CVPR 提前看:视觉常识的最新研究进展
机器之心分析师网络
作者:仵冀颖
编辑:Joni Zhong
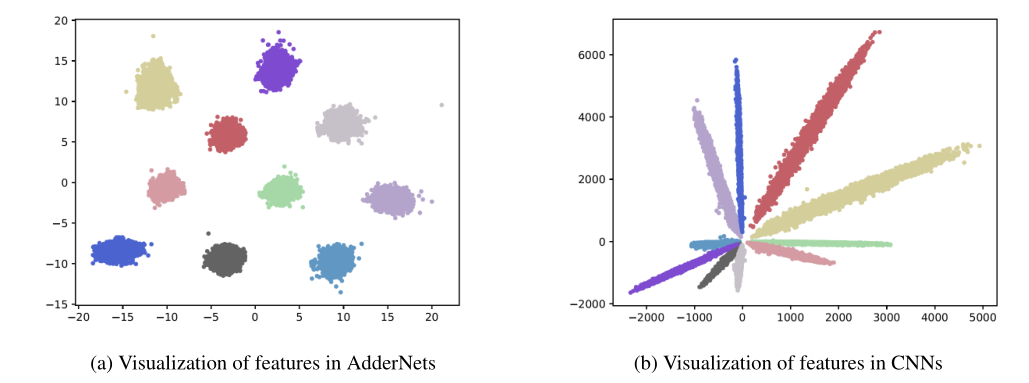
2020 年 CVPR 将于 6 月 13 日至 19 日在西雅图举行。今年的 CVPR 有 6656 篇有效投稿,最终录用的文章为 1470 篇,接收率为 22%。作为计算机视觉三大顶会之一,CVPR 今年的论文方向依然为目标检测、目标跟踪、图像分割、人脸识别、姿态估计等等。CVPR 是老牌的视觉、图像和模式识别等研究方向的顶会,本篇提前看中,让我们在人工智能、深度学习热潮的冲击下,一起关注一下视觉常识的最新研究进展。


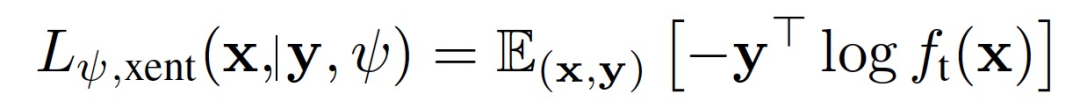
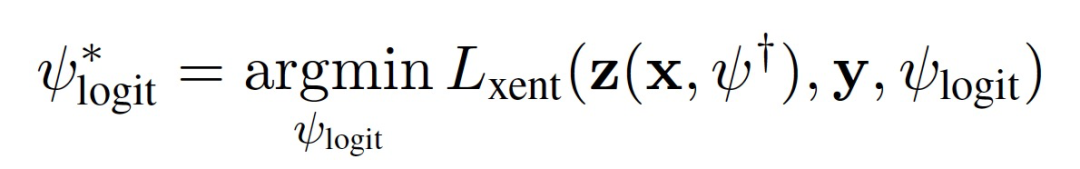
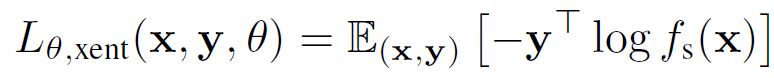
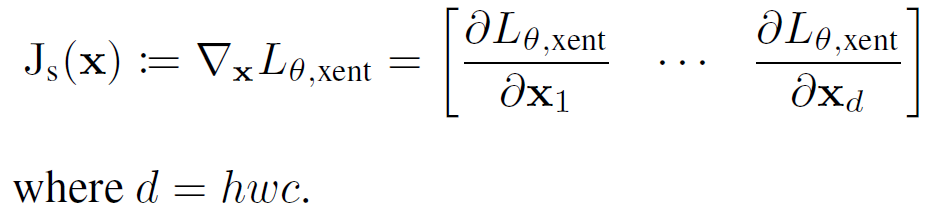
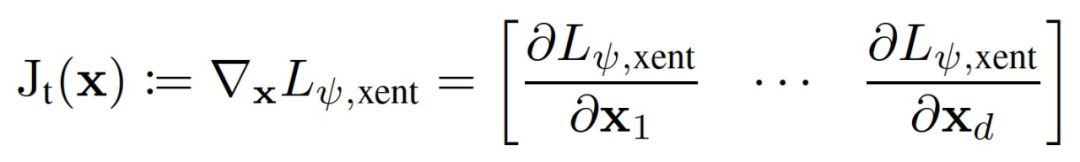
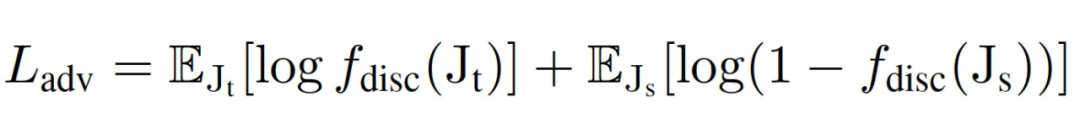
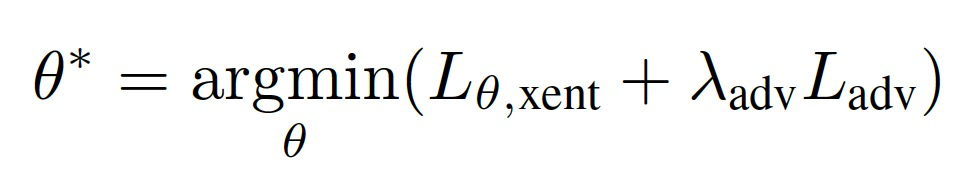
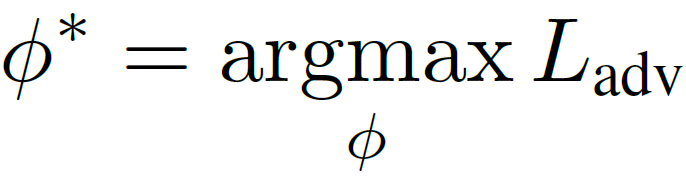
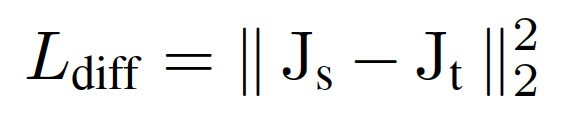
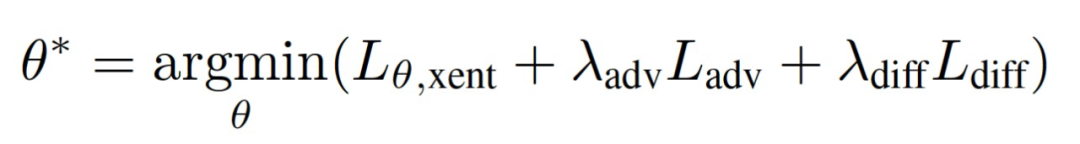
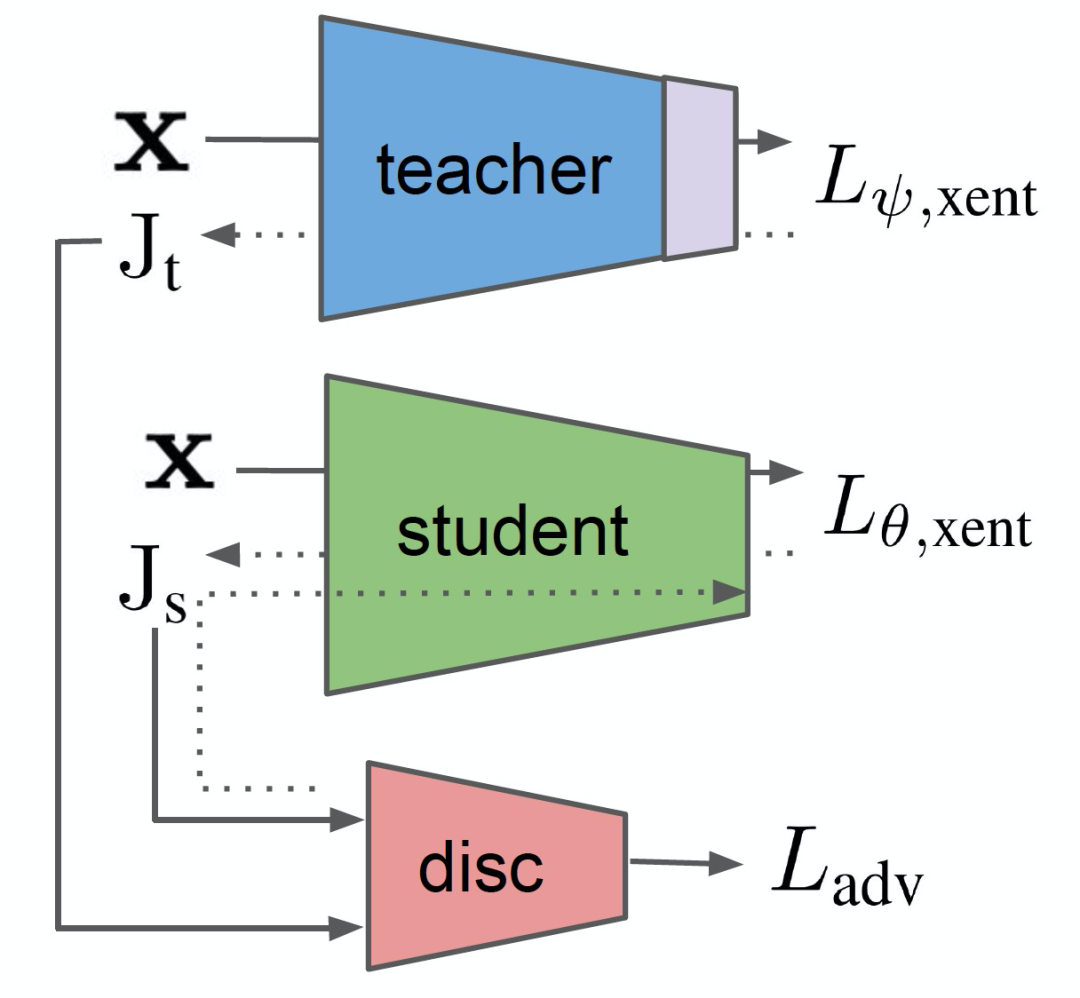


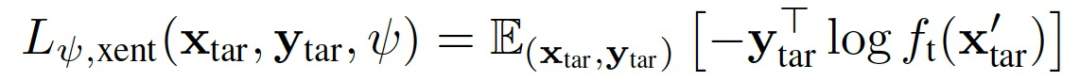



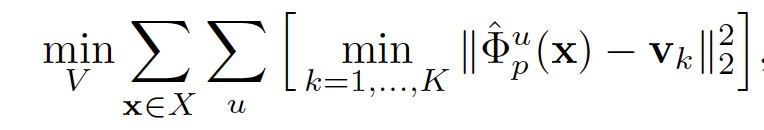
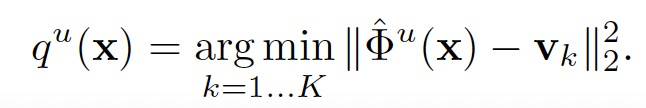
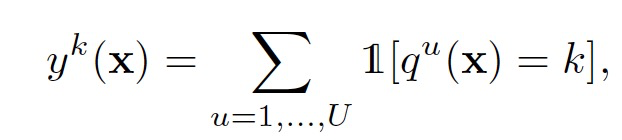
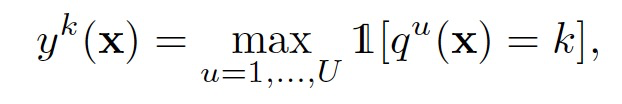

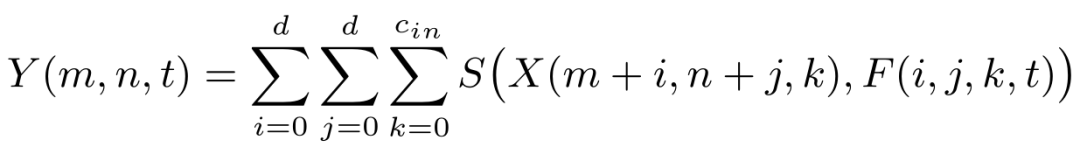
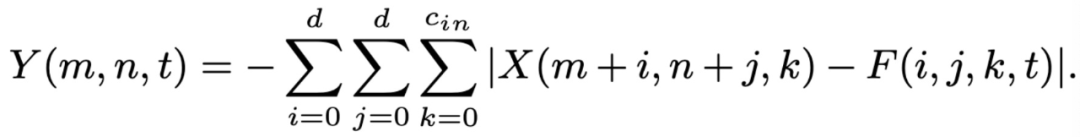
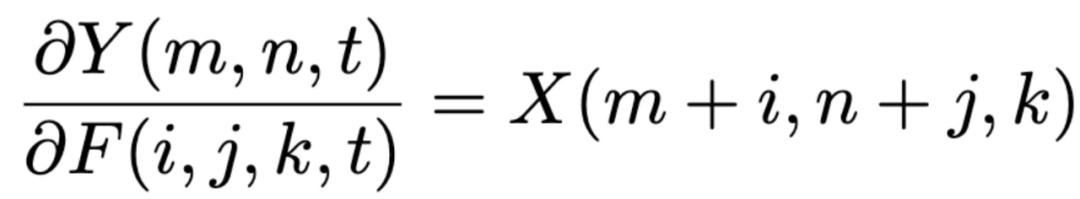
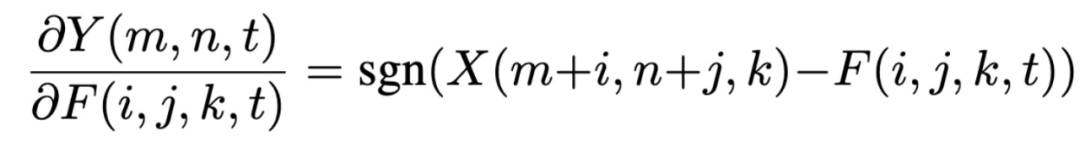
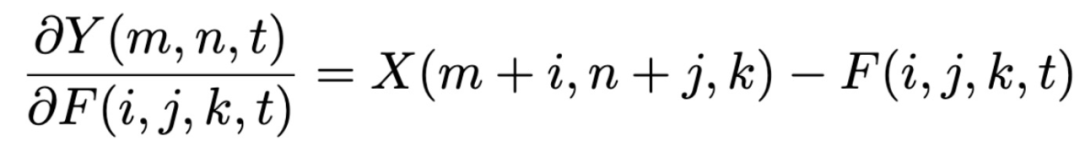
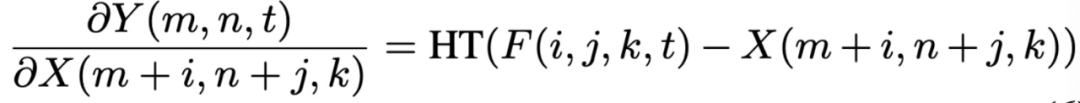
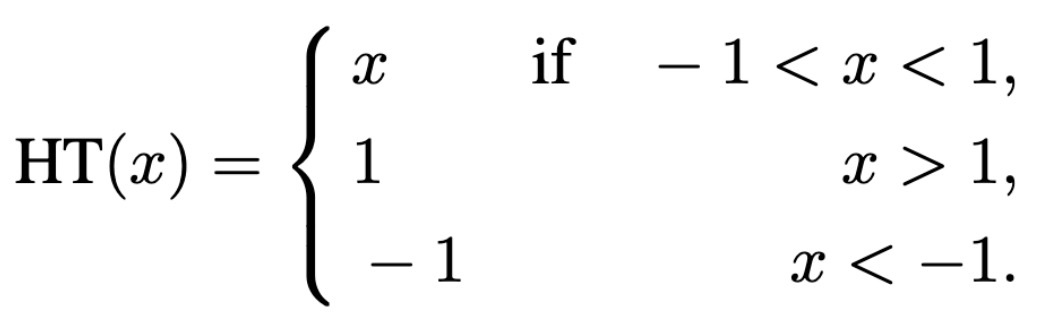

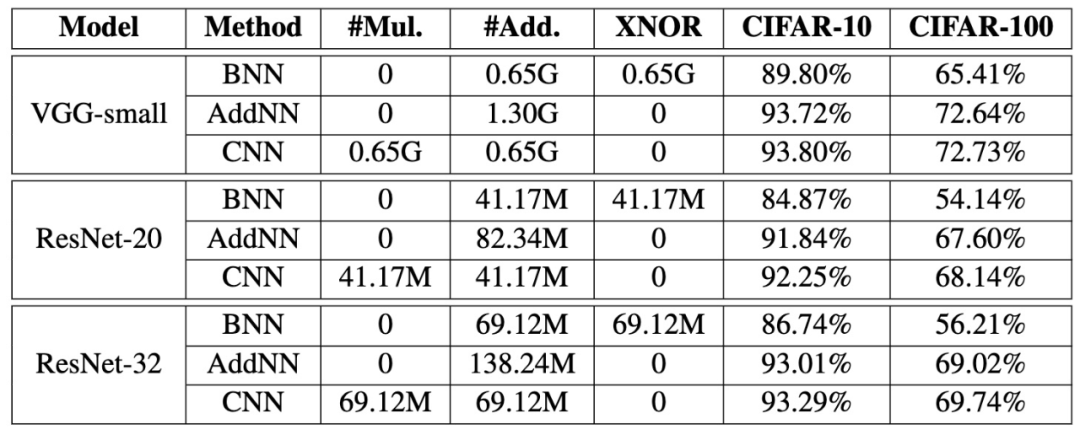
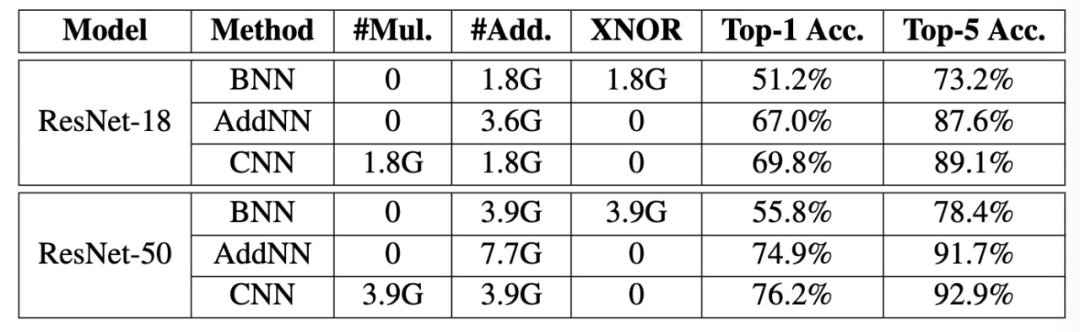
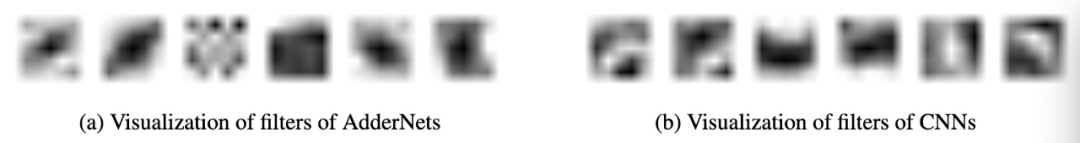
登录查看更多
相关内容

Arxiv
20+阅读 · 2019年12月19日


相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2019年12月19日