MIT设计跨模态系统,让模型“听音识图”
最近,麻省理工学院的计算机科学家们提出了一种系统,基于对图片的语音描述,可以学习在图片中辨认目标物体,给定一张图片和音频解释,模型可以实时辨认出音频描述的相关区域。
与现有的语音识别技术不同,该模型不需要对其训练的样本进行手动标注,而是模型直接从录音中学习单词,并从原始图片中学习目标物体,将它们相互连接。
目前,模型仅仅可以辨认几百个不同的单词和目标物体类别,但是研究者希望,未来他们的这种语音和目标辨认相结合的技术可以节约大量手工劳动,为语音辨认和图像识别打开新的世界。
像Siri之类的语音识别系统需要对上千小时的录音进行转译。用这些数据,系统学会将语音信号映射到具体的单词上。但一旦词汇中出现了新术语,这种方法就不管用了,系统就要重新训练。
计算机科学和人工智能实验室(CSAIL)的研究者,David Harwath表示:“我们想用一种更自然的方法进行语音识别,使用人类常用的信号和信息来训练。但是那样的机器学习算法并不容易获取。我们想到了一种类似教小孩走路并叙述自己所看到的景象的方法。”Harwath曾参与发表了一篇论文,论文中的模型在最近的计算机视觉欧洲会议上进行了展示。
在上述论文中,研究人员用一张图片展示了他们的模型,图片上有一位年轻的金发小女孩,她有一双蓝色的眼睛,穿着蓝色的连衣裙,背景中有一座白色灯塔,灯塔的顶部是红色的。模型会学习图片中的哪些像素与小女孩有关,例如哪些是“女孩”、“金发”、“蓝眼睛”、“蓝裙子”等等。随着音频的播放叙述,模型会在图片上对这些区域进行高亮。

其中一种有前景的应用就是在两种不同的语言之间进行装换,无需双语标注器。全世界大约有7000种语言,只有100种左右有足够的数据进行语音识别。但是,是否有这样一种情景,当两种说着不同语言的人描述同一幅图画呢?如果模型学会语言A所描述的语言信号所对应的图中物体,同时也学会了B所描述的同样物体,那么它就能将这两种信号看作是彼此的翻译版本。
Harwath说表示,这有助于解决神话故事中的“巴别塔”问题。
音频-视觉联系
这项工作是Harwath等人早期一项研究的扩展,他们当时研究将语音与相关主题的图片相连接。在早期研究中,他们从Mechanical Turk平台的分类数据集中选择不同场景的图片,之后让人对图片进行描述,就像给小孩子讲故事,录制大约10秒钟的视频。他们收集了20多万份图片和与之对应的音频注解,分成了上百种不同类别,例如沙滩、购物广场、城市街道、卧室等等。
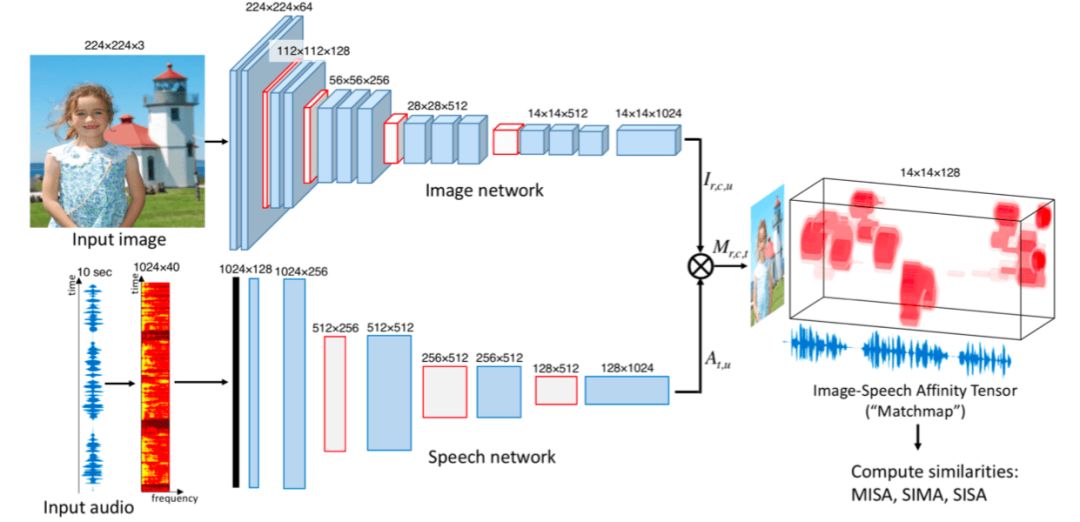
之后,他们设计了一款模型,由两个独立的卷积神经网络构成。其中一个处理图像,另一个处理光谱(音频信号的视觉表示)。模型的最高层会计算两个网络的输出,并将语音模式映射到图片数据上。
例如,研究者会A注释输入到图片A中,这是相对应的。之后又会随机选择一个注释B输入到图片A中,这就是错误的配对。经过对比上千种错误的陪读,模型学会了与图片A相对应的语音信号,然后将这些信号和注释中的单词联系起来。正如2016年一份研究中所描述的,模型学会了表示“water”这个词的语音信号,然后检索出了所有带水的图片。
但是Harwath表示,这并不能证明当某人说出特定单词时就指的是某个像素。
matchmap
在新的论文中,研究人员对之前的模型进行了修改,将特定词语和特定的像素补丁联系在一起。研究人员在同样的数据集上训练模型,但是最终共有40万个图片注释对子,他们从中随机选取了1000对用作测试。
在训练时,模型像上述那样给予不同的注释,但这次,分析图片的卷积神经网络将图片用网格分成不同的部分,每个单元都有对应的像素补丁。分析音频的卷积神经网络将声谱也分成不同片段,也就是说一秒钟可能会有一到两个单词。
在正确的图片和注释对子下,模型会将第一个图片网格与第一段音频对应起来,然后将同样的图片网格与第二段音频对应,如此下去。对每个网格和音频片段,模型都会给出一个相似度分数,表示音频信号与目标物体的相似程度有多少。
但其中的难题是,在训练过程中,模型并不知道音频和图片对应的标准是什么。所以这篇论文最大的贡献就是,它通过教网络哪些图片和注释是同属一类,而哪些不是,就能自动推断这些跨形态连接。
论文作者将语音和图片像素之间的联系称作“matchmap”。训练了数千对图片和注释对子之后,网络会在matchmap中主线缩小与词语相对的目标物体。
论文的写作者Florian Metze说:“很高兴看到这种神经方法连接起图片元素和音频片段,并且不用文本作为中间工具。这并非是模仿热泪学习,而是完全基于彼此之间的连接。这也许能帮助我们理解,通过音频和视频线索如何形成视觉表示。机器翻译是一种应用,但它也能用于对濒危语言的记录上。我们也可以想象如何将这种技术应用到废除刘的语音中,或者残障人士身上。”
原文地址:news.mit.edu/machine-learning-image-object-recognition-0918
论文地址:arxiv.org/pdf/1804.01452.pdf






