图卷积神经网络的变种与挑战【附PPT与视频资料】

关注文章公众号
回复"高扬"获取PPT与视频
视频资料可点击下方阅读原文在线观看
1、主题简介
半监督图卷积神经网络(Semi-GCN)对原始的GCN进行了约束与简化,也因此诞生了诸多研究方向。GraphSAGE首先归纳出了Neighbor Aggregate模式;GAT将Attention机制引入到了GCN当中;GeniePath尝试将GCN的层次做深。本次讨论将主要介绍semi-GCN之后的这些变体与它们之间的联系,以及当前GCN研究当中的问题与挑战。
作者简介
高扬,中国科学院信息工程研究所硕博二年级在读,本科毕业于吉林大学。目前主要研究方向是图神经网络及其应用。

2、具体内容
2.1 引言
半监督图卷积神经网络(semi-GCN)的运算公式如下:
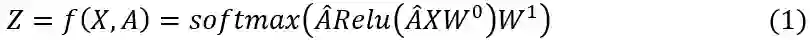
其中,X为每个节点的特征,图的结构信息以矩阵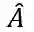
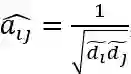
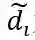
因此,针对图中的每一个节点有如下公式:
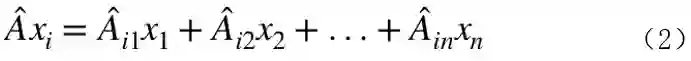
对于公式(1),如果去掉矩阵
邻居权重计算(semi-GCN利用节点的度计算邻居权重)
邻居信息的聚集方法(semi-GCN使用求和的方式)
邻居选择(semi-GCN使用一阶邻居)
2.2 GCN的变种
2.2.1 聚集方法的改进-GraphSAGE
GraphSAGE(SAmpleand aggreGatE)主要优化semi-GCN在大图上进行Inductive Learning的局限。
Inductive Learning的主要目的是学习网络中新加入节点(或者同类型新图中节点)的Embedding。对于网络中新加入的节点,训练阶段没有新节点的结构信息,而semi-GCN在训练阶段利用了全局的结构信息。而对于大图,semi-GCN在大图上使用时利用了全部的一阶邻居,所以运行速度慢。

Figure 1 GraphSAGE学习Embedding的过程
GraphSAGE给出的解决方案相对简单:对一阶邻居进行采样,即采样;充分利用采样后的邻居信息,即聚集。采样的方式简单粗暴,对一阶邻居随机排序;选取固定数量的邻居;少则重复,多则舍弃。对于聚集,GraphSAGE提出了三类聚集器:
MeanAggregator:element-wisemean。由于采样过程选择为每个节点采样了相同数量的邻居,所以采样后,每个节点度是一样的,所以semi-GCN中的聚集方式(加权求和)可以看作是MeanAggregator的一种特例。
PoolingAggregator:element-wise max or mean,包含一层Dense Layer
LSTMAggregator:训练RNN网络,将邻居特征作为输入
在algorithm 1中用到了Concat操作,即将历史Embedding与当前Embedding进行拼接,Concat操作可以看作是利用历史Embedding的一种方式。更多的利用方式在Jump Knowledge Networks中:

Figure 2 JK-Networks示意图
GraphSAGE可以应用在大图的Inductive Learning任务中,但是随机采样有损于模型的模型的精度。
2.2.2 邻居权重的改进-GAT,GeniePath
Semi-GCN邻居权重是固定的,且只与节点的度相关,GraphSAGE邻居权重固定是1。GAT利用Attention机制(公式3)学习邻居权重,利用multi-head机制增加稳定性。
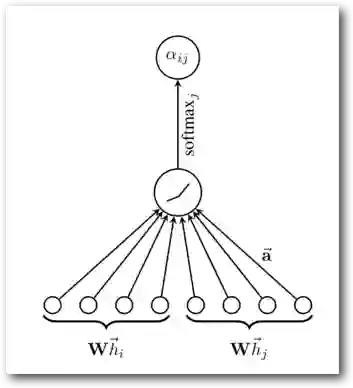
Figure 3 GAT中的Attention机制
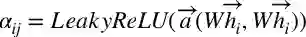
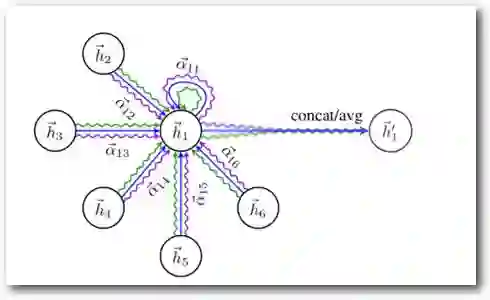
Figure 4 GAT中的多头机制
引入Attention机制后,GAT的性能有了明显的提升,但是由于利用了全部的一阶邻居,所以在大规模图上的速度较低,而且跟很多GCN模型一样,随着神经网络层数的增加,GAT的效果会降低。

Figure 5 GAT在TransductiveLearning实验中的效果
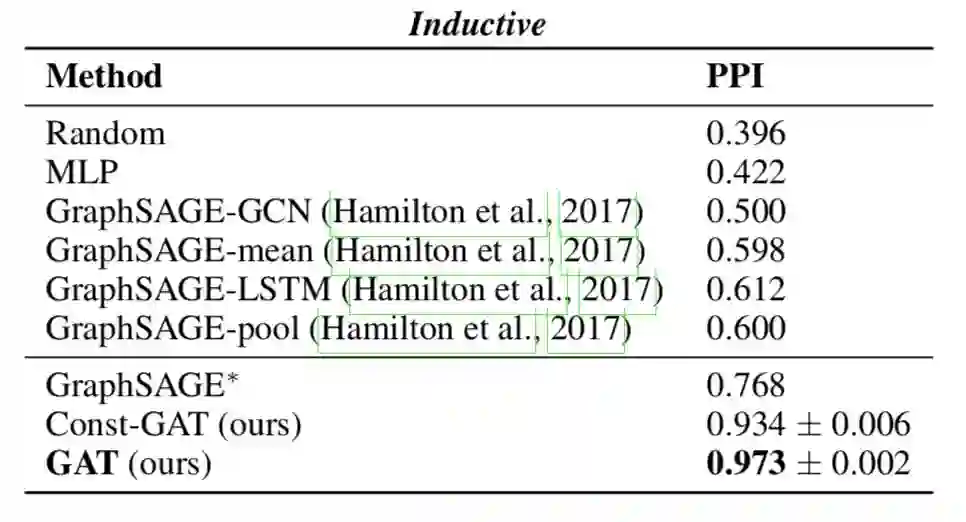
Figure 6 GAT 在Inductive Learning实验中的效果
之前提到的算法对于不同阶邻居,不同传播路径是同等对待的。在GeniePath中,模型引入LSTM的遗忘门机制,使得不同阶邻居、不同的传播路径对最终的Embedding影响不同。
GeniePath的结构如下:
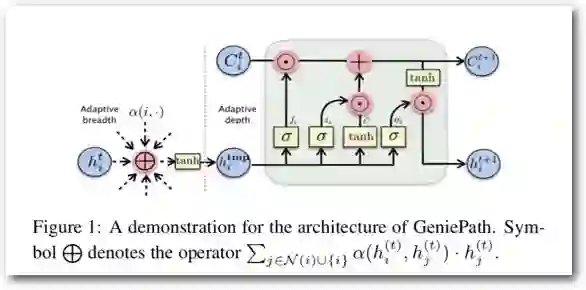
Figure 7 GeniePath的结构
由图7可看到,GeniePath在应用Attention机制之后又过了一个LSTM,从实验的角度看,这种做法使得GCN的层数增加并保持模型的效果不衰减,但是同时也增加了大量的参数。
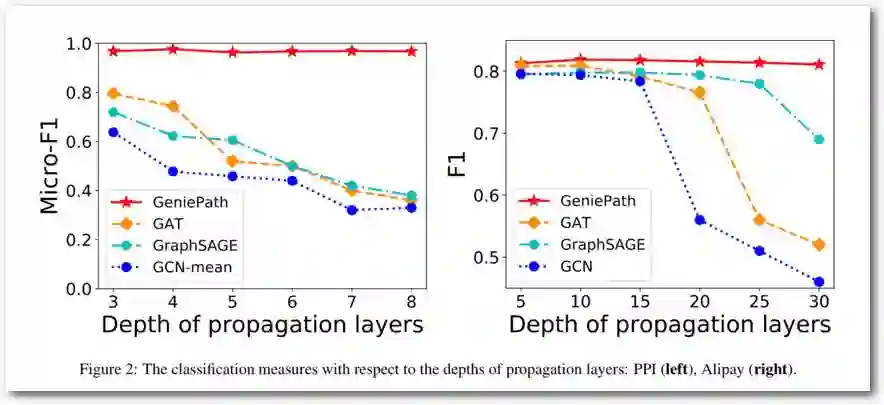
Figure 8 GeniePath随层数增加效果可以保持
2.2.3 邻居采样方式的改进
文献[5]和[6]中对邻居采样方式进行了改进,使得采样后,模型能够保持semi-GCN的性能,同时加快训练过程,在此不做赘述。
3、经验分享
图卷积神经网络的挑战:
在异质图中的应用:上述模型并未充分利用边的信息,而且存在多类型边,多类型节点的情形,上述模型也不能很好得处理
新的图卷积核的定义:上述模型基本都给予semi-GCN中卷积核的定义;新的卷积核也许会提升模型的性能
GCN网络的层数:semi-GCN,GraphSAGE,GAT随着层数增加效果会下降。虽然有工作分析原因,但是没有彻底解决这一问题。GeniePath虽然可以在层数增加的同时模型效果没有下降,但是效果并没有提升;最理想的情形应该是随着层数增加效果没有提升。
处理大规模图,动态图:处理大规模图和动态图时会有大量的计算量,目前在这些方向已经有一些工作,但这方面仍需要进一步的研究。
4、参考文献
[1] Hamilton W L, Ying R, Leskovec J.Inductive Representation Learning on Large Graphs[J]. 2017.
[2] Veličković P,Cucurull G, Casanova A, et al. Graph Attention Networks[J]. 2017.
[3] Liu Z, Chen C, Li L, et al.GeniePath: Graph Neural Networks with Adaptive Receptive Paths[J]. 2018.
[4] Xu K , Li C , Tian Y , et al.Representation Learning on Graphs with Jumping Knowledge Networks[J]. 2018.
[5] Chen J , Ma T , Xiao C . FastGCN:Fast Learning with Graph Convolutional Networks via Importance Sampling[J].2018.
[6] Chen J, Zhu J, Song L. StochasticTraining of Graph Convolutional Networks with Variance Reduction[J]. 2017.
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn


历史文章推荐:



