逆天!MIT新“像素发声”系统,完美分离声与画(附视频)

新智元报道
来源:MIT CSAIL
编辑:小潘、克雷格
【新智元导读】麻省理工学院(MIT)的计算机科学与人工智能实验室(CSAIL)最近研发出一种名为Pixel Player系统,能够通过大量无标签的视频来学习声音定位,并把声音与声源的像素点进行分离。此外,利用Pixel Player系统,用户能够对图像中不同的声音分别进行音量调节,实现简单的音频编辑。

Adobe Audition的音频剪辑霸主地位可能不保了。
最近,MIT的计算机科学与人工智能实验室(CSAIL)研发出一种名为Pixel Player系统,能够通过大量无标签的视频来学习声音定位,更强大的是,Pixel Player能够把声音与声源的像素点进行分离,并完美做到视觉与声音的同步,“想听哪里点哪里”。
同时,利用Pixel Player系统,用户能够对图像中不同的声音分别进行音量调节,实现简单的音频编辑。
论文地址:https://arxiv.org/abs/1804.03160
通常来讲,人类依靠强大的听觉和视觉能力组合,能够轻松识别和分辨声音与发出声音的声源物体,但对机器来讲比较困难,其视觉能力与听觉能力组合起来达到的识别水准并不如人类。
CSAIL制作了一个视频Demo,展示了Pixel Player是如何通过点击图片就能实现视频声音的分离与调节,从而“让像素发声”。
简单来说,Pixel Player首先通过大量视频学习定位声音产生的像素区域,然后将视频的声音与发声的像素点进行分离。这样,点击图片中声源的位置,就能发出相应的声音。
如视频中所示,点击图片中相应的乐器,就能发出对应的声音,但点击墙壁、人体等位置则不会发声(有轻微噪声)。
Pixel Player系统更强大的地方在于,它不仅能分离图片与声音,还能够对声音的音量进行调节。
在上面的视频中,Pixel Player能够对画面中乐器演奏的音量进行大小调节,若调到最小位置,则实现消音,起到类似Adobe Audition中的声音移除效果。
Pixel Player系统像是“图片版”Adobe Audition,虽然目前功能还远远不及后者强大,但其应用前景广泛。例如,在视频制作中,可以直接通过对图像的编辑实现音画分离,省去了单独剪辑音频的过程。
摘要
本文提出PixelPlayer,这个系统通过利用大量无标签的视频来学习如何定位产生声音的图像区域,并将输入的声音根据发声的像素点进行分离。我们的方法利用了可视化和音频模式的自然同步,在无监督的情况下学习了联合解析声音和图像的模型。在新收集的MUSIC数据集上的实验结果表明,我们提出的混合-分离框架比将基线系统效果更好。一些定性的结果表明,我们的模型在视觉上学习了真实的声音,使应用程序能够独立地调整声音源的音量。
1.介绍
这个世界蕴含着丰富的视觉和听觉信号。我们的视觉和听觉系统能够识别世界上的物体,分割被物体覆盖的图像区域,并将不同物体产生的声音进行隔离。虽然听觉场景分析在环境声音识别领域得到了广泛的研究,但在视觉和声音的自然同步可以为视觉提供一个丰富的监控信号。通过视觉或声音来识别物体的系统通常需要大量的有标签数据来训练。然而,在这篇论文中,我们利用联合视听学习来实现在无监督的条件下,通过音频和视频的结合来识别产生声音的物体,并分离来自每个物体的音频成分。我们将系统命名为PixelPlayer。在一个输入视频中,PixelPlayer将相应的音频分离,并在视频中对它们的发声进行空间定位。PixelPlayer使我们能够监听视频中每个像素发出的声音。
本文通过利用视觉和声音之间的自然同步来学习基于视觉的视听模型。PixelPlayer的输入是音频的波形数据,用于预测与此音频对应的视频中发声物体的位置。
图1显示了一个本文提出的处于工作状态的PixelPlayer。在这个例子中,系统使用大量的视频数据进行训练,其中包含了使用不同的乐器进行演奏的场景,包括独奏和二重奏。在每一段视频中,乐器的种类,它们的位置以及它们如何发声都没有任何标签提供。
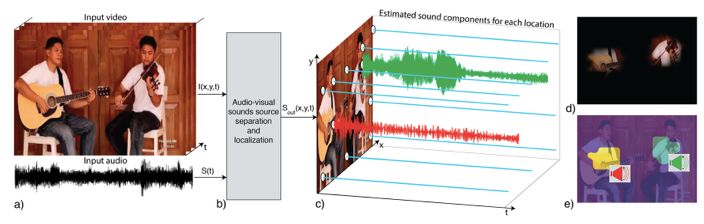
图1
在测试阶段,输入(图1.a)是一段包含几个不同乐器演奏场景的的视频I(x,y,t)和单声道音频S(t)。PixelPlayer执行视频和声音的分离以及发声定位,将输入声音信号分解为不同的声音组成部分Sout(x,y,t),每一个声音对应于来自视频帧中的一个空间位置(x;y)。作为一个例子,图1.c显示了从11个像素中恢复的音频信号。平坦的蓝色线条对应于被系统预测无声的像素。有声的信号与每个乐器产生的声音相对应。图1.d显示了预测的声音能量,或来自每个像素的音频信号的音量。请注意,系统正确地检测到声音来自于两个乐器的位置,而不是来自于背景。图1.e显示了像素是如何聚集在声音信号周围的。同样的颜色被分配给产生相似声音的像素。
将声音融入视觉的能力将对一系列与视频识别和处理相关的应用产生重大影响。PixelPlayer分离和声源定位的能力将可以对每个物体的声音进行独立的处理,这有助于听觉识别。我们的系统还可以促进对视频进行声音编辑,例如,对特定对象的音量进行调整,或者删除来自特定声源的音频。
最近有两篇论文提出通过视音频结合来对不同源的音频进行分离。其中一篇提出了如何通过人的外表来解决语音领域的鸡尾酒会问题。例外一篇论文演示了一个视听系统,它将屏幕上场景对应的声音和屏幕上不可见的背景音相分离。
2.视听分离与定位
在本节中,我们将介绍PixelPlayer的模型架构,并提出可以根据视频来分离声音的混合-分离训练框架。
2.1 模型结构
本文提出的模型由三部分组成:一个视频分析网络、一个音频分析网络和一个音频合成网络,如图2所示:
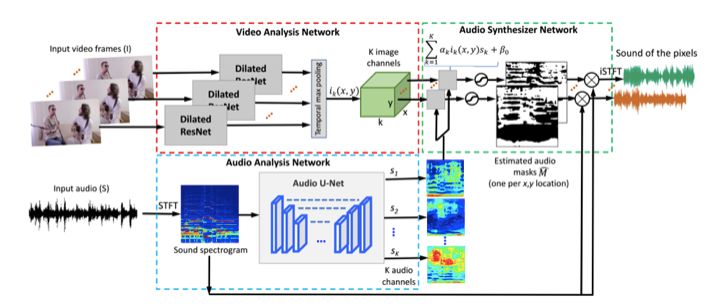
视频分析网络:它主要通过视频帧提取视频特征,它可以是用于可视化分类任务的任意网络架构。本文中应用的是ResNet-18的扩展版本,关于这个网络的具体细节会在实验部分进行详细的描述。对于一个大小为TxHxWx3的视频,ResNet模型对每一帧提取Tx(H/16)X(W/16)xK的特征,在应用temporal池化处理后,可以获得大小K的帧特征ik(x,y)。
音频分析网络:音频分析网络使用的是U-Net结构,将输入声音分割为K个部分,用Sk(K=1,…,k)表示。经验发现,使用语谱图比使用原始波形的效果更好,因此本文所提出的网络使用了声音的时频(T-F)特征。首先,对输入的混合音频使用短时傅里叶变换(STFT)以获得其语谱图,然后将语谱图转换到数频域,并将获得的特征输入到U-Net网络中,以获得包含不同声源的特征图谱。
声音合成网络:声音合成网络最终通过获得的像素级视频特征ik(x,y)和音频特征sk来预测待预测声音。输出的语谱图是通过基于视频的光谱图掩膜技术获得的。具体地说,一个掩膜M(x, y)可以将像素的声音从输入的音频中分离出来,并与输入谱图相乘。最后,为了得到预测的波形,我们将语谱图的预测振幅与输入谱图相结合,并利用Griffin-Lim算法来重建。
2.2半监督训练的混合-分离模型
训练混合-分离描写的想法是人为地创建一个复杂的听觉场景,然后解决声音分离和真实的听觉场景分析问题。 利用音频信号具有叠加性的事实,我们通过混合来自不同视频的声音来生成复杂的音频输入信号。 该模型的学习目标是从输入的音频中分离出一个以与视觉输入相关的音频。
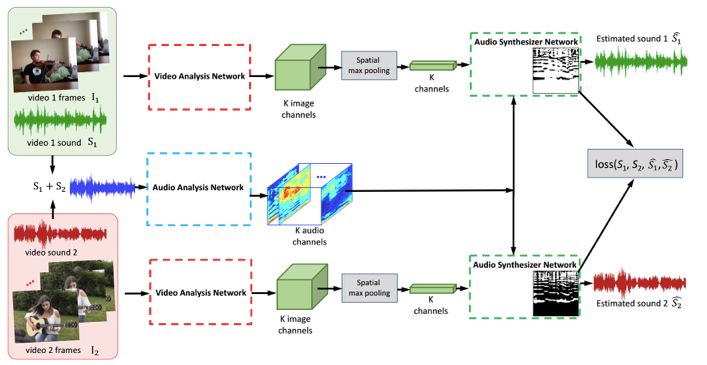
图3
图3显示了在两个视频混合情况下的训练框架。训练阶段与测试阶段不同,主要体现为以下两个部分:1)我们从训练集中随机抽取多个视频,并混合它们的音频部分,目的是根据相应的视觉输入来恢复出每一个音频;2)视频特征是通过时空(spatial-temporal)的最大池化方法(max pooling)获得的,而并非像素级的特征。值得注意的是,尽管训练过程中有明确的目标,但仍然是无监督的,因为我们不使用数据标签,也不对采样的数据做出假设。
我们系统中的学习目标是语谱图的掩膜,它们可以是二进制掩膜或比率掩膜。对于而进制掩模,通过观察目标声音在每个T-F单元中混合声音的主要成分,计算出第N个视频的目标掩膜的值。
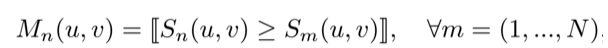
其中(u,v)表示以T-F为单位的坐标轴,S表示的语谱图。每一个像素点的sigmoid交叉熵损失函数用来作为学习的目标函数。对于比率掩膜,视频的真实掩膜是通过目标声音和混合声音的振幅比例来计算的。
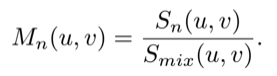
在这里,每一个像素点L1损失是用来训练的。要注意的一点是,真实的掩膜值由于一些干扰,不一定一直在[0,1]范围内。
3.实验过程与分析
3.1实现细节
我们在模型训练中的目标是能够在自然的视频上学习(包括solos和duets),对验证集进行定量评估,最后用混合数据解决自然视频的源分离和定位问题。因此,我们将我们的音乐数据集分成500个视频进行培训,130个视频用于验证,还有84个用于测试的视频。其中,500个训练视频包含了二重奏和独奏,验证集只包含独奏,而测试集只包含二重奏。
在训练过程中,我们从MUSIC数据集中随机抽取N=2个视频,这些视频可以是solos、duets或静默背景。无声的视频是通过将无声的音频波形与包含自然环境图像的ADE数据集的图像随机配对的。这种技术通过引入更多的无声视频,使模型更适合于对象的定位。总而言之,输入混合音频可以包含0到4个乐器。我们也尝试了混合更多的声音,但这使得这项任务更具挑战性,而且模型也没有训练得更好。
在优化过程中,我们使用一个动量=0.9的SGD优化器。因为我们在ImageNet上采用了预训练的CNN模型,因此将音频分析网络和音频合成器的学习速率设置为0.001,并将视频分析网络的学习速率设为0.0001。
3.2模型的训练效果
为了对模型的性能进行定量的评估,我们还使用混合-分离的过程来制作合成混合音频的验证集,然后进行分离。
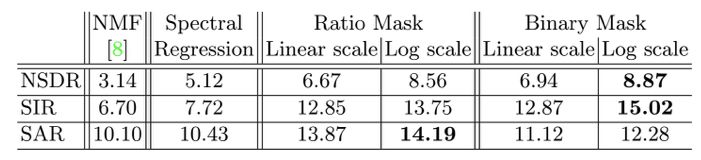
如表1所示,在所有的模型中,NMF通过使用音频和真实的标签来进行源分离。其余的模型都是基于和我们所描述框架相同的深度学习的,通过输入的视频和音频来进行模型学习。光谱回归是指基于输入的混合语谱图,直接通过回归输出语谱图的值,而非输出语谱图的掩码值。从图中可以看出,二值掩膜的效果最好。
表1
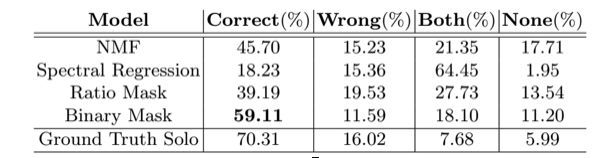
如表2所示,是对声分离性能的主观评价。从表中可以看出基于二值掩膜在声音分离中优于其他模型
表2
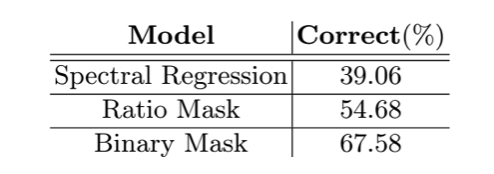
如表3所示,是对视频-声音一致性的主观评价。基于二值掩膜的模型可以最好的地将视觉和声音联系起来。
表3
4.结论
在这篇文章中,我们介绍了PixelPlayer,这个系统可以学习如何对输入的声音进行分离,并在输入的视频中定位对应的发声源。PixelPlayer是在MUSIC这个数据集上训练的,它收集了与乐器相关的大量的无标签视频。通过使用定量、定性的结果和主观的用户研究,证明了我们的多模态学习系统的有效性。希望我们的工作能够开辟新的研究途径,通过视觉和听觉信号来理解声音源分离的问题。
精彩回顾
2018新智元产业跃迁AI技术峰会圆满结束,点击链接回顾大会盛况:
爱奇艺 http://www.iqiyi.com/l_19rr3aqz3z.html
腾讯新闻 http://v.qq.com/live/p/topic/49737/preview.html
新浪科技 http://video.sina.com.cn/l/p/1722511.html
云栖社区 https://yq.aliyun.com/webinar/play/419
斗鱼直播 https://www.douyu.com/432849
天池直播间 http://t.cn/RnQPhuY
IT大咖说 http://www.itdks.com/eventlist/detail/199



