPS 采样后进行的。F-FPS 采样的点由于比 D-FPS 的点更加可能是前景点,所以候选点仅仅只是在 F-FPS 的点上生成。接着作者将这些候选中心点当作候选生成层的中心点。最后根据候选中心点领域选择从 F-FPS 和 D-FPS 中采样得到的代表点进行局部特征提取,采用 MLP 进行特征提取。
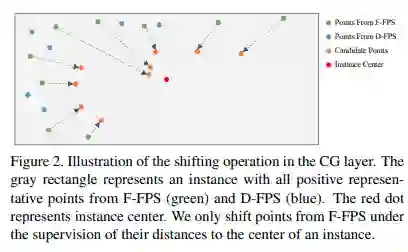
在训练过程中,需要一种分配策略来为每个候选点打标签。在 2D 但阶段检测中,IoU 阈值或 mask 可以用于标签分配。在 3DLIDAR 数据上,由于点云数据都在物体的表面,因此他们的中心性非常接近的,这会导致不太可能从这些点得到好的预测。因此之前生成候选点的时候要选取采样后再朝中心靠近的点而不是直接用原始采样点。
本文通过两步定义候选点的中心标签:
1. 确定该点是否在一个目标中;
2. 计算该点到这个目标六面体上下左右表面的距离,再通过以下公式得到 l_ctrness:
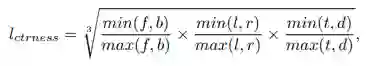
全部损失函数分为分类损失、回归损失和偏移损失(这个是指从采样代表点到候选点得到时的损失函数)。
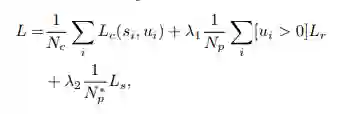
本文实验使用了 mix-up、随机旋转平移、x 轴尺度变化、z 轴旋转四种数据增强方法。在 KITTI 和 nuScenes 两个数据集上进行了实验。
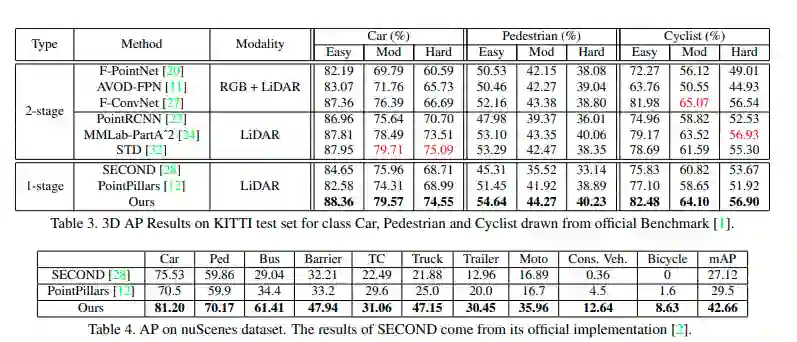
值得注意的是,本文的方法甚至可以与基于体素的单阶段方法保持相似的 inference 速度。在所有现有方法中,本文的方法仅比 PointPillars 慢,而 PointPillars 已通过多种实现优化策略(例如 TensorRT)进行了增强,但是在本文的实现中尚未使用。本文的方法仍有很大的潜力可以进一步加速。
本文首次提出了一种轻量级且高效的基于点的 3D 单阶段目标检测框架,并引入了一种新颖的融合采样策略,以删除费时的 FP 和优化模块。在预测网络中,候选生成层利用降采样的代表点进一步降低计算成本。本文提出的带有 3D 中心标签的无锚回归头提高了最终性能。所有这些有效的设计使本文的模型在性能和 inference 时间方面都表现更加出色。