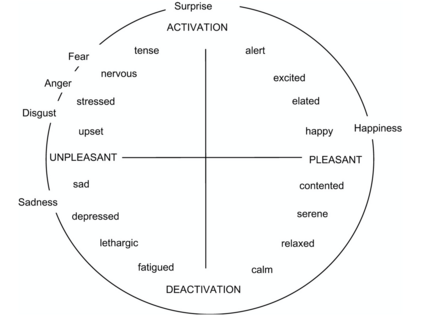
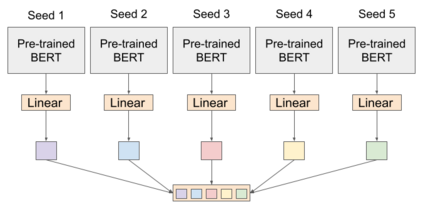
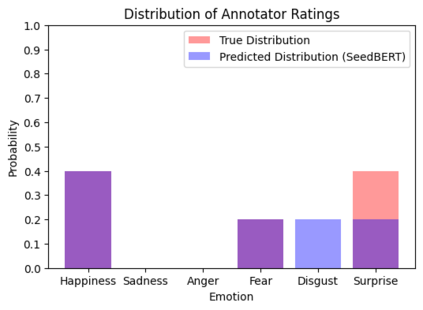
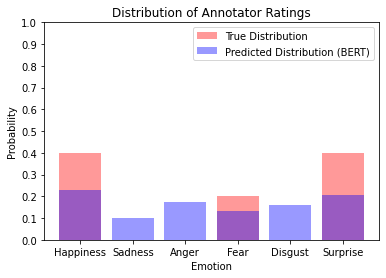
Many machine learning tasks -- particularly those in affective computing -- are inherently subjective. When asked to classify facial expressions or to rate an individual's attractiveness, humans may disagree with one another, and no single answer may be objectively correct. However, machine learning datasets commonly have just one "ground truth" label for each sample, so models trained on these labels may not perform well on tasks that are subjective in nature. Though allowing models to learn from the individual annotators' ratings may help, most datasets do not provide annotator-specific labels for each sample. To address this issue, we propose SeedBERT, a method for recovering annotator rating distributions from a single label by inducing pre-trained models to attend to different portions of the input. Our human evaluations indicate that SeedBERT's attention mechanism is consistent with human sources of annotator disagreement. Moreover, in our empirical evaluations using large language models, SeedBERT demonstrates substantial gains in performance on downstream subjective tasks compared both to standard deep learning models and to other current models that account explicitly for annotator disagreement.
翻译:许多机器学习任务 -- -- 特别是在感官计算中 -- -- 本质上是主观的。当被要求对面部表达方式进行分类或评定一个人的吸引力时,人类可能会相互分歧,而没有任何单一答案可能客观正确。然而,机器学习数据集通常对每个样本只有一个“地面真相”标签,因此,在这些标签上培训的模型在主观性质的任务上可能无法很好地发挥作用。虽然允许模型从个别评分者评分中学习,但大多数数据集并不为每个样本提供说明性特定标签。为了解决这个问题,我们建议SeedBERT, 一种从单一标签中恢复说明性评级分布的方法,通过引导预先训练的模型处理不同部分的投入。我们的人类评估表明,SeedBERT的注意机制与人类对说明性差异的来源是一致的。此外,在我们使用大型语言模型进行的经验评估中,SeedBERTRT在下游主观任务上的表现与标准的深层次学习模型和明确说明意见分歧的其他当前模型相比,都取得了很大的进步。