Transformer中的相对位置编码

最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,本文是这个系列的第二十二篇,需要前面文章的同学点击链接进入文章列表。
Overall
今天看一篇稍微简单的知识,那就是相对位置编码,虽然知识内容比较简单,但是确是Transformer中不可或缺的一个知识点。
最初是的Transformer使用的是三角函数进行位置编码,生成的都是固定的编码。这些固定编码被当做位置编码传送给模型。
这些固定的编码有两个缺点:
-
固定,所以capacity可能不如学习到的embedding大。 -
无法发现相对关系,假设A和B有相关关系,A和B的相对位置不变,但绝对位置发生了变化,那么用固定编码则无法发现这个关系。
回顾Transformer
在Transformer中,经过attention层的值计算方式如下:
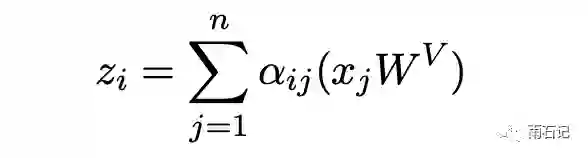
其中αij是权重,计算方式:
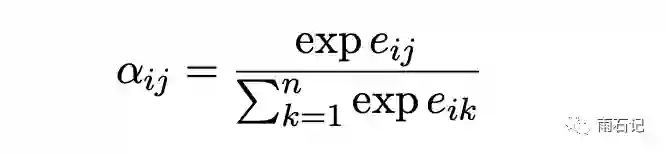
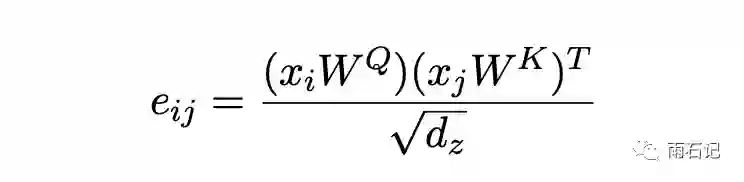
上面三个公式和原始的Transformer中的公式是等价的。
相对位置编码
相对位置编码为每个不同的位置对都定义了两个向量,分别是αijV和αijK。在计算的时候,将上面的公式进行修改。
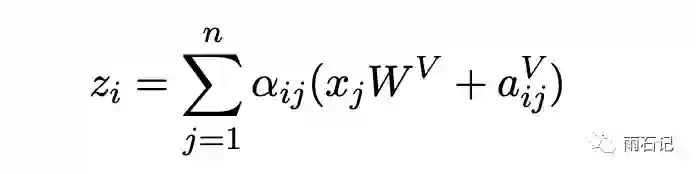
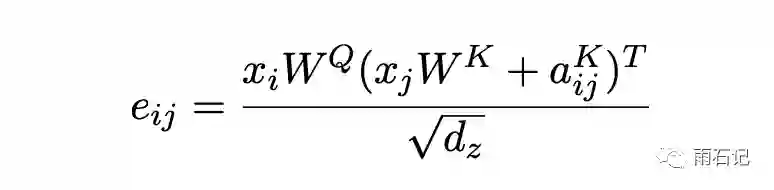
为每个位置对定义两个向量还是无法完成提取相对位置信息的,而且,空间复杂度也是N^2,所以,为了泛化和节省时间复杂度,将每个位置对用位置的差来代替。
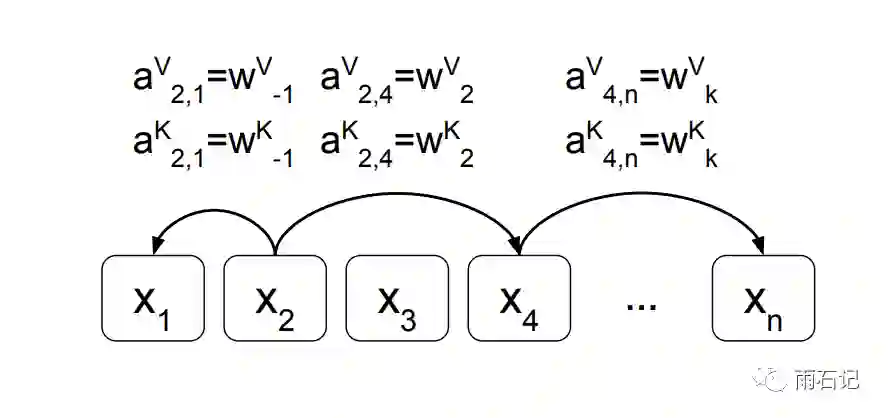
对应的公式如下:
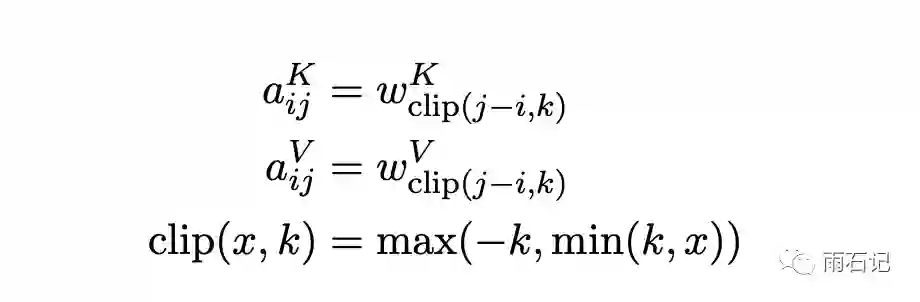
k对应着窗口大小,超过窗口就按照窗口最远的那个值进行计算。
实验效果

在翻译任务上,尤其是EN-DE上效果有明显的提升。
Bert系列计划写50篇相关文章,欢迎感兴趣的同学关注公众号【雨石记】
参考文献
-
[1]. Shaw, Peter, Jakob Uszkoreit, and Ashish Vaswani. "Self-attention with relative position representations." arXiv preprint arXiv:1803.02155 (2018).
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




